

前言
本篇文章是笔者精读 the-super-tiny-compiler 的源代码后的总结,笔者特别推荐大家去读,否则看此篇文章容易一头雾水。
首先,建立对 ast 抽象语法树的初步了解,大家可以在 astexplorer 这个网站上输入一段 javascript 代码,在右侧面板中查看生成的 ast 语法树。
比如输入 add(3, div(8, 2)) (解析器默认挑选了 acorn))解析出来的抽象语法树 ast 如下右侧:
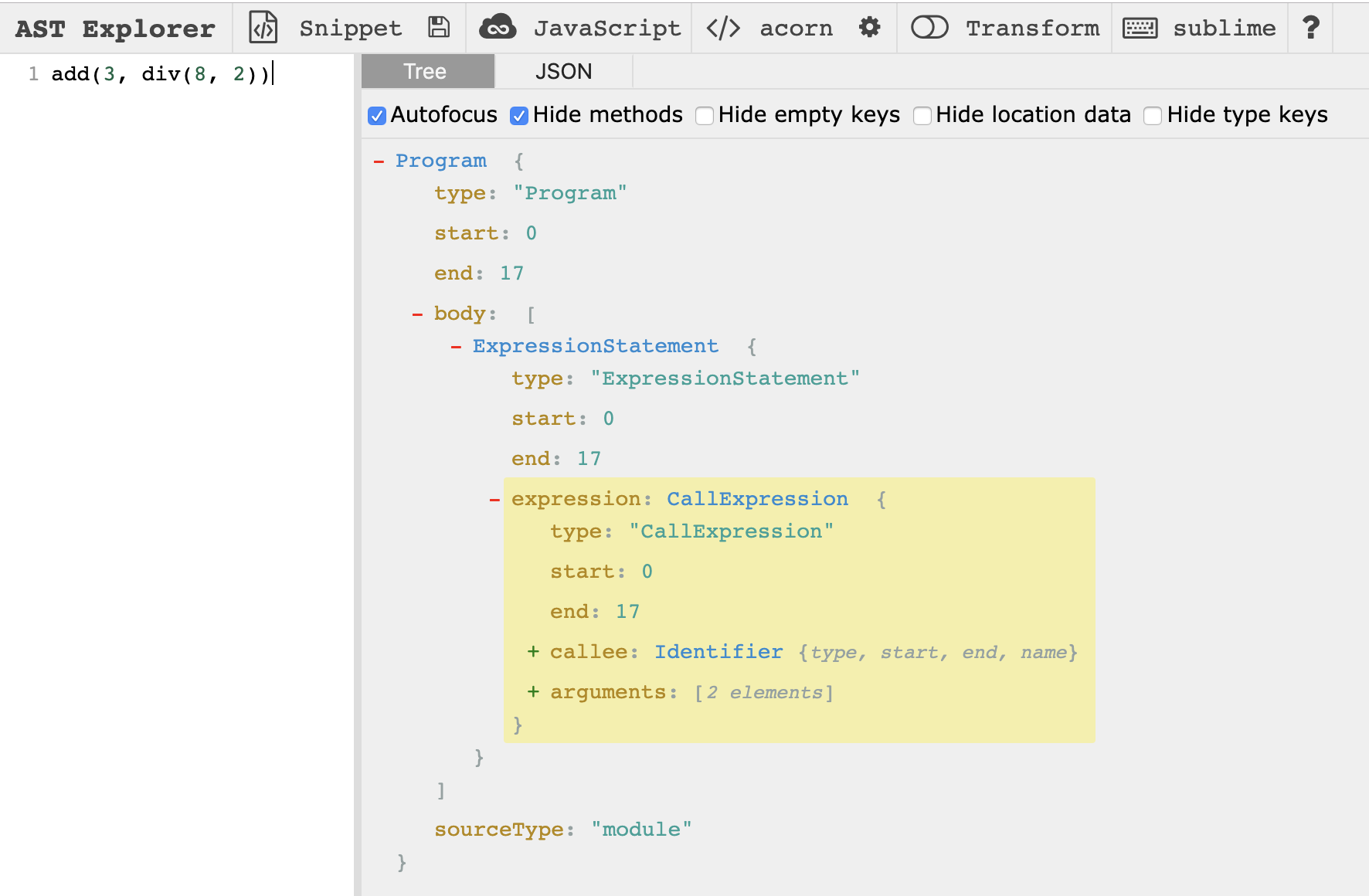
这可能是 ast 目前给大家最直观的印象。以下将用图解介绍如何从一句简单的源代码(haskell),通过编译、生成、分析 ast,转换成新的语言(javascript)。
背景
首先,作为一个前端工程师,笔者觉得了解编译原理,有以下几个好处:
- 编译原理的确是一个很有趣的知识,学习一下纯当爱好。
- 多了解相关的编译知识,有助于加深对编程语言的理解。
- 扩展开来,对 javascript 转译、代码压缩、eslint、css 预处理器、prettier 等工具的理解和使用都会有帮助。
目标
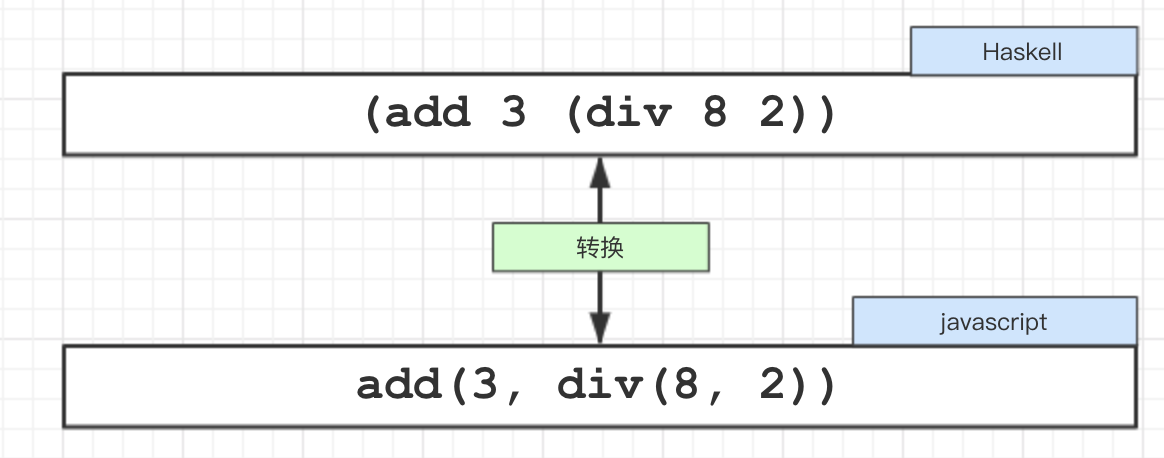
本文的目标,将一段 haskell 语法的代码通过自制的小型编译器编译后解析为 javascript 语法的代码。如下:
const input = "(add 3 (div 8 2))";
const output = "add(3, div(8, 2))";
编写一个函数 compiler 使得 input 转换为 output, 示意图如下:
那么我们一般对程序编译会走经过几个过程呢?一般来说,简单可分为词法分析,语法分析和代码生成三步。以下将会补充描述。
词法分析 - Tokenizer
词法分析,目标将一段代码分割成一个个的单词和标点符号。
词法分析的函数也叫做扫描 scanner。扫描器读取代码后,依据预定的规则合并生成成一个个的标识 tokens(移除空白符,注释)。生成 tokens 列表。
示意图如下:
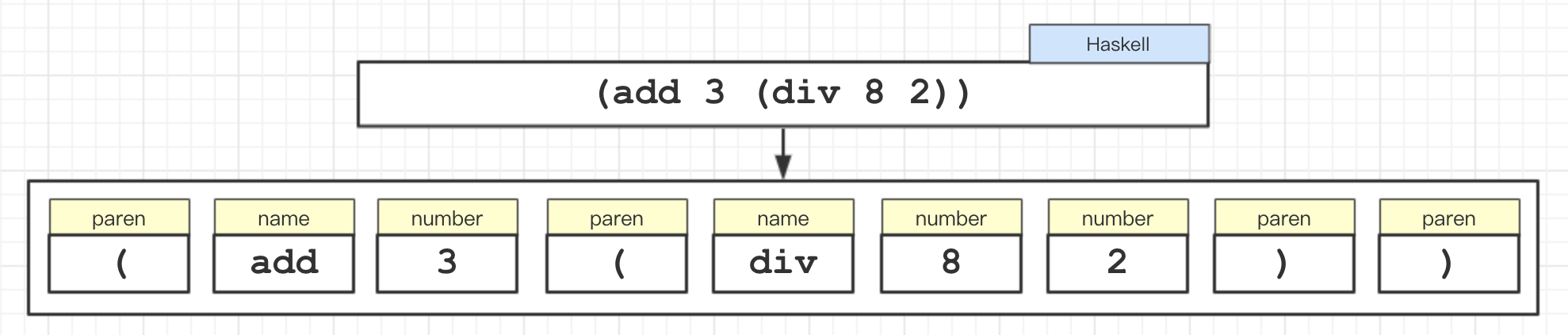
数据结构如下:
[
{ type: "paren", value: "(" },
{ type: "name", value: "add" },
{ type: "number", value: "3" },
{ type: "paren", value: "(" },
{ type: "name", value: "div" },
{ type: "number", value: "8" },
{ type: "number", value: "2" },
{ type: "paren", value: ")" },
{ type: "paren", value: ")" }
];
语法分析 - Parser
语法分析,主要目的在于通过分析词法分析生成的词法单元流,构建出一个代表当前程序的抽象语法树 ast。
由上面的 tokenizer 进行分词后,其实并没有表达出语法。此时需要设计一个 parser 将 tokens 转换为 ast。parser 指针将逐个解析 token,在以上简化的 tokens 列表中,parser 在解析到左括号 "(" 此 token 时,进入递归,只要下一个 token 不是右括号 ")",就不会结束递归。
最终指针移至 tokens 列表尾部,消费完成所有 tokens,此时生成完整的 ast。
示意图如下:
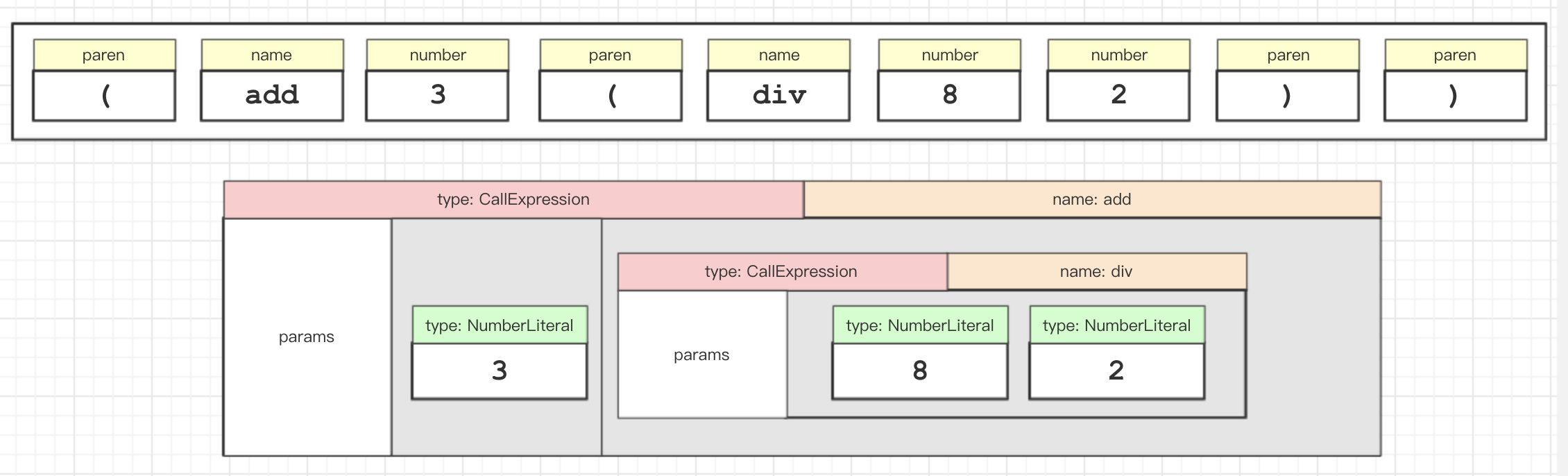
数据结构如下:
{
"type": "Program",
"body": [
{
"type": "CallExpression",
"name": "add",
"params": [
{
"type": "NumberLiteral",
"value": "3"
},
{
"type": "CallExpression",
"name": "div",
"params": [
{
"type": "NumberLiteral",
"value": "8"
},
{
"type": "NumberLiteral",
"value": "2"
}
]
}
]
}
]
}
因此,通过递归生成了以上的 CallExpression 嵌套的模块。
代码转换 - Transformer
这里主要的工作,通过语法映射,将 haskell 的抽象语法树转成 javascript 的抽象语法树。这里有一个很重要的概念就是 traverser。这是一个可以通过匹配类型从而遍历访问 ast 某个节点的工具函数。
traverse(ast, {
Program: {
enter(node, parent) {
// ...
},
exit(node, parent) {
// ...
}
},
CallExpression: {
enter(node, parent) {
// ...
},
exit(node, parent) {
// ...
}
},
NumberLiteral: {
enter(node, parent) {
// ...
},
exit(node, parent) {
// ...
}
}
});
traverse 的第一个参数是 ast,第二个参数我们称作 visitor(访问器)。我们定义了每个 type 的 visitor。在 traverse 递归遍历每个节点的时候,都会在对应的时机执行 enter、exit 回调函数。
有了上述的 traverse 工具后,我们可以在访问每个节点的时候,不断生成、并调整我们的新语法树。
最终经过 transformer 转换后的 javascript 的 ast 语法树数据结构如下:
{
"type": "Program",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "CallExpression",
"callee": {
"type": "Identifier",
"name": "add"
},
"arguments": [
{
"type": "NumberLiteral",
"value": "3"
},
{
"type": "CallExpression",
"callee": {
"type": "Identifier",
"name": "div"
},
"arguments": [
{
"type": "NumberLiteral",
"value": "8"
},
{
"type": "NumberLiteral",
"value": "2"
}
]
}
]
}
}
]
}
代码生成 - Generator
代码生成器主要的职责是将转换后的 ast 通过特定规则组合为新的代码。
在得到通过 transformer 转换后的新语法树后,代码生成器同样递归的调用自己打印 ast 中的每一个节点,最终生成一个长长的代码字符串。也就是我们目标的:output。
小结
笔者对编译原理了解不多,此文兴趣所致,描述有可能不甚严谨。以后如有机会学习深入编译原理,会继续发文补充。
以上,对大家如有助益,不胜荣幸。
