

全文共4109字,预计学习时长8分钟

从在线API中提取股票价格数据,使用配备有TensorFlow.js框架的递归神经网络和长期短期记忆(LSTM)执行预测。
机器学习近年来深受欢迎,越来越多的人把它当作一个能够预测未来时间和特定事件的神奇水晶球。该实验使用人工神经网络揭示股市走势,揭示了使用过去的历史数据来预测未来股票价格的能力,即时间序列预测能力。
注意!!!由于多重因素,股票市场波动不断变化且不可预测。该实验完全基于教学目的,切不可当作交易预测的工具。

项目演练
该项目演练分为4个部分:
1. 从在线API提取股票数据
2. 计算给定时间窗口的简单移动平均值
3. 训练LSTM神经网络
4. 预测并比较预测值与实际值
获取股票数据
在训练神经网络并进行预测之前,首先需要数据。查找的数据类型按照时间序列,即按时间顺序排列的数字序列。可以从alphavantage.co上获取数据。API能够按照时间顺序检索过去20年中特定公司股票价格的数据。
API会生成以下字段:
- 开放价格
- 当天的最高价
- 当天的最低价
- 收盘价(仅限本项目)
- 交易量
为准备神经网络的训练数据集,将使用收盘股票价格。这也意味着本次的目标是预测未来的收盘价。
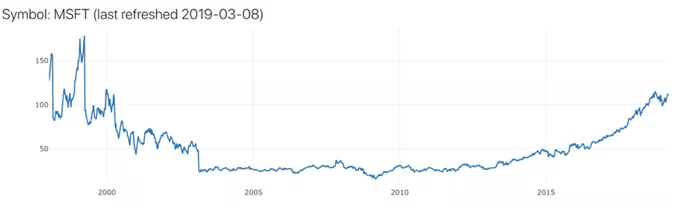
简单移动平均线
本次实验将使用监督学习,这意味着将数据输送到神经网络,并通过把输入数据映射到输出标签来进行学习。准备训练数据集的一种方法是从该时间序列数据中提取移动平均值。
简单移动平均线(SMA):该方法可以通过查看该时间窗内所有值的平均值识别特定时间段的趋势方向。该时间窗口的价格数量根据实验需要进行选择。
例如,假设过去5天的收盘价是13,15,14,16,17,SMA将是(13 + 15 + 14 + 16 + 17)/ 5 = 15.所以输入的训练数据集即为单个时间窗口内的价格集,其标签值为这些价格的计算移动平均值。
计算一下微软公司每周收盘价数据的SMA,窗口大小为50。
functionComputeSMA(data,window_size)
{ let r_avgs = [], avg_prev = 0;
for (let i = 0; i <=data.length - window_size; i++){
let curr_avg = 0.00, t = i +window_size;
for (let k = i; k < t && k <=data.length; k++){
curr_avg += data[k]['price'] / window_size;
}
r_avgs.push({ set: data.slice(i, i +window_size), avg: curr_avg });
avg_prev = curr_avg;
}
return r_avgs;
}以上即为得到的结果,每周股票收盘价为蓝色,SMA为橙色。因为SMA是50周的移动平均线,所以它比每周价格更平滑,每周价格可能会波动。
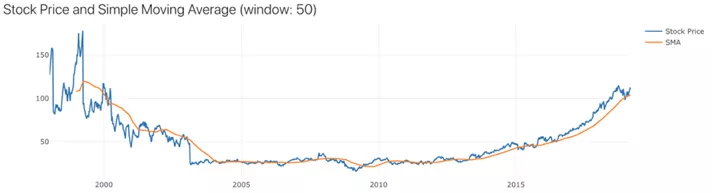
数据训练
可以使用每周股票价格和计算得出的SMA来准备数据训练。鉴于窗口大小为50,这意味着将使用连续50周的收盘价作为训练功能(X),并将这50周的SMA作为培训标签(Y)。
接下来,将数据分为2组,即训练集和验证集。如果70%的数据用于培训,则30%的数据用于验证。如果API返回大约1000周的数据,则700周的数据用于培训,300周的数据用于有效性验证。
列车神经网络
现在数据训练已准备就绪,可以为时间序列预测创建一个模型。为实现这个目的,将使用TensorFlow.js框架。TensorFlow.js是一个用JavaScript开发和训练机器学习模型的库,可以在Web浏览器中部署这些机器学习该功能。
选择顺序模型,简单地连接每个层,并在训练过程中将数据从输入传递到输出。为了使模型学习顺序的时间序列数据,创建递归神经网络(RNN)层并且将多个LSTM单元添加到RNN。
该模型将使用Adam(研究论文)进行训练,这是一种流行的机器学习优化算法。均方根误差将决定预测值与实际值之间的差异,因此模型能够通过最小化训练过程中的误差进行学习。
下面是上述模型的代码片段。
asyncfunctiontrainModel(inputs,outputs, trainingsize, window_size,
n_epochs, learning_rate, n_layers, callback){
const input_layer_shape = window_size;
const input_layer_neurons = 100;
const rnn_input_layer_features = 10;
const rnn_input_layer_timesteps =input_layer_neurons /
rnn_input_layer_features; const rnn_input_shape = [rnn_input_layer_features,rnn_input_layer_timesteps]; const rnn_output_neurons = 20; const rnn_batch_size = window_size; const output_layer_shape = rnn_output_neurons; const output_layer_neurons = 1; const model = tf.sequential(); let X = inputs.slice(0, Math.floor(trainingsize/ 100 *inputs.length)); let Y = outputs.slice(0, Math.floor(trainingsize/ 100 *outputs.length)); const xs = tf.tensor2d(X, [X.length, X[0].length]).div(tf.scalar(10)); const ys = tf.tensor2d(Y, [Y.length, 1]).reshape([Y.length,1]).div(tf.scalar(10)); model.add(tf.layers.dense({units:input_layer_neurons, inputShape: [input_layer_shape]})); model.add(tf.layers.reshape({targetShape:rnn_input_shape})); let lstm_cells = []; for (let index = 0; index< n_layers; index++) { lstm_cells.push(tf.layers.lstmCell({units: rnn_output_neurons})); } model.add(tf.layers.rnn({ cell: lstm_cells, inputShape: rnn_input_shape, returnSequences: false })); model.add(tf.layers.dense({units:output_layer_neurons, inputShape: [output_layer_shape]})); model.compile({ optimizer: tf.train.adam(learning_rate), loss: 'meanSquaredError' }); const hist = awaitmodel.fit(xs, ys, { batchSize: rnn_batch_size, epochs:n_epochs, callbacks: { onEpochEnd: async (epoch,log) => { callback(epoch, log); } } }); return { model: model, stats: hist };}
这些是可用于在前端进行调整的超参数(在训练过程中使用的参数):
- 数据训练集大小(%):用于训练的数据量,剩余数据将用于验证
- 次数:数据集用于训练模型的次数(了解更多)
- 学习率:每个步骤中训练期间的权重变化量(了解更多)
- 隐藏的LSTM图层:增加模型的复杂性,以便学习
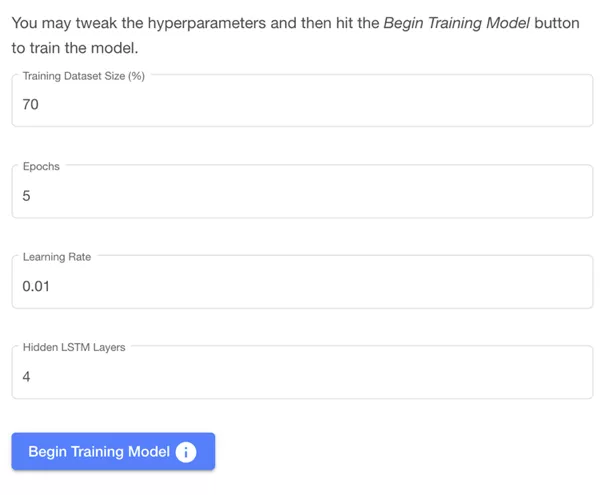
单击“开始训练模型”按钮…
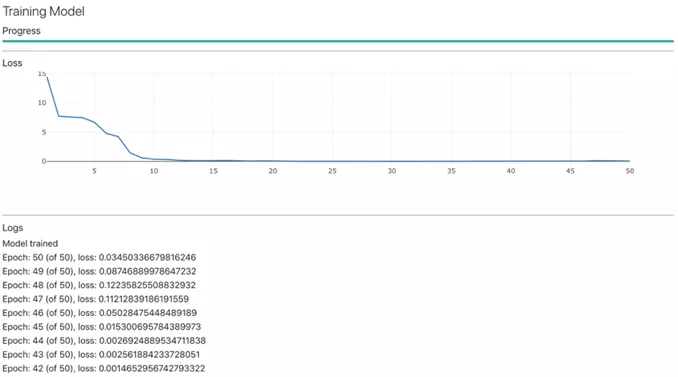
验证
现在模型已经过训练,可以用来预测未来值,在此情况中,模型是一条移动的平均线。我们将使用TFJS model.predict函数。
把数据分为2组,培训集和验证集。训练集已用于训练模型,因此将使用验证集来验证模型。由于模型没有看到验证数据集,因此如果模型能够预测近似的真实值,那效果更好。
因此,使用剩余的数据进行预测,这样就可以比较预测值与实际值。
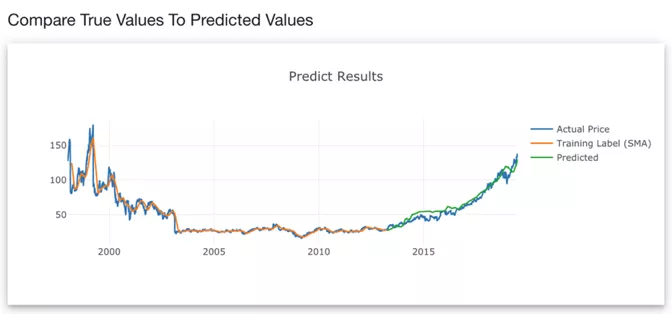
可以看出,模型预测(绿线)紧密重合实际价格(蓝线)。这意味着该模型能够预测模型未预见的最后30%的数据。
可以应用其他算法并使用均方根误差来比较两个或更多模型的性能。
预测
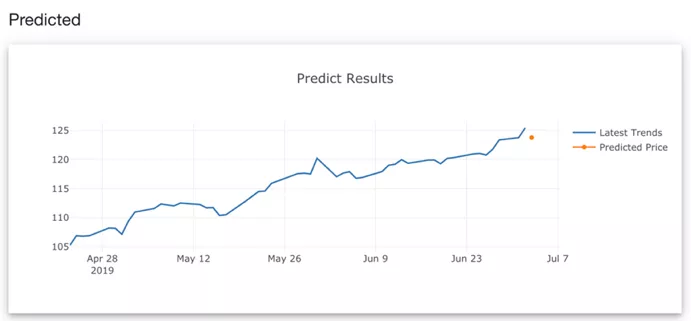
最后,模型已经过验证,预测值与其真实值紧密相关,可以预测未来的数据。将该模型应用于相同的model.predict函数,并使用最后50个数据点作为输入,因为窗口大小为50。由于训练数据每天递增,可以使用过去50天的数据点作为输入,以预测第51天的数据。
结论
除了使用简单的移动平均线之外,还有很多方法可以进行时间序列预测。未来可能使用更多不同源头的数据来实现预测。
使用TensorFlow.js可以在Web浏览器上进行机器学习,这十分神奇。
Github上探索演示:https://jinglescode.github.io/demos/tfjs-timeseries-stocks
Github完整代码:https://github.com/jinglescode/demos/tree/master/src/app/components/tfjs-timeseries-stocks

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)
