

背景
一开始的方案是准备把常用单词手工列出来,这样拼成一个句子,可以大大减小国际化文案文件的大小。但是有个显著的问题,就是有些单词翻译时很难统一,比如start,有些情况下可能是“开始”,有些情况下又是“启动”;还有一些情况是单词的意思是符合的,但是拼起来就不是原有句子的意思了,或者不通顺,造成一种“中式英语”的尴尬。
基于上面的一些考量,准备直接把所有句子都提取出来整句翻译,这样有几个好处:
- 可以实现自动化提取,甚至使用i18n库包裹对应文案
- 整个句子不会有不通顺的问题
方案
网上找了一些匹配中文字符的正则,都不是太好用, 因为项目里面中文还是比较复杂的。比如前后或者中间可能穿插着英文或数字,或者是标点符号等。还有注释的文案其实不需要翻译,所以也要过滤掉。
那么,就开始吧~
方案一
因为使用的vsCode是个很好用的工具,就尝试着使用正则匹配,然后复制全部匹配内容的方式。结果碰到几个问题:
- 正则很难写,因为不仅要过滤注释,注释还有单行多行的,有些边际情况不好处理。
- 复制全部匹配内容时,复制的其实是包含了上下文的,而不是单纯匹配到的字符,所以还手动需要做二次提取处理。
因此只好放弃这个方案,再想想其他方法。
方案二
AST解析,这样可以知道每个节点的内容了。不过大概想了想,也有几个难点要面对:
- 对于文本插值的情况不是很方便,需要多个节点匹配着处理
- 本身写这么一个bable插件就比较花时间,最好能简单点
方案二暂时保留,继续探索其他方式
方案三
文件内容查找,emmm,好像简单多了,也同样是用正则匹配文件内容,把匹配项列出来就行。那么怎么处理注释节点呢?要全文匹配一下先删掉吗?
对了,打包后的文件里,不就已经把注释都移除了吗,那直接在打包后的文件里查找就好了啊,并且打包后的文件已经是es5格式的,文本插值、单双引号什么的问题也都不存在了,nice~
开整:
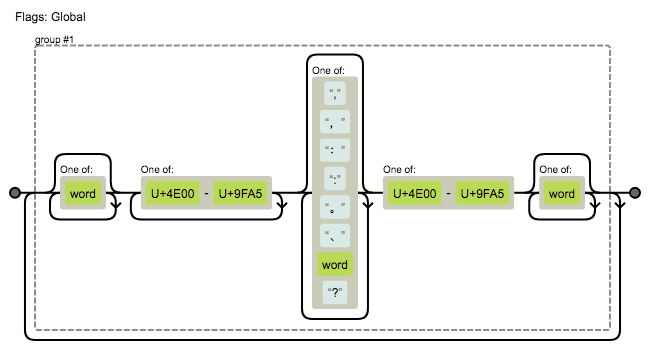
- 先写了个基本符合要求的正则
/([\w]*[\u4E00-\u9FA5]+[,,::。、\w?]*[\u4E00-\u9FA5][\w]*)+/g
使用可视化工具看一下,匹配规则如下:
- 写了个简单的js文件来查找匹配字符:
const fs = require('fs');
const path = require('path');
const { walker } = require('./file-walker');
// 匹配中文词句
const reg = /([\w]*[\u4E00-\u9FA5]+[,,::。、\w?]*[\u4E00-\u9FA5][\w]*)+/g;
const searchExtensions = ['.js', '.html'];
const extMap = {};
searchExtensions.forEach(e => { extMap[e] = true; });
let fileContent = '';
const dealFile = (content, filePath, isEnd) => {
const ext = path.extname(filePath);
if(!extMap[ext]) {
return;
}
const match = content.match(reg);
if (match) {
fileContent += match.concat('');// 文件间内容加一个空,下面进行换行用
}
if(isEnd){
const allWords = fileContent.split(',');
console.log('all matched words count:', allWords.length);
const removeDuplicate = Array.from(new Set(allWords)).map(item => ` "": "${item}",`);
fileContent = '{\n' + removeDuplicate.join('\n') + '\n}';
console.log('words without duplicate count:', removeDuplicate.length);
fs.writeFile(path.resolve(__dirname, '../cn-words.js'), fileContent, 'utf8', (writeErr) => {
if (writeErr) return console.error('write cn-words file error:', writeErr);
});
}
};
walker({
root: path.resolve(__dirname, '../public'),
dealFile,
});
最后输出的就是每行一个中文词句,大概看了下没啥异常的内容。
OK,剩下的就是对着中文翻译,然后使用i18n库把原有内容中的文案包裹一下了,这是后话,暂且不提。
