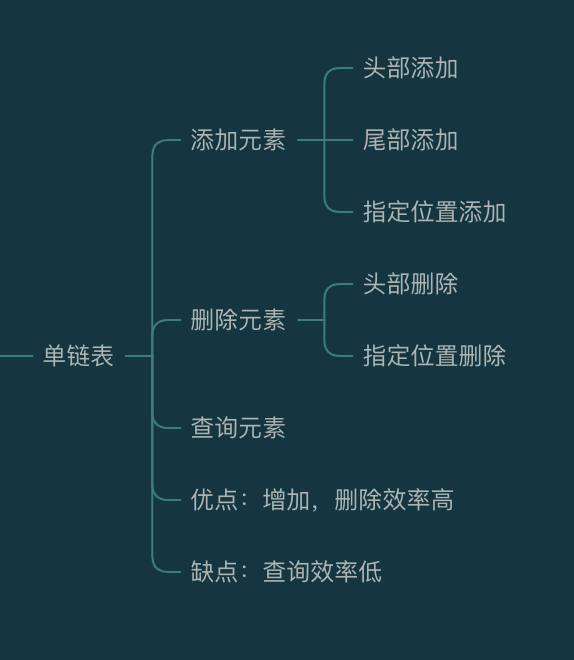
1.前言
在上一篇中我们了解了线性表的顺序存储方式,今天我们再来看下链式存储。首先思考一个问题,为什么要学习链式存储,相比于顺序存储有哪些优缺点。
我们都知道,在顺序存储时,如果要是删除或者添加一个元素的话,需要移动大量的元素,因为顺序存储结构的元素之间都是紧邻的关系,没有间隙,自然无法快速的插入或者删除元素。 所以我们需要学习另外一种存储方式,那就是链式存储
2.简介
看下图
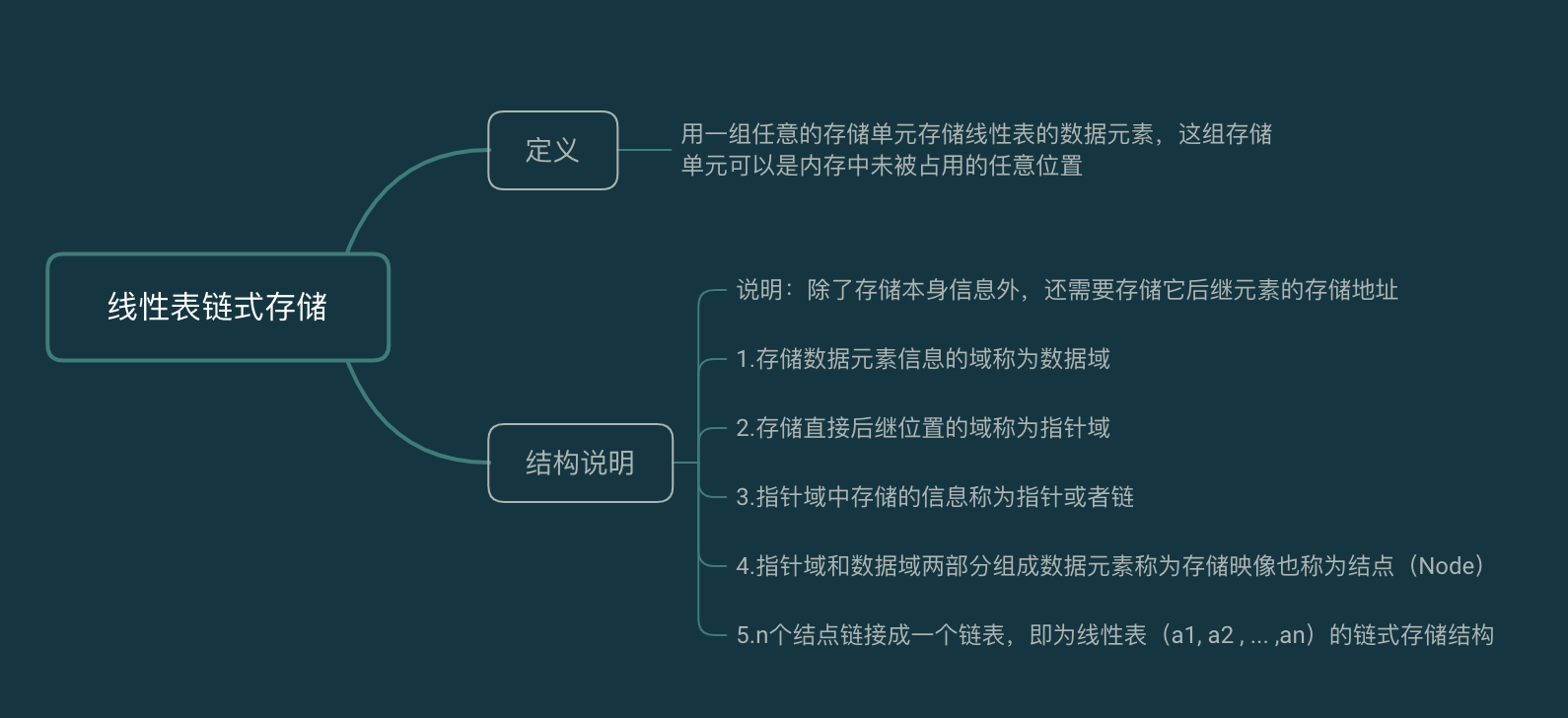
也就是这样,单链表为例
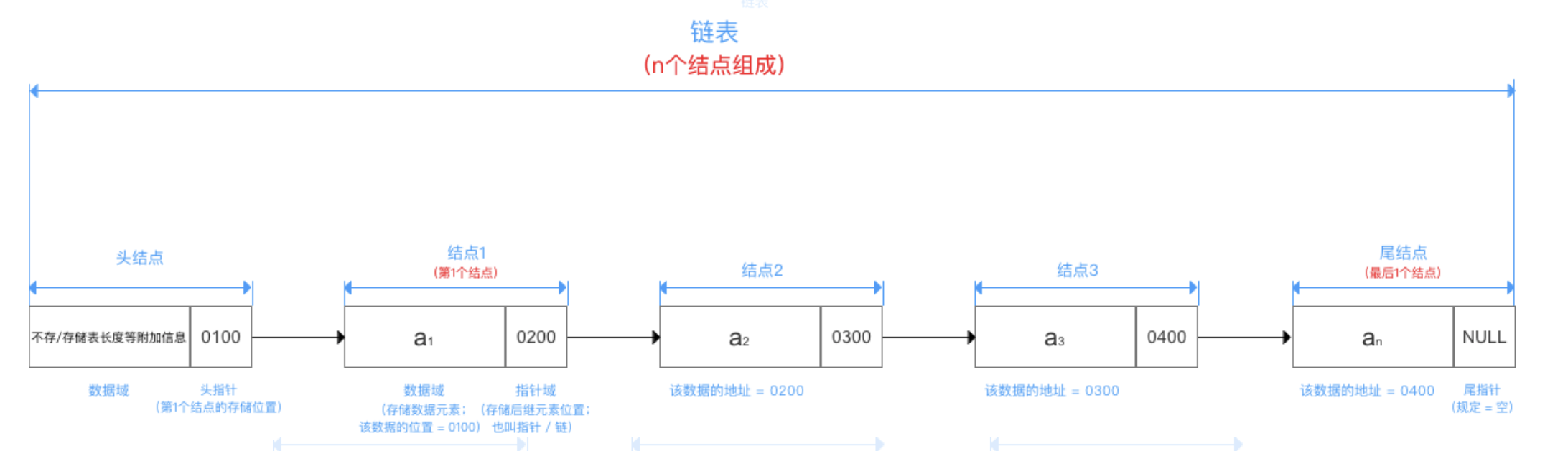
注:该图取于网上
3.对应操作
先以线性表单链表为主(每个结点只有1个指针域)
1.线性表链式结构初始化
/**
* 结点
*
* 结点分为两部分,一部分存储数据,称为数据域,一部分存储下一个结点的位置,称为指针域
* n个结点连成一条链式结构
* */
public class Node<T> {
T data;
Node<T> next;
public Node(T data) {
this.data = data;
}
}
/**
* 线性表链式存储
* */
public class MyLinkedList<T> {
// 链表的头结点
private Node<T> head = null;
// 当前结点
private Node<T> currentNode;
// 链表长度
private int size;
}
2.读取
(思路)
-
判断插入的位置是否真实有效
-
遍历链条找寻元素
-
将结果返回
(代码)
/**
* 根据index获取结点元素
* */
private Node<T> getNodeByIndex(int index){
// 判断插入的位置是否真实有效
if(index < 0 || index >= size){
throw new IndexOutOfBoundsException("插入的位置无效");
}
// 通过next遍历链条
currentNode = head;
for (int n = 0; n < index && currentNode.next != null; n++){
currentNode = currentNode.next;
}
return currentNode;
}
/**
* 根据index获取数据
* */
public T getDataByIndex(int index){
getNodeByIndex(index);
return currentNode == null ? null : currentNode.data;
}
3.插入
插入操作分三种情况
3.1 在头部添加元素
(思路)
-
将需添加的内容封装成结点
-
将新添加结点的指针域指向原第1个结点
-
将新添加结点设置为第1个结点
-
链表长度+1
(代码)
/**
* 在头部添加结点
* */
public void addDataByFirst(T data){
// 封装结点
Node<T> node = new Node (data);
// 将原头结点添加到封装结点的指针域上
node.next = head;
// 将封装的结点设置成头结点
head = node;
// 链表长度+1
size++;
}
3.2 在尾部添加元素
(思路)
-
将数据封装成我们需要的结点
-
先判断链表是否为空,如果为空,添加到首结点
-
链表不为空,找寻到尾结点,将新建的结点,添加到尾结点的指针域上
-
链表长度+1
(代码)
/**
* 在尾部添加结点
* */
public void addDataByEnd(T data){
// 封装结点
Node<T> node = new Node<>(data);
// 如果链表为空,则设置成头结点
if(head == null){
addDataByFirst(data);
return;
}
// 如果链表不为空,则找寻尾结点,将封装的结点设置到尾结点的指针域上
Node temp = head;
while (temp.next != null){
temp = temp.next;
}
temp.next = node;
// 链表长度+1
size++;
}
3.3 在指定位置添加元素
(思路)
-
将要插入的元素封装成结点
-
判断要插入的位置是否有效
-
如果列表元素为空,则直接设置成头结点
-
找寻到要插入的位置,进行插入
(代码)
/**
* 在指定位置添加元素
* */
public void addDataByIndex(int index, T data){
// 如果头结点是空
if(head == null){
addDataByFirst(data);
return;
}
// 封装我们的结点
Node<T> node = new Node<>(data);
// 如果头结点不为空,则添加到指定位置
getNodeByIndex(index);
node.next = currentNode.next;
currentNode.next = node;
// 链表数量+1
size++;
}
4.删除
4.1 从头部删除元素
(思路)
-
判断链表是否还有值
-
将头结点的下一个元素指向当前位置
-
链表-1
(链表)
/**
* 删除
* */
public void deleteDataByFirst(){
// 判断链表是否还有值
if(head == null){
throw new IndexOutOfBoundsException("链表为空");
}
// 将头结点的下一个元素指向当前位置
head = head.next;
// 链表-1
size--;
}
4.2 在指定位置删除元素
(思路)
-
检查当前链表是否为空
-
把当前指针(currentNode)定位到 需删除结点(index)的前1个结点
-
获取被删除结点的数据
-
将需删除结点(index)的前1个结点 的下1个结点 设置为 需删除结点(index)的下1个结点
-
链表长度-1
(代码)
/**
* 在指定位置删除结点
* */
public T deleteDataByIndex(int index){
// 判断链表是否还有值
if(head == null){
throw new IndexOutOfBoundsException("链表为空");
}
// 把当前指针(currentNode)定位到 需删除结点(index)的前1个结点
getNodeByIndex(index - 1);
// 获取被删除结点的数据
Node<T> deleteNode = currentNode.next;
// 将需删除结点(index)的前1个结点 的下1个结点 设置为 需删除结点(index)的下1个结点
currentNode.next = deleteNode.next;
return deleteNode.data;
}
4.性能比较
基本上单链表的用法都在上面了,接下来我们再分析下它和顺序存储的优缺点,我们从时间性能,存储方式,空间性能三点做比较
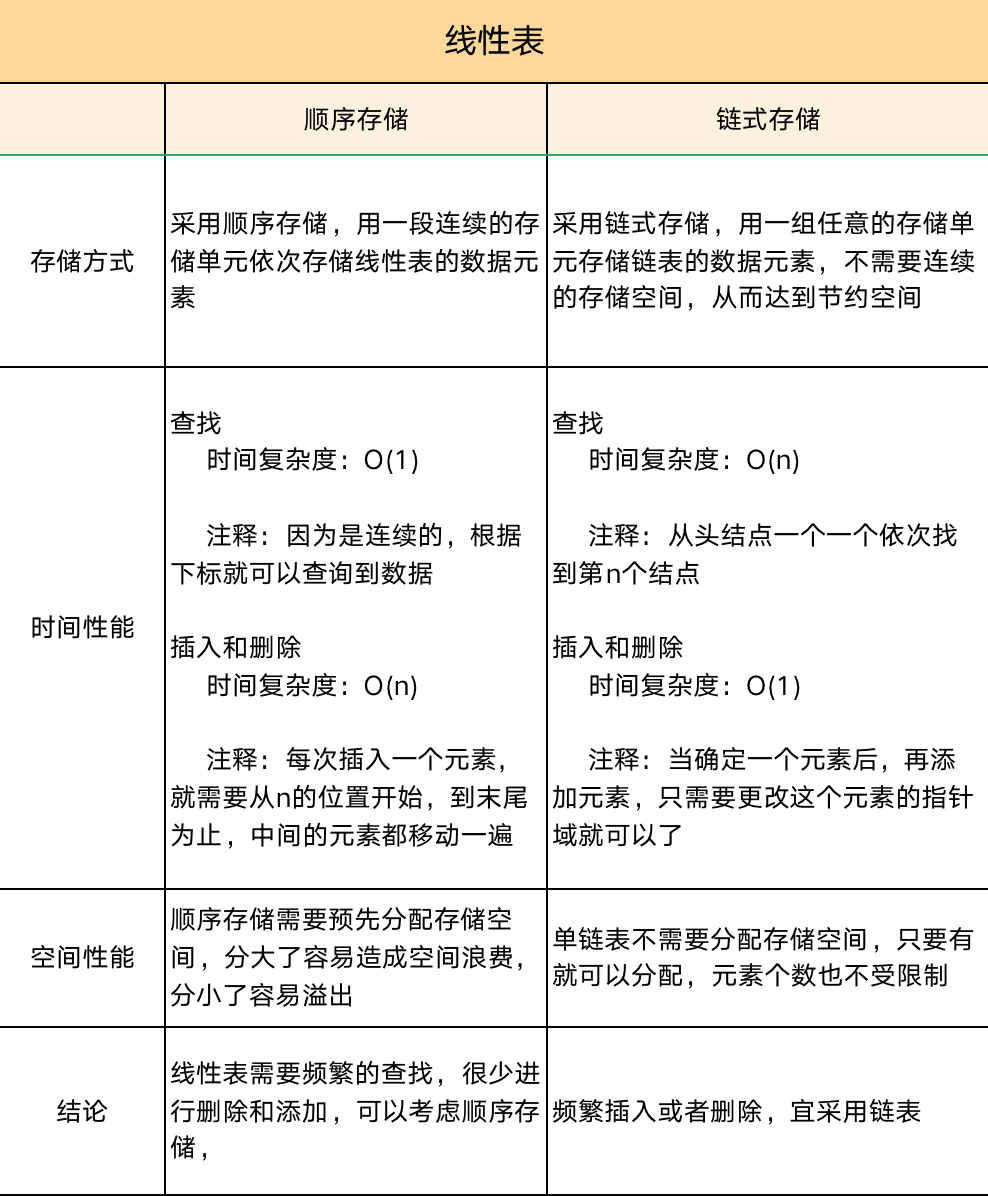
5.总结