

中秋节前夕,马上就要准备放假回家去畅游王者峡谷的小涛收到了报警,某mq消息积压几十万而且正在一直往上涨,看了下依赖的接口和hbase无问题,发现mysql读写速度很慢,于是乎看了下mysql机器负载,cpu高达百分之85,使用showprocesslist,查询当前运行的sql,发现并没有很慢的sql,但是发现有如下sql在大量执行,
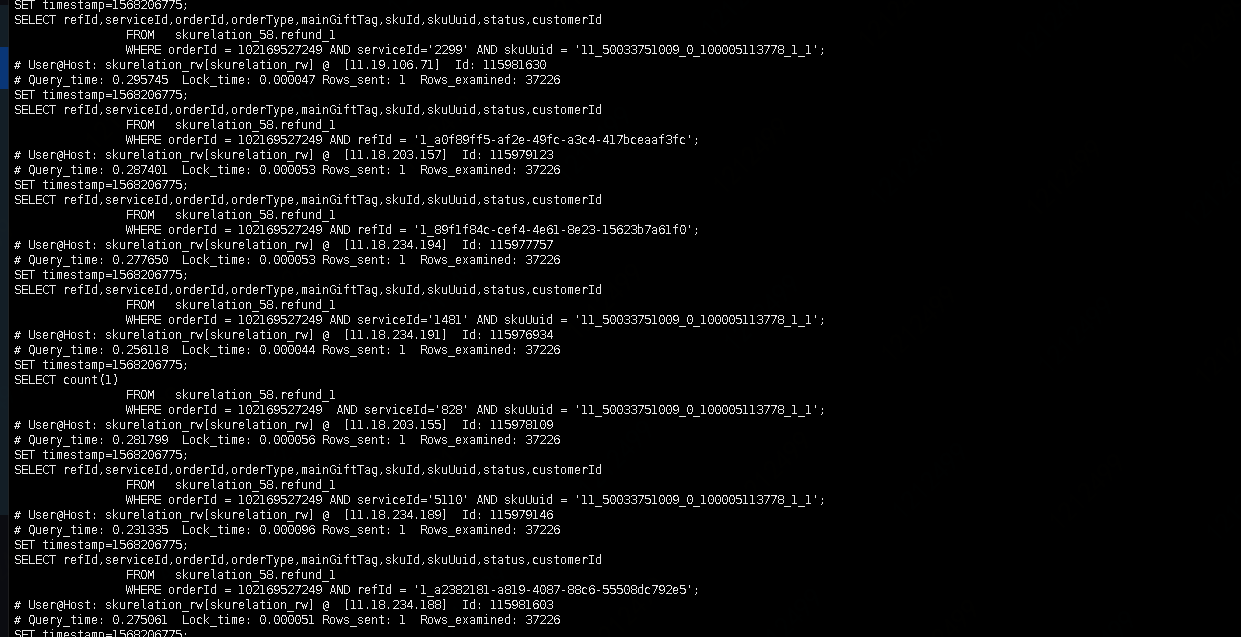
但是查询速度并不是很慢,根据订单号去查了一下该订单商品,发现此订单买的商品是买1赠5,可怕的是这个人买了1万套,对于这样的场景业务上会存5万条数据作为主赠关系,说白了,就是消费这个订单的消息时,要去查询5万次。由于消费mq超时时间只有3秒,没等5万次查询完成去做业务处理就超时了,然后消息进行重试,又被其他实例消费,继续查询5万次,查询了下该表索引,发现只有orderId 这个字段有索引,所有查询其他字段的时候还要扫表,导致cpu升高,读写变慢,消息积压,临时方案,修改了下mq超时时间,放次消息消费过去,然后开始着手,重新建索引,然后就有了如下的分析。
这张表除了这个查询语句以外,还有查询条件为(orderId,serviceId),(orderId,skuUuid)的语句,那么如何建索引才更合理呢,
初始版本一个联合索引(orderId,serviceId,skuUuid),但是在(orderId,skuUuid)时skuUuid无法使用索引,依然会有之前的问题,第二个版本建2个联合索引(orderId,serviceId, skuUuid),(orderId, skuUuid)这样可以都使用到索引了。那么问题来了,为什么索引要有最左前缀,为什么中间少了一个字段后面的就不能使用索引了呢?
比如原表中的数据是这样的:
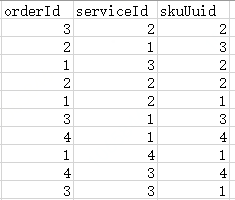
建立了(orderId,serviceId,skuUuid)复合索引之后,索引文件数据应该是这样的:
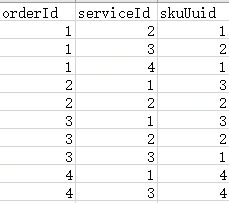
从全表来看orderId是有序的,而serviceId和skuUuid是相对有序的,所以如果没有orderId,直接访问serviceId或skuUuid,那肯定是无序的,所以也就用不到索引了,所以联合索引就类似于闯关一样,要一关一关的来,断开则后面的都无法使用到索引。
留下几个感觉比较好的链接已备后面复习,大家也可以看看。
