

特殊字符
行终结符:\n(换行符) 、\r(回车符) 、\u2028(行分隔符) 、\u2029(段落分隔符)
. :匹配除了行终结符之外的单个字符
/a.\d/.test('aaa1000') //true,匹配到的:aa1
? :表示0/1 个
$:匹配最后一个字符后的内容,即空字符串。要匹配 "$" 字符本身,请使用 "\$"
\d:任意一个数字,0~9 中的任意一个
\D:匹配非数字的字符
\w:任意一个字母或数字或下划线,也就是 A~Z,a~z,0~9,_ 中任意一个
\W:匹配除字母、数字、下划线以外的字符
\s:包括空格、制表符、换页符等空白字符的其中任意一个
\S:匹配非空字符,\s\S就表示匹配所有字符
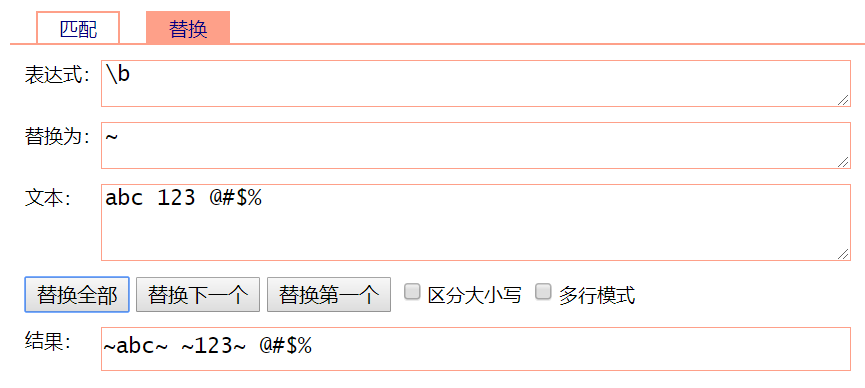
\b:匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符
(它要求它在匹配结果中所处位置的左右两边,其中一边是 "\w" 范围,另一边是 非"\w" 的范围。只是将所在缝隙之前、之后的字符取来进行了一下判断)
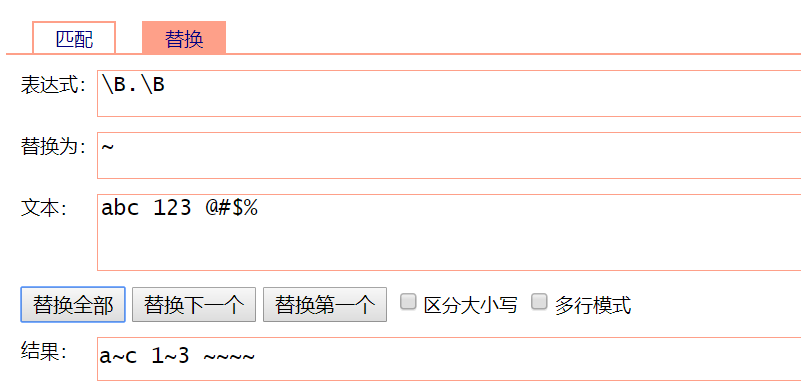
\B:匹配非单词边界,即两边都是\w或都不是\W
"^","$","\b"。它们都有一个共同点,那就是:它们本身不匹配任何字符,
只是对 "字符串的两头" 或者 "字符之间的缝隙" 附加了一个条件。
惰性匹配(贪婪与非贪婪模式)
如果在数量词*、+、? 或 {}, 任意一个后面紧跟该符号(?),可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的 "匹配少一点",叫做非贪婪即勉强模式。
如果少匹配就会导致整个表达式匹配失败的时候,则会尽最大程度的匹配,即贪婪模式
console.log("aaabc".replace(/a+/g, "d")); // dbc
console.log("aaabc".replace(/a+?/g, "d")); // dddbc

正向预查与反向预查
以下规则只匹配符合规则的
间隙,若在以下规则还紧接着其他规则,则在符合规则的间隙后找
(?:pattern):加了?:只后,()内匹配到的内容不作为子匹配内容,不被记录下来
let reg=/industr(?:y|ies)i/
let reg1=/industr(y|ies)i/
"industry".match(reg) //industry
"industry".match(reg1) //industry,$1:y(子匹配项)
(?=pattern):所在缝隙的右侧,必须能匹配上pattern,但pattern不作为匹配到的内容
(?!pattern):所在缝隙的右侧,不能匹配上pattern
(?<=pattern):所在缝隙的左侧,必须能匹配上pattern
(?<=\d{4})\d+(?=\d{4})
"1234567890123456":匹配到:除了前四个和后四个数字
只匹配间隙,不会影响后边的表达式来真正的匹配
Reg:(\w)((?=\1\1\1)(\1))+
"aaa ffffff 999999999"
匹配结果:ffff 9999999
表示的含义:可以看成是一个字符重复4次的话,就取前两个
比如:\w匹配‘f',然后\1表示第一个括号匹配到的,
?=\1\1\1,则表示某个间隙后是跟3个‘f',到这里就已经匹配了第一个‘f'和f后面的间隙,
然后还有一个\1,则匹配间隙后的内容为'f'的字符
实现千分符, 将一个数值以千分位表示,即1223456789表示为1,223,456,789
function f(num){
num=num.toString();
let reg=/(?=(?!\b)(\d{3})+$)/g
return num.replace(reg,function($0){
return ","
})
}
console.log(f(1312567)); //1,312,567
这个正则是为了找到后面跟着的数字的个数是3或3的倍数的空隙的地方,在这个地方加上“,”
防止这个数字的个数是3的整数倍,如果没有写”?!\b"的话,在这个数字的开头也会添加上","。
加$(匹配字符结尾的位置)的原因是要因为匹配到的地方的后面跟着的数字的个数需要是3的倍数,否则只要后面有三个数字就会加上“,”,最终得到1,3,1,2,567
[pattern]
[abcd]:匹配a或b或c或d
[^?&=]:匹配? & = 之外的字符
exec和match
- exec是正则对象reg的方法,返回一个数组,数组的第0个元素存放的是匹配到的文本,第1个元素是第一个子表达式(即括号内的内容)匹配到的文本,以此类推。如果没有匹配到文本,则返回null
- 如果reg是全局匹配的话(即指定匹配模式为g),reg会在lastIndex属性(初始为0)指定的字符开始检索字符串,找到第一个匹配到的文本之后,会把reg的lastIndex 属性设置为匹配文本的最后一个字符的下一个位置。所以可以循环使用exec()方法找到所有匹配到的文本
- 如果要用reg去匹配另一个字符串,需要将reg的lastIndex属性手动设为0
- match是字符串的方法,返回一个数组,如果regexp的标准没有g,则只会在字符串中执行一次匹配,返回的数组的元素和exec()没有全局匹配的情况是一样的。
- 如果没有g,则返回的数组中还存放index属性和input属性
- 如果有g,则数组只会存放所有匹配到的子串,而且也没有index属性或input属性
var url = 'http://www.baidu.com?a=1&b=2&c=3';
var reg = /([^?&=]+)=([^?&=])*/g;
console.log(reg.exec(url)); //["a=1", "a", "1", index: 21, input: "http://www.baidu.com?a=1&b=2&c=3"]
console.log(reg.exec(url)); //["b=2", "b", "2", index: 25, input: "http://www.baidu.com?a=1&b=2&c=3"]
console.log(reg.exec(url)); //["c=3", "c", "3", index: 29, input: "http://www.baidu.com?a=1&b=2&c=3"]
console.log(reg.exec(url)); //null
reg.lastIndex = 0; //这段代码很重要哦,注意理解
console.log(reg.exec(url)); //["a=1", "a", "1", index: 21, input: "http://www.baidu.com?a=1&b=2&c=3"]
var url = 'http://www.baidu.com?a=1&b=2&c=3';
var reg = /([^?&=]+)=([^?&=])*/;
var result = url.match(reg);
console.log(result); //["a=1", "a", "1", index: 21, input: "http://www.baidu.com?a=1&b=2&c=3"]
console.log(result.index); //21
console.log(result.input); //http://www.baidu.com?a=1&b=2&c=3
var url = 'http://www.baidu.com?a=1&b=2&c=3';
var reg = /([^?&=]+)=([^?&=])*/g;
var result = url.match(reg);
console.log(result); //["a=1", "b=2", "c=3"]
console.log(result.index); //undefined
console.log(result.input); //undefined
