

1.下载kaggle/python镜像
-
启动Docker
以管理员方式运行Docker Quickstart Terminal,直到出现如下画面:
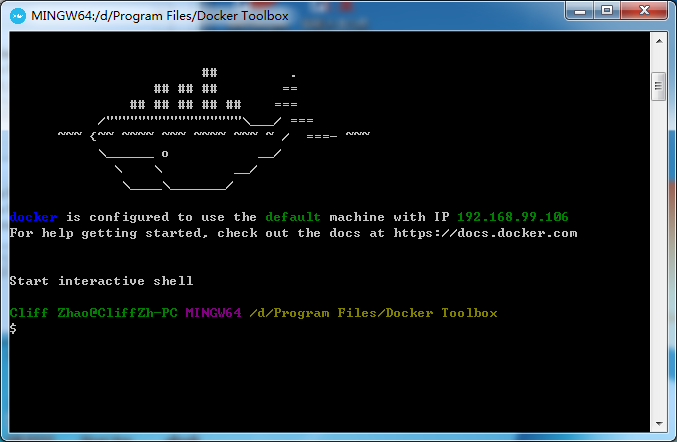
- 下载kaggle/python镜像
输入如下命令:
docker pull registry.cn-hangzhou.aliyuncs.com/kiss_org/kaggle_python
注:这是从阿里容器云下载kaggle/python镜像,并非最新的官方版本,如果想下载最新官方版本,请参考文末的“补充”部分内容。虽然不是最新版,但是可以通过后续容器内对相关软件和库的升级方式,获得最新版本的文本挖掘的相关工具。 镜像大约9.7G,下载需要花点时间,下载完成后进入第2步。
2. 设置kaggle/python镜像容器与本机的交换目录
- 停止docker
在命令行窗口输入命令:
docker-machine stop
出现如下画面,表示docker已经停止

-
在本机上新建一个交换目录
例如:
F:\Python\textmining
-
为交换目录设置虚拟机/容器挂载名称
打开VirtualBox管理器,并选中虚拟机列表中的名称为“default”的虚拟机,点击“设置”按钮
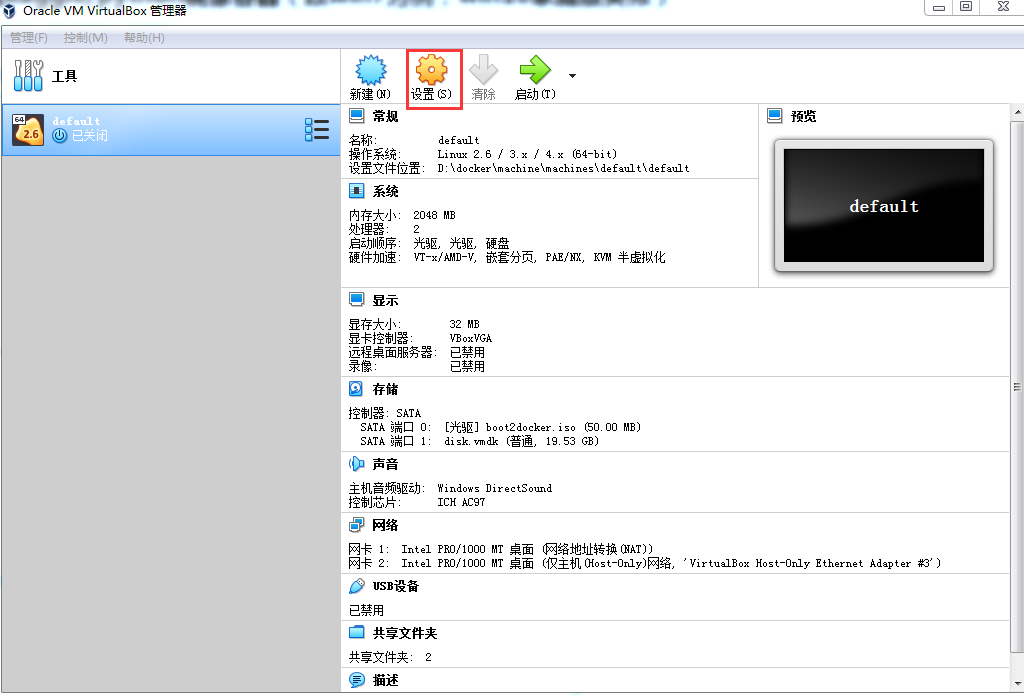
在设置界面里选择“共享文件夹”,并点击“添加”按钮
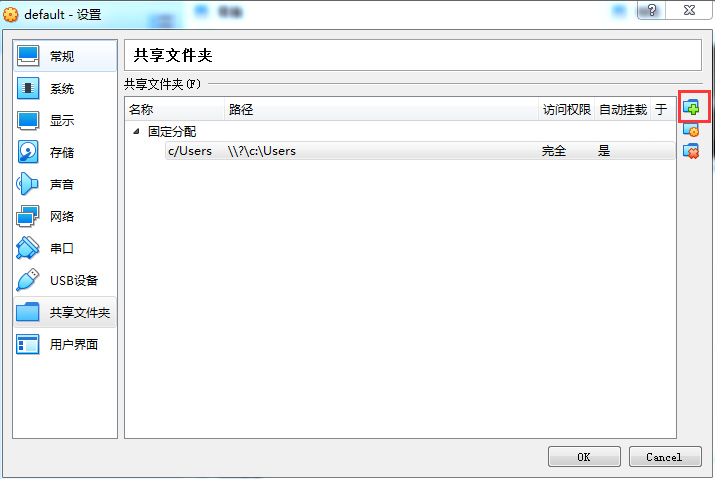
选择之前创建好的目录,选上“自动挂载”,并点击“确定”
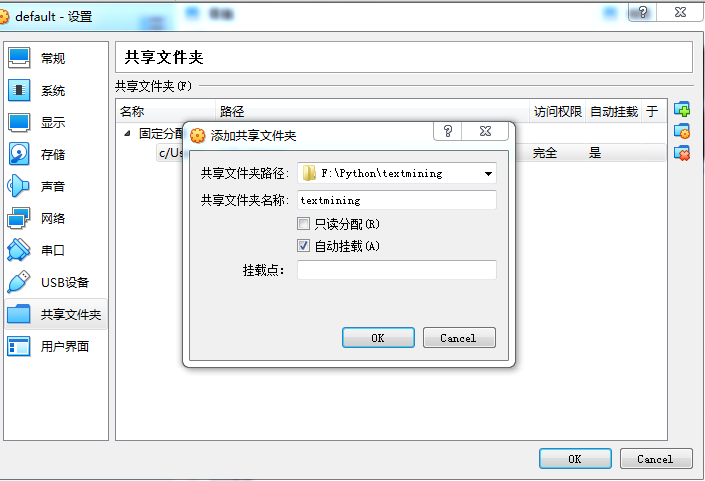
此时,可以看到交换目录已经添加成功,名称为“textmining”
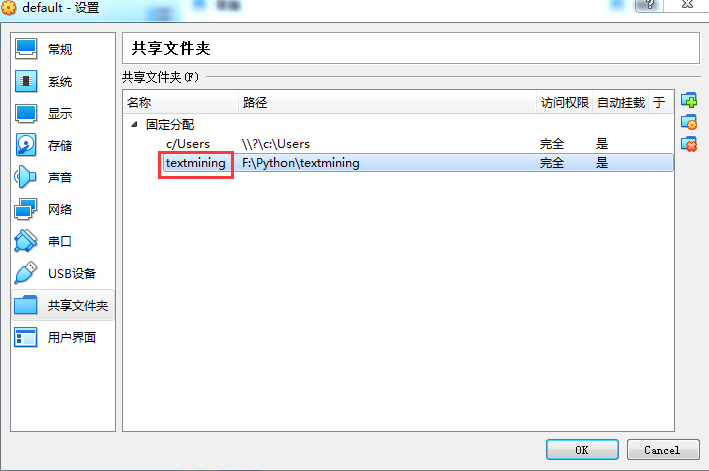
记住这个名称,后面会用到
3. 创建kaggle容器
先启动Docker
以管理员方式运行Docker Quickstart Terminal,直到出现如下画面:
然后,执行命令
docker run --name kaggle -v /textmining:/tmp/working -w=/tmp/working -p 8888:8888 -d -it registry.cn-hangzhou.aliyuncs.com/kiss_org/kaggle_python
命令参数说明:
--name kaggle 表示将容器命名为“kaggle”
-v /textmining:/tmp/working 表示将名称为“textmining”的目录与容器里的“/tmp/working”目录进行绑定,这样“/tmp/working”与“textmining”所代表的目录共享同一个文件路径。
-w=/tmp/working 表示设置容器的工作目录为“/tmp/working”
-p 8888:8888 表示容器的端口8888与容器的宿主机器(此处为名称为“default”的虚拟机)端口8888进行绑定
-d 表示以后台方式运行容器
-it 表示与容器之间的连接方式
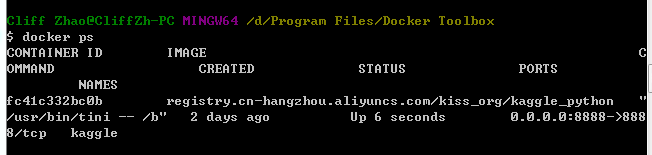
上述命令执行完成后,如果创建成功,会打印出一串字符串,为容器的运行时ID,并可以通过命令
docker ps
查看当前正在运行的容器,如下图
4. 连接kaggle容器
执行命令
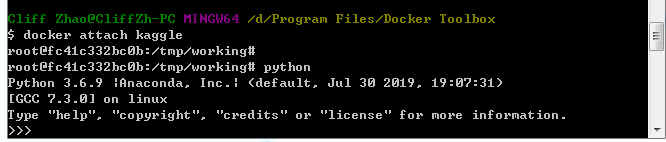
docker attach kaggle
并按两下“回车”,进入容器,如下图所示

python
进入python环境,可以看到如下图:
exit()
退出python环境,回到容器环境。 自此,kaggle容器创建成功!
5. 开启 jupyter notebook 服务
-
设置本机到虚拟机的端口映射
接上步,执行命令
exit退出并关闭容器,并在当前命令行窗口执行命令
docker-machine stop停止docker,如下图

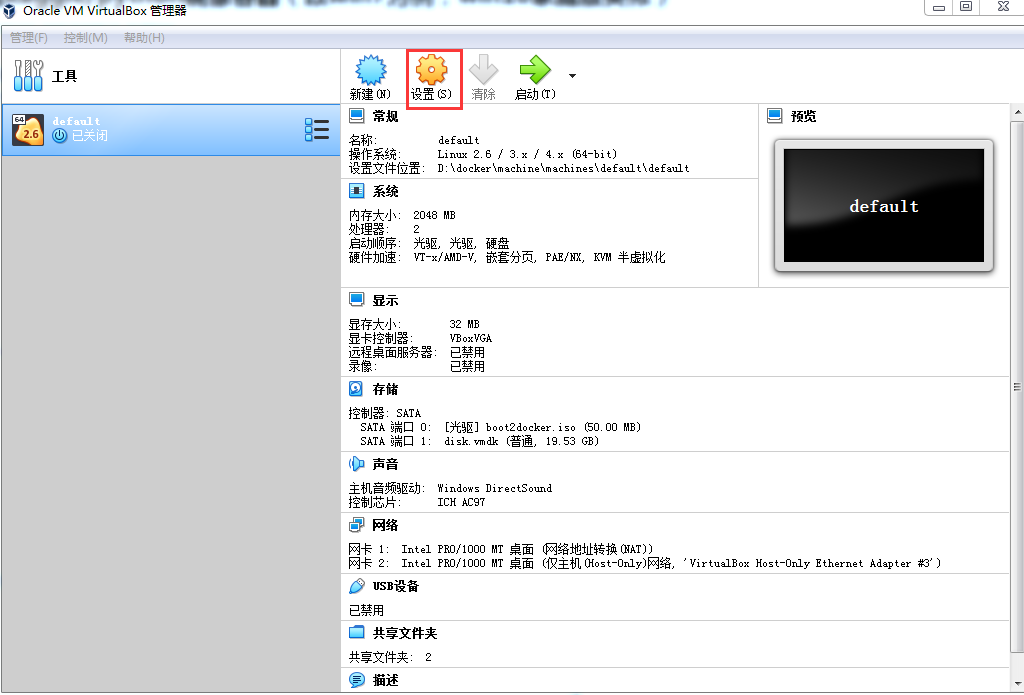
打开VirtualBox管理器,并选中虚拟机列表中的名称为“default”的虚拟机,点击“设置”按钮
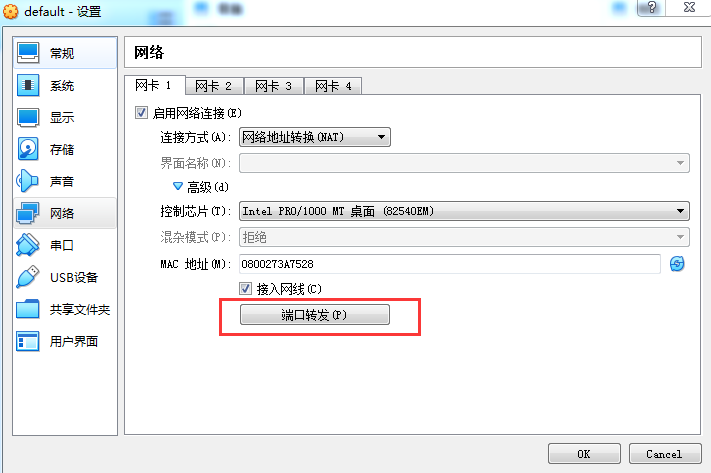
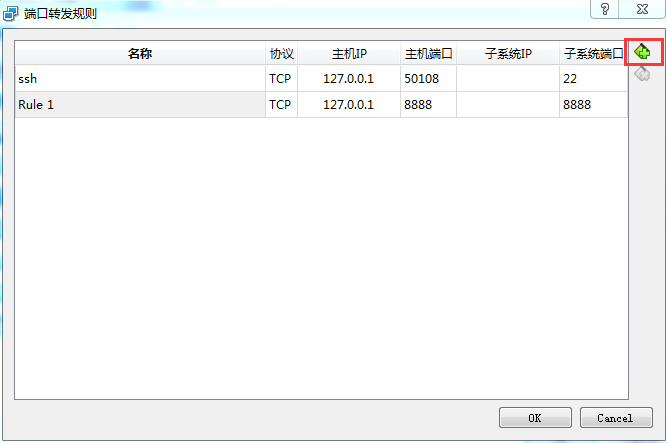
-
启动 jupyter notebook 服务器
以管理员方式运行Docker Quickstart Terminal,直到出现如下画面:
执行如下命令,启动容器
docker start kaggle如下图所示

docker attach kaggle并按两下“回车”,进入容器,如下图所示
jupyter notebook --allow-root --no-browser --ip="0.0.0.0" --notebook-dir=/tmp/working命令参数说明:
--allow-root 表示允许root用户启动jupyter notebook服务
--no-browser 表示不启动浏览器,仅在后台运行。
--ip="0.0.0.0" 表示允许任意ip访问
--notebook-dir=/tmp/working 表示将jupyter notebook的默认目录设为/tmp/working
如下图所示
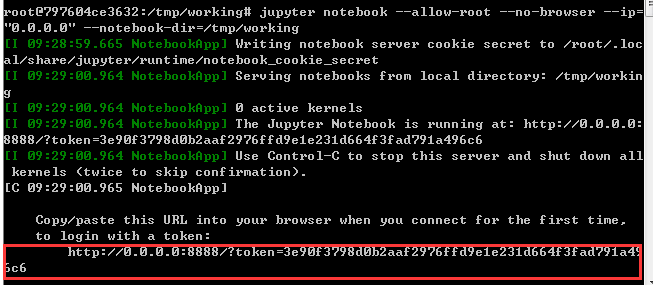

然后再将改网址,粘贴到浏览器地址栏,并访问,如下图所示:
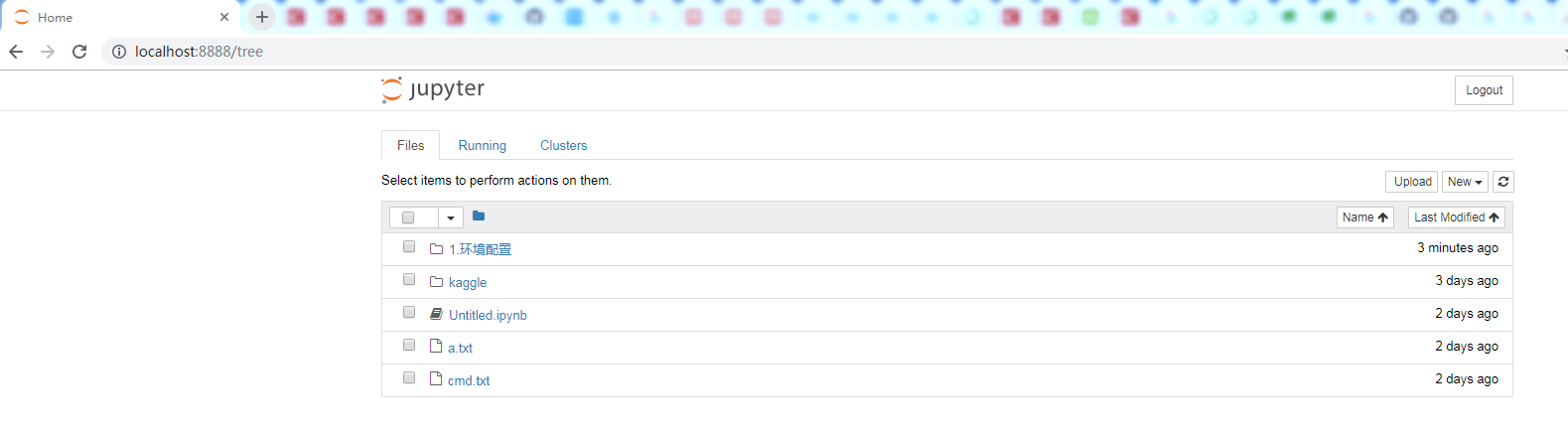
至此,文本挖掘的开发环境初步搭建完毕。
6.补充
- 下载最新的官方镜像kaggle/python
首先,配置国内镜像服务器 以管理员方式运行Docker Quickstart Terminal,直到出现如下画面:
docker-machine ssh default
进入docker虚拟机,如下图所示

sudo sed -i "s|EXTRA_ARGS='|EXTRA_ARGS='--registry-mirror=http://f1361db2.m.daocloud.io |g" /var/lib/boot2docker/profile
然后,执行命令
exit
退出docker虚拟机,并在当前命令行窗口执行命令
docker-machine restart default
重启docker虚拟机,成功后,在当前命令行窗口执行命令
docker pull kaggle/python
开始下载最新版的镜像。 不过,这里并不十分推荐下载最新版的镜像,因为最新版的镜像是只针对FMA指令集优化的,如果你的机器的CPU不支持FMA指令集,将无法正常运行kaggle镜像中的数据挖掘工具
- 一些常用docker命令
查看当前运行的容器列表:
docker ps
查看所有容器列表:
docker ps -a
删除容器:
docker rm xxxxxx为容器名或者容器id
启动容器:
docker start xxxxxx为容器名或者容器id
停止容器:
docker stop xxxxxx为容器名或者容器id
连接容器:
docker attach xxxxxx为容器名或者容器id
查看镜像列表:
docker images
删除镜像:
docker rmi xxxxxx为镜像id
启动docker虚拟机:
docker-machine start xxxxxx为虚拟机名称
停止docker虚拟机:
docker-machine stop xxxxxx为虚拟机名称,不加xxx,默认停止名称为“default”的虚拟机
