

语言类型
- 静态语言:在使用之前就要确定其变量类型的语言
- 动态语言:在运行过程中需要检查变量类型的语言
- 弱类型语言:支持隐式类型转换的语言
- 强类型语言:不支持隐式类型转换的语言
Javascript 的内存模型
主要包含三部分:堆空间、栈空间、代码空间。
栈空间与堆空间
先看一段代码:
function foo() {
var a = "极客时间";
var b = a;
var c = { name: "极客时间" };
var d = c;
}
foo();
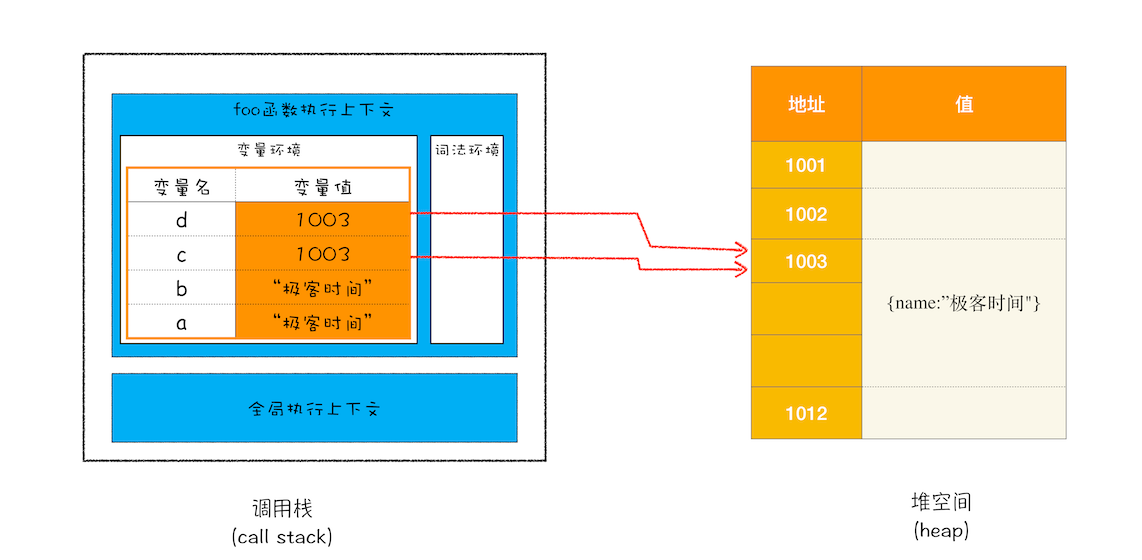
普通类型的变量都被保存在执行上下文中,执行上下文又被压入到栈中。而引用类型的变量则是在栈中存放访问堆空间的地址,其值被保存在堆空间中。- 原始类型赋值是复制变量值,引用类型是复制引用地址。
- 为什么不都放在栈中?
- 栈空间小,主要用来存放一些原始类型的小数据;堆空间很大,能存放很多大数据,不过分配内存与回收内存都会占用一定的时间。
- JS 引擎需要用栈来维护程序执行期间的上下文状态,若过大,会影响上下文切换效率进而影响程序执行效率。
垃圾数据是如何自动回收的?
JS 中的垃圾数据分为:栈中的垃圾数据与堆中的垃圾数据
以下面这段代码为例分析:
function foo() {
var a = 1;
var b = { name: "极客邦" };
function showName() {
var c = "极客时间";
var d = { name: "极客时间" };
}
showName();
}
foo();
栈中的垃圾回收
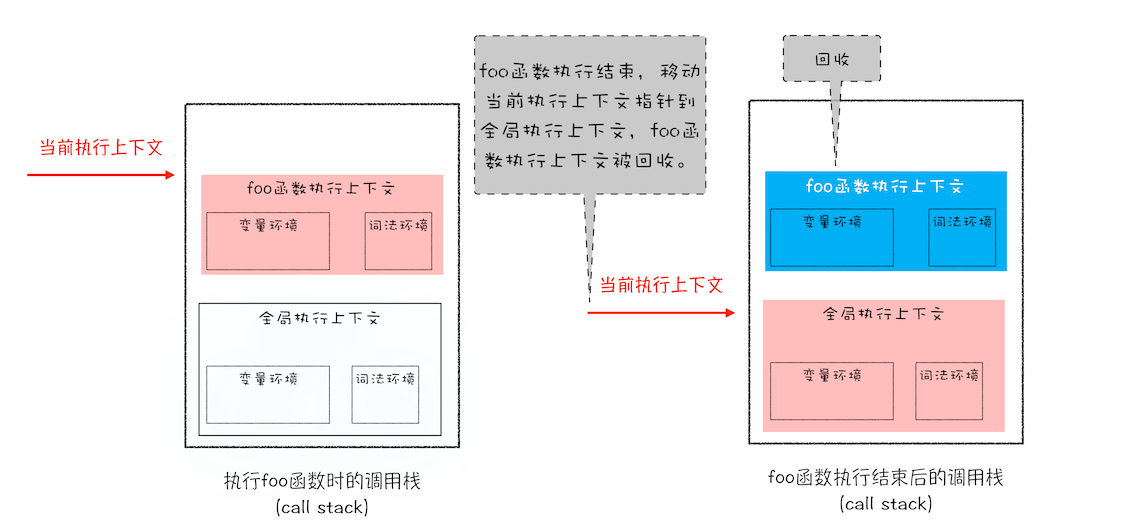
通过 ESP 指针(即记录当前执行状态的指针)来操作,ESP 指向 showName 的函数上下文时,表示当前正在执行 showName 函数。
当 showName 执行完毕后,ESP 下移指向 foo 的执行上下文,这个操作就是销毁 showName 的函数执行上下文。
下图为从栈中回收 showName 执行上下文的过程
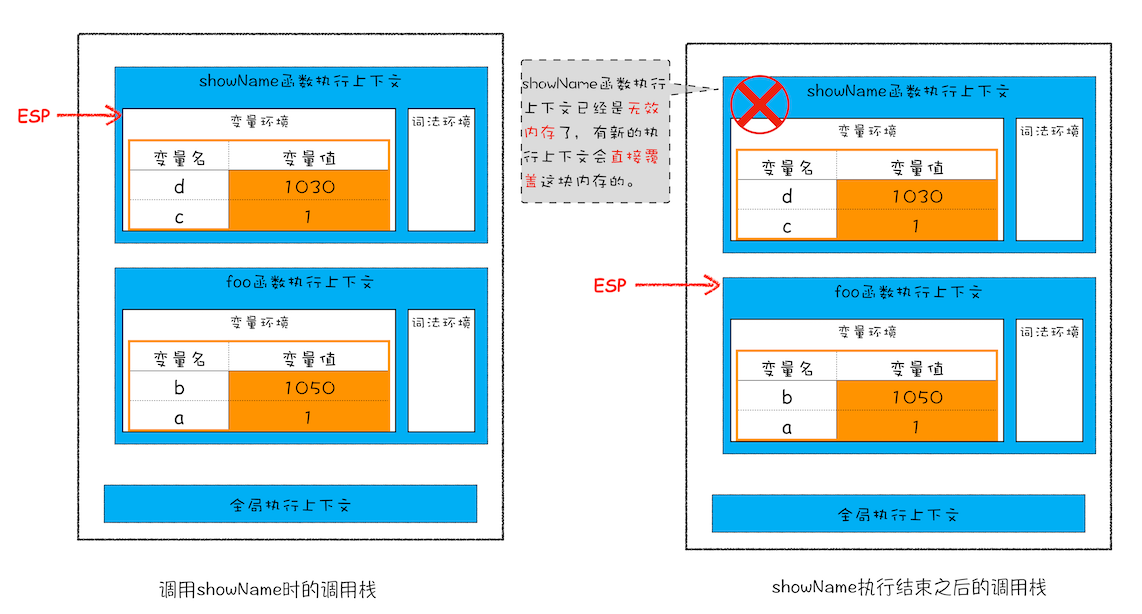
showName 虽然仍保留在栈中,但已属于无效内存。当 foo 函数再次调用另外一个函数时,showName 执行上下文会被覆盖掉。
堆中的垃圾回收
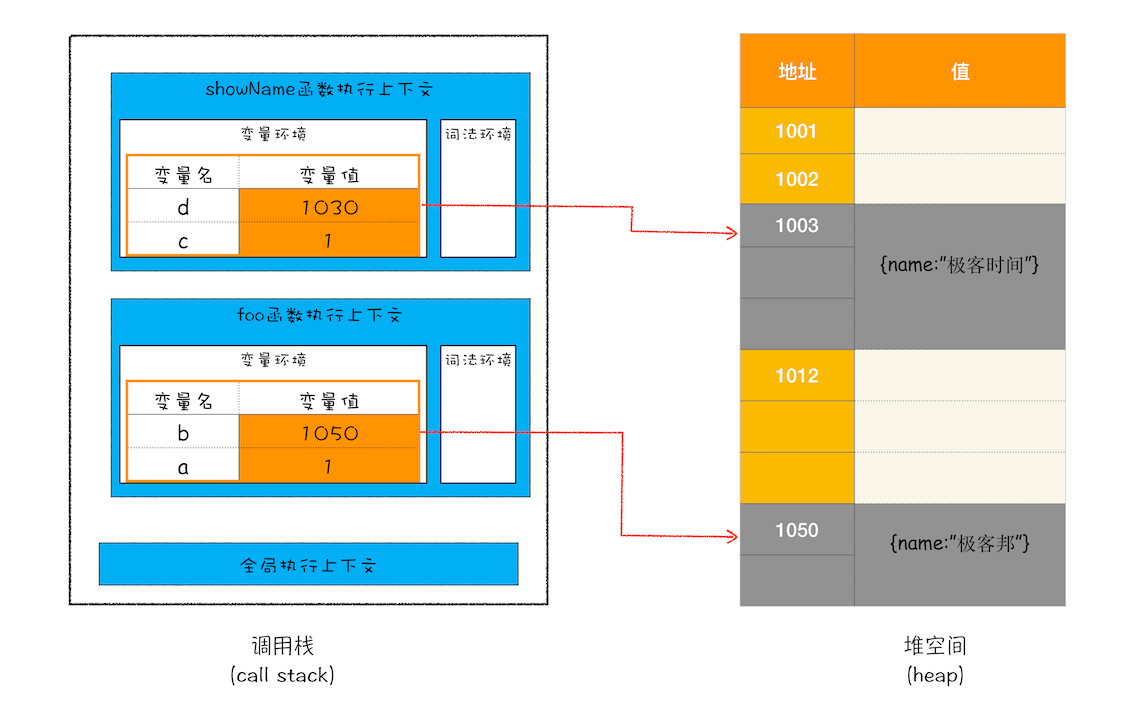
当 foo 执行结束后,ESP 就指向全局上下文了,此时内存状态如下图。

从图中可以看出,堆中的垃圾并没有被回收。 要想回收堆中的垃圾,就要用到 JS 的垃圾回收器了。 下面先介绍下垃圾回收领域的术语。
代际假说与分代收集
- 代际假说的两个特点:
- 大部分对象在内存中存在时间很短,即很多对象一经分配内存,很快就变得不可访问。
- 不死的对象,会活的更久。
在 V8 中把堆分为新生代和老生代两个区域,新生代存放生存时间很短的对象,容量只有 1~8M;老生代中存放生存时间久的对象,容量很大。
对应的就有两种垃圾回收器,副垃圾回收器与主垃圾回收器。 主垃圾回收器:主要负责老生代的垃圾回收。 副垃圾回收器:主要负责新生代的垃圾回收。
垃圾回收器的工作流程
两种回收器有一套共同的执行流程。
- 标记空间中的活动对象与非活动对象。活动对象即还在使用的对象,非活动对象就是可以进行垃圾回收的对象。
- 回收非活动对象占用的内存。在所有对象标记完后,统一清理内存中被标记为可回收的对象。
- 整理内存。频繁回收会导致内存空间不连续,即有很多内存碎片。当要分配较大的连续内存时,就会出现内存不足的情况;所以需要整理碎片。(副垃圾回收器不会产生内存碎片,故不需要这步。)
副垃圾回收器(GC:garbage collect)
主要用于回收新生代的垃圾,故内存不大。
下图为 V8 中的堆空间分布。
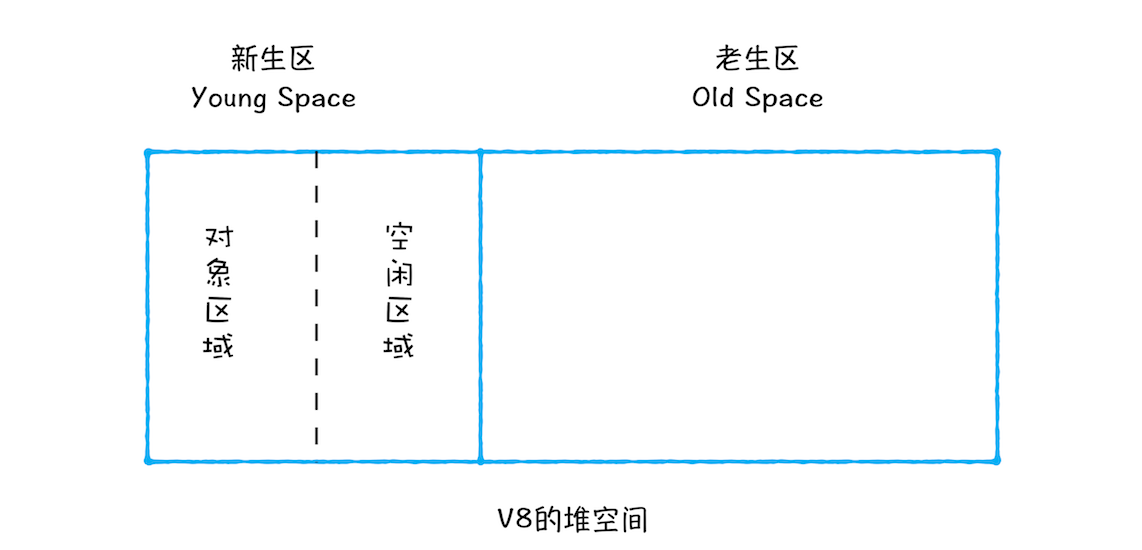
新生代通过 Scavenge 算法将空间划分为对象区域与空闲区域。 每当对象区域被写满时,就会执行一次垃圾回收,具体过程如下:
- 先对对象区域中的垃圾做标记;
- 标记完成后,GC 将非活动的对象回收,将存活的对象复制到空闲区域中,同时将对象进行有序排列。(相当于内存整理)
- 完成复制后,再将对象区域与空闲区域进行反转,这样就完成了垃圾回收。
由于复制操作需要时间成本且操作频繁,所以为了执行效率,新生代的空间都不会太大;若经过两次 GC 回收依然存活,就会将活着的对象移到老生代中,这就是 JS 引擎的对象晋升策略。
主垃圾回收器
主要用于回收老生代的垃圾,除了新生代中晋升的对象,一些大的对象会被直接分配到老生代。
老生代对象的两个特点:
- 占用空间大
- 存活时间长
基于上述两个特点,主垃圾回收器采用标记-清除(Mark-Sweep)的算法进行垃圾回收。
标记:从一组根元素开始,递归遍历这组根元素,能到达的元素成为活动对象,没有到达的为垃圾数据。
function foo() {
var a = 1;
var b = { name: "极客邦" };
function showName() {
var c = "极客时间";
var d = { name: "极客时间" };
}
showName();
}
foo();
还是这段代码,当 showName 函数退出后,调用栈和堆空间如下图:
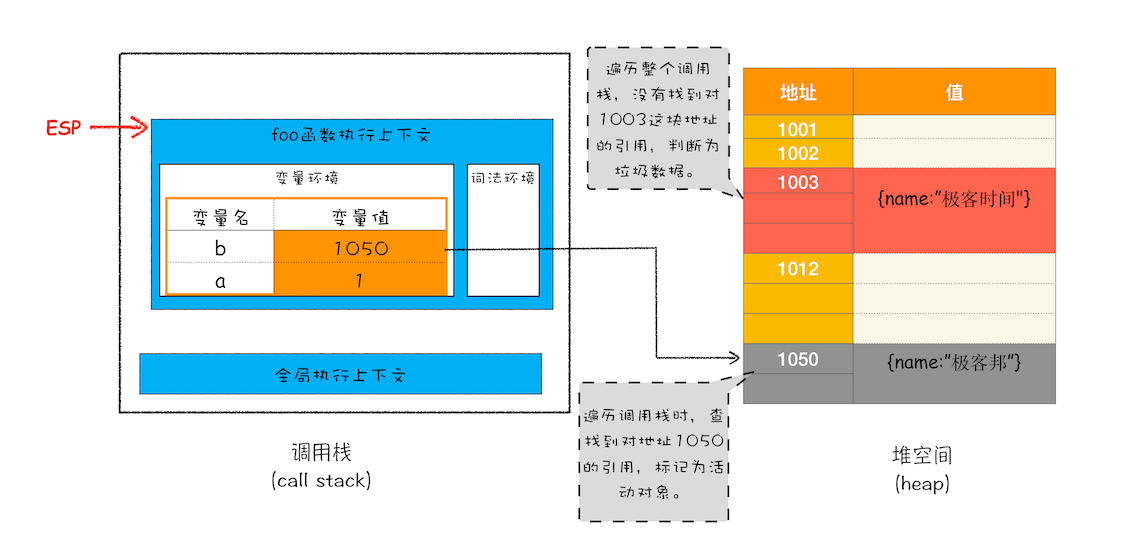
从上图可以看出,当 showName 执行结束后,ESP 执行 foo 的执行上下文,此时遍历调用栈,不会找到引用 1003 地址的变量,意味着 1003 这块数据为垃圾数据,被标记为红色;而 1050 被 b 引用了,所以会被标记为活动对象。
下图为垃圾清除的过程
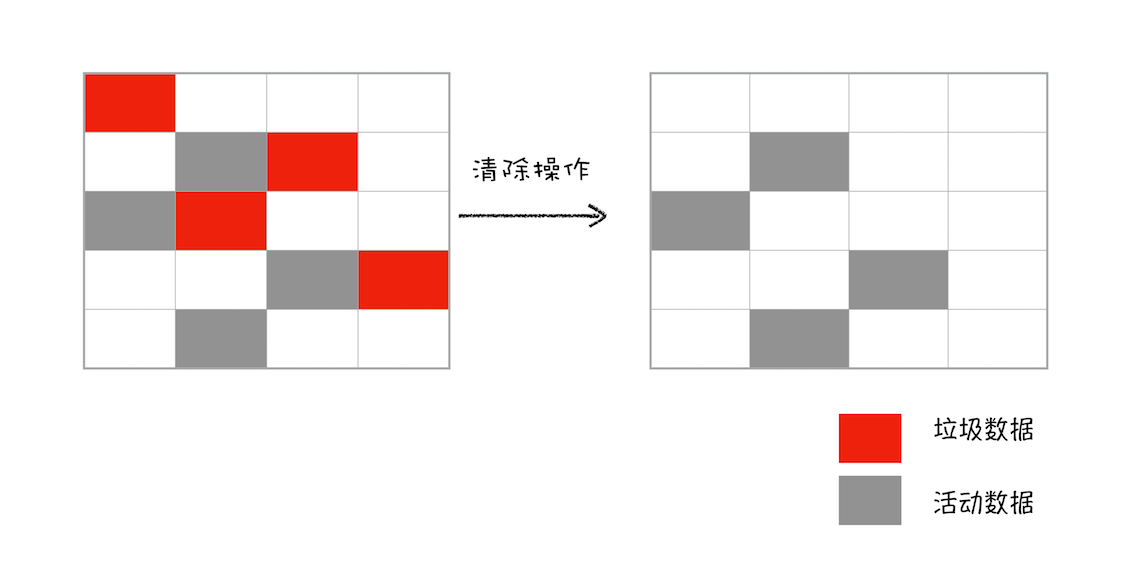
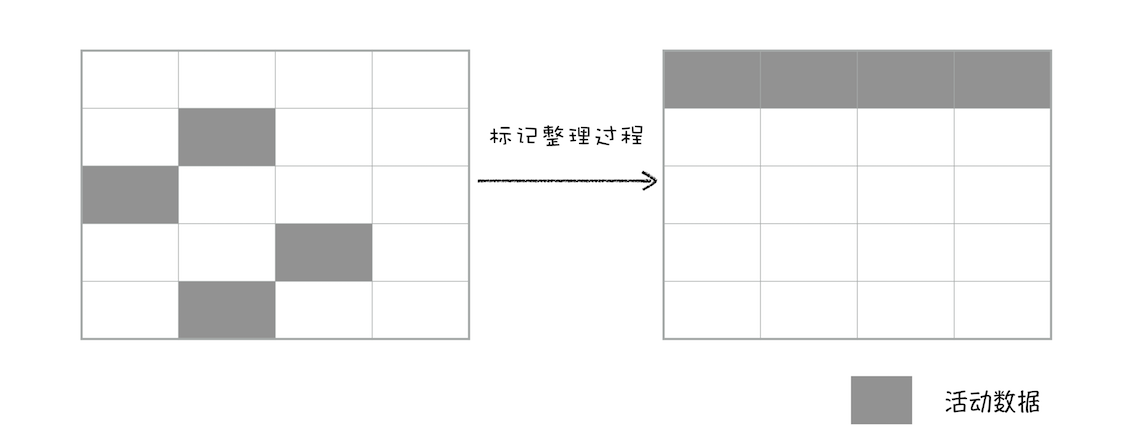
对一块内存多次执行标记-清除算法后,会产生大量不连续的内存碎片。于是又出现了另一种算法标记-整理(Mark-Compact),标记过程都是一样的,标记完后将所有的活动对象都向一端移动,然后直接清除掉端边界以外的内存。
全停顿与增量标记
全停顿:JS 是运行在主线程之上的,一旦执行垃圾回收,就需要将正在执行的 JS 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行,这期间应用的性能和响应能力都会直线下降。这个过程就叫做全停顿(Stop-The-World)。
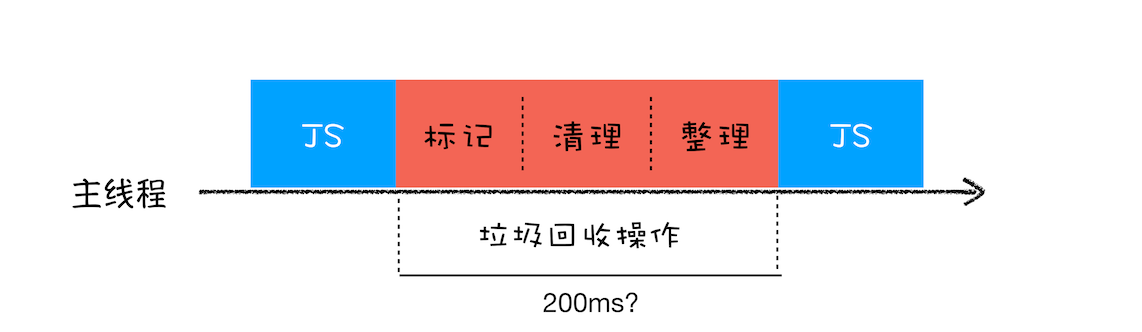
V8 新生代垃圾回收因为空间小,存活对象少,全停顿影响不大;但老生代就不一样了,比如正在执行 JS 动画,GC 工作导致主线程不能做其他事情,那个动画在这段时间无法执行,页面就会卡顿。
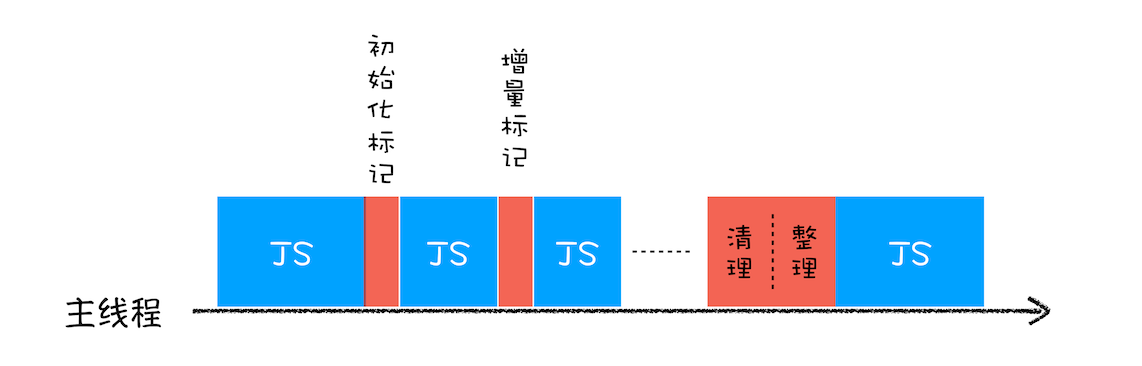
为降低卡顿,于是诞生了增量标记(Incremental Marking)算法。
增量标记:V8 将标记过程分为一个个子标记过程,同时让垃圾回收器和 JS 应用逻辑交替进行,直至标记完成。这些小任务执行时间短,穿插再 JS 任务间执行,这样就不会感受到页面卡顿了。
编译器(TurboFan)与解释器(Ignition)
-
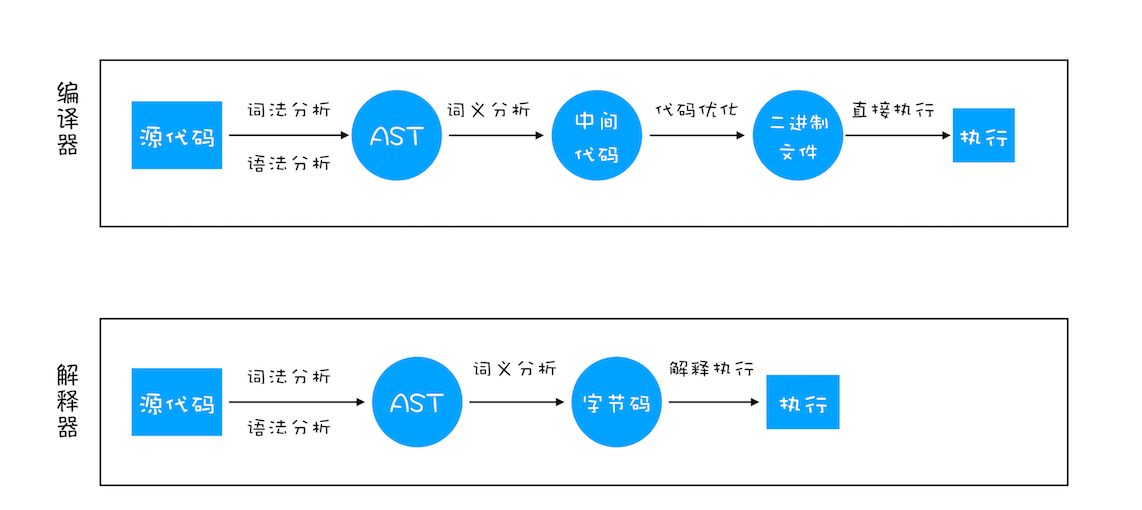
编译型语言
在程序执行前,需经过编译器编译,并且编译之后会直接保留机器能读懂的二进制文件;以后每次运行程序时,直接运行二进制文件,不需要重新编译。 -
解释型语言 在每次运行时都要经过解释器对程序进行动态解释和执行。
V8 如何执行一段 JS 代码?
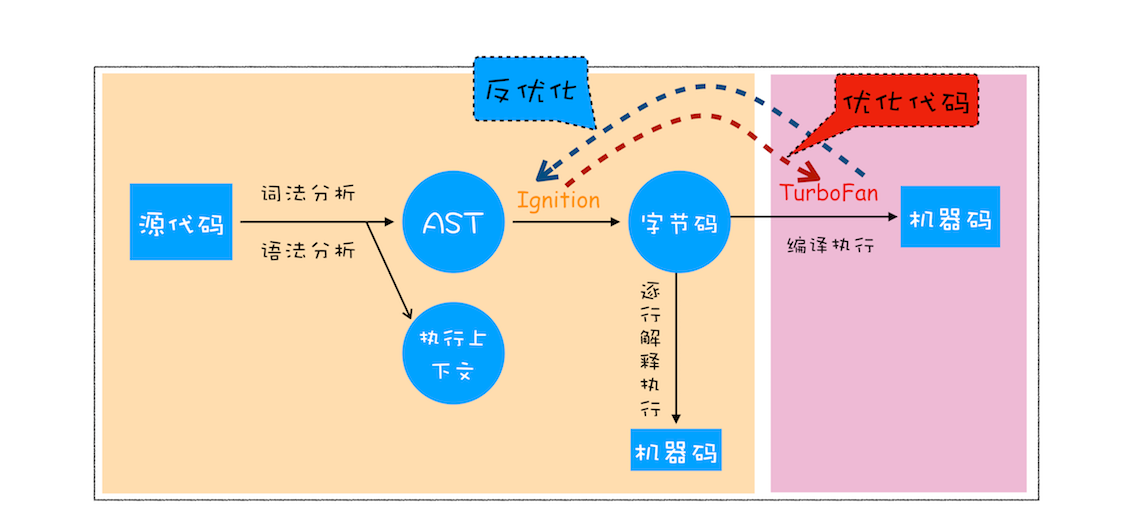
结合上图,V8 执行代码可分为以下几步
生成 AST 和执行上下文
将源代码转换为编译器和解释器可以理解的 AST,并生成执行上下文。
-
为什么要生成 AST 以及什么是 AST?
先说第一个,因为编译器和解释器无法理解高级语言,所以要生成 AST,就像渲染引擎将 HTML 转换为计算机可以理解的 DOM 树一样。再来说第二个,AST 是代码的结构化表示,有着非常重要的作用。
Babel 原理: 将 ES6 源码转换为 AST,再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用它来生成 ES5 源代码。
ESLint 原理:检测流程也是将源码转换为 AST,再利用 AST 来检查代码规范。 -
如何生成 AST?
两个阶段:分词(词法分析),解析(语法分析)。词法分析:将源码拆解成最小的、不可再分的 token(关键字、标识符、赋值、字符串)。
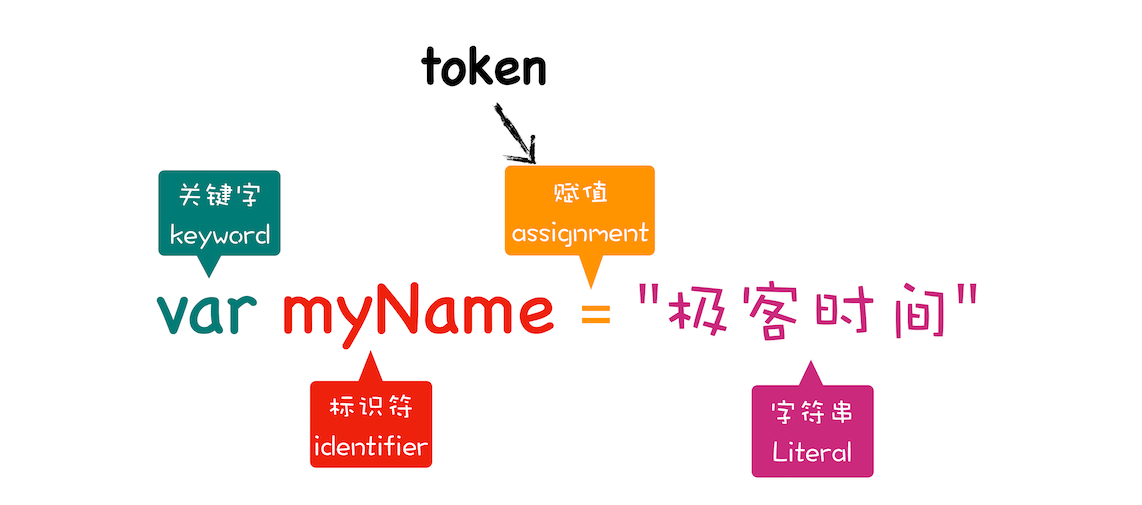
语法分析:根据规则将上一步的 token 转换为 AST。若源码存在语法错误,则不会生成 AST。
有了 AST 以后,V8 就会生成这段代码的执行上下文。
如何查看代码生成的 AST
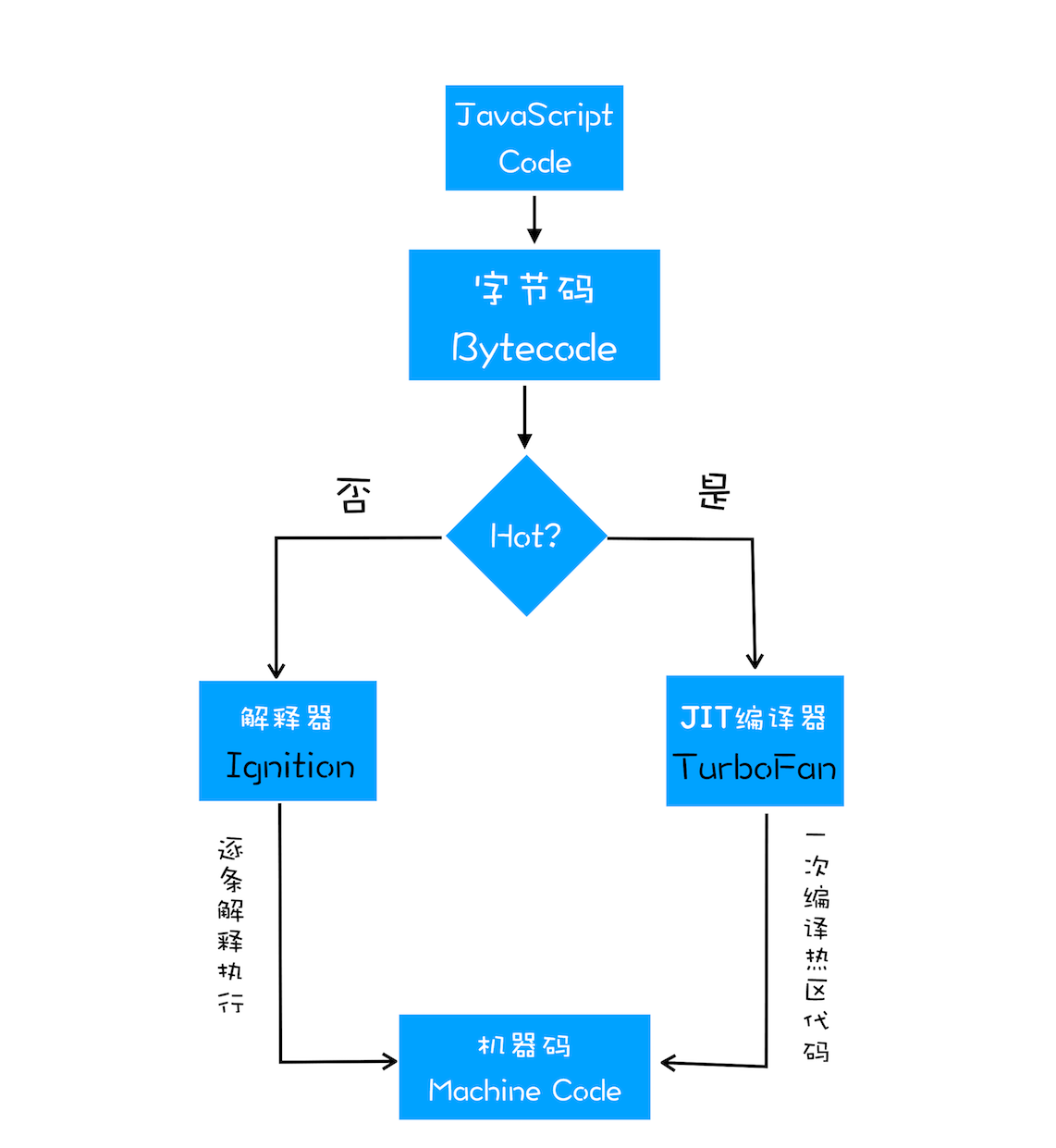
生成字节码
有了 AST 和执行上下文后,解释器根据 AST 生成字节码并解释执行。
-
为什么不直接转成机器码,而是通过字节码转成机器码? 看下图:

由上图可以看出,机器码占用的空间远大于字节码,早期手机内存只有 512M,而 V8 需要消耗大量内存来存放转换后的机器码,为了解决内存占用问题,就有了现在这套架构。
字节码:介于 AST 与机器码之间的一种代码,需要通过解释器将其转为机器码后才能执行。
执行代码
第一次执行字节码时,解释器会逐条解释执行,如果发现有热点代码(即一段代码被重复执行多次),编译器就会将这段热点代码编译为机器码保存起来,当再次执行这段代码时,只需要执行编译后的机器码;这种技术就叫做即时编译(JIT)。
JS 性能优化
将优化的中心聚焦在单次脚本执行时间和脚本的网络下载上。
- 提升单次脚本的执行速度,避免 JavaScript 的长任务霸占主线程,这样可以使得页面快速响应交互;
- 避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用主线程;
- 减少 JavaScript 文件的容量,因为更小的文件会提升下载速度,占用更低的内存。
