

正则表达式要么匹配字符,要么匹配位置
regexper.com 通过此网址可以可视化自己写的正则
- 正则表达式有两种匹配模式,一种是纵向匹配,一种是横向匹配
- 从字符开始说起,比方说如果想找到test里面的e字符的话,就直接/e/
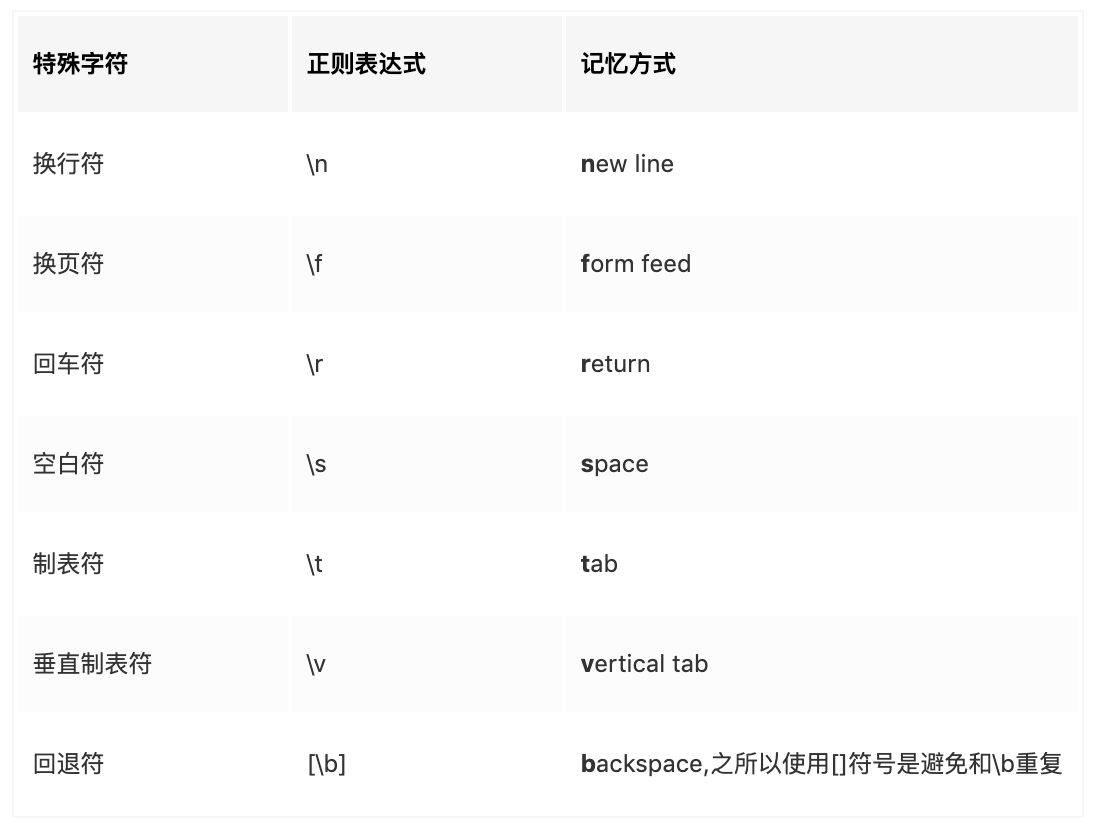
- 如果需要匹配的是特殊字符的话,比方说*则需要\来进行转义
- 如果本身这个字符不是特殊字符,使用\就会让它拥有特殊含义,比方说空格、制表、回车等
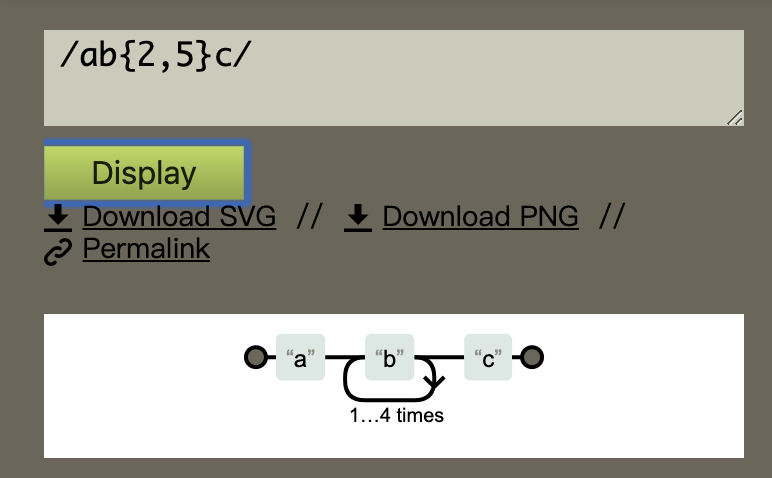
- 如果是字符的一个范围的话,比方说匹配小写字母,通常我们会写成[a-z],其实也就是在开始范围和结束范围之间加一个-来构成一个范围
- 如果我仅仅想匹配"a" "-" "z"这三个当中的任一一个的话,我们只需要让引擎不认为这是一个范围就行了,比方说把-放在开头(/[-az]/)、把-放在结尾(/[az-]/)、把-进行转义(/[a-z]/)即可
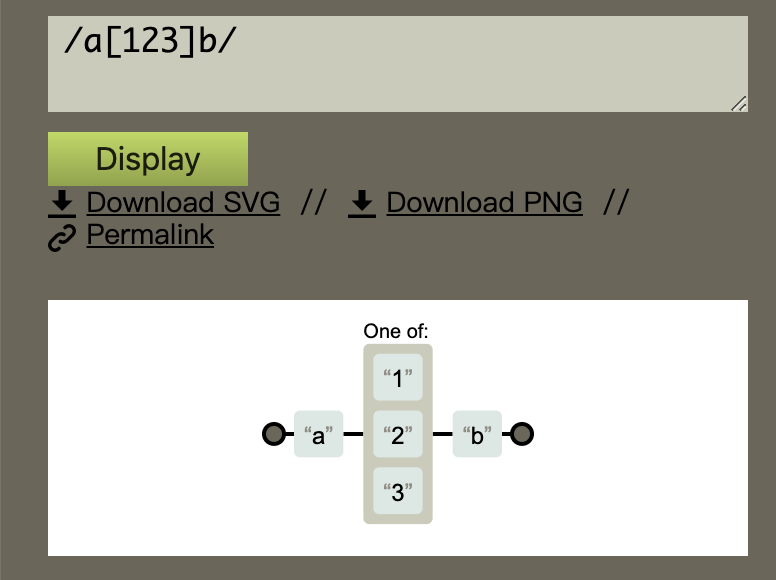
- 匹配125中的任一一个,可以写成/[125]/也可以写成/[152]/ 这个跟顺序无关
- 如果要排除一个范围的话,直接在组内最前面加上^,比方说要匹配除“a” “b” “c” 之外的任一一个,则可以写成/[^abc]
通过此正则测试工具可以方便进行正则测试
- 常用的一些简写方式如下所示:

- 常用的量词如下所示:
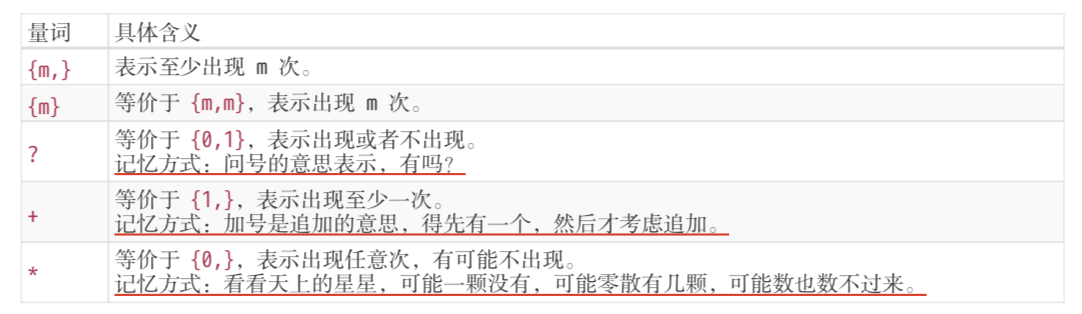
- 我们都知道正则默认是贪婪匹配的,在使用量词时会尽可能多的去匹配
- 通过在量词后面增加一个?来实现惰性匹配(对惰性匹配的记忆方式是:量词后面加个问号,问一问你知足了吗,你很贪婪吗?)
- 多选分支可以支持多个子模式任选其一
var regex = /good|nice/g;
var string = "good idea, nice try.";
console.log( string.match(regex) );
// => ["good", "nice"]
- 但有个事实我们应该注意,比如我用 /good|goodbye/,去匹配 "goodbye" 字符串时,结果是 "good",为什么会这样子呢,其实原因很简单,因为分支结构也是惰性的,即当前面的匹配上了,后面的就不再尝试了
- 匹配十六进制颜色值
var regex = /#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g;
var string = "#ffbbad #Fc01DF #FFF #ffE";
console.log( string.match(regex) );
// => ["#ffbbad", "#Fc01DF", "#FFF", "#ffE"]
- 匹配时间
<!--var regex = /^([01][0-9]|[2][0-3]):[0-5][0-9]$/;-->
var regex = /^(0?[0-9]|1[0-9]|[2][0-3]):(0?[0-9]|[1-5][0-9])$/;
console.log( regex.test("23:59") );
console.log( regex.test("02:07") );
console.log( regex.test("7:9") );
- 匹配日期
var regex = /^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$/;
console.log( regex.test("2017-06-10") );
- 匹配id
<!--var regex = /id=".*?"/-->
上面这个正则效率比较低,因为其匹配原理涉及到回溯
var regex = /id="[^"]*"/
var string = '<div id="container" class="main"></div>';
console.log(string.match(regex)[0]);
讲讲位置匹配
- 什么是位置:位置(锚)是相邻字符之间的位置。
- ^(脱字符)匹配开头,在多行匹配中匹配行开头。
- $(美元符号)匹配结尾,在多行匹配中匹配行结尾。
- \b 是单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置
- \B 就是 \b 的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉 \b,剩下的都是 \B 的。
- (?=p),其中 p 是一个子模式,即 p 前面的位置,或者说,该位置后面的字符要匹配 p。用英文表示就是positive lookahead,也就是正向先行断言。通俗一点的理解就是要求接下来的字符与 p 匹配,但不能包括 p 匹配的那些字符,也就是匹配p前面的那个位置
- (?!p) 就是 (?=p) 的反面意思,用英文表示就是 negative lookahead,也就是负向先行断言
- (?<=p) positive lookbehind
- (?<!p) negative lookbehind
- 其实对于位置的理解,我们可以把它当作空格,比方说一个单词hello,其实是可以等价于
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + "";
"hello" == "" + "" + "hello"
- 把 /^hello$/ 写成 /^^hello?$/,是没有任何问题的,也就是说字符之间的位置,可以写成多个。
- 数字千分位分隔符
var regex = /(?!^)(?=(\d{3})+$)/g;
var result = "12345678".replace(regex, ',')
console.log(result);
// => "12,345,678"
var string = "12345678 123456789",
regex = /(?!\b)(?=(\d{3})+\b)/g;
<!--regex = /\B(?=(\d{3})+\b)/g;-->
var result = string.replace(regex, ',')
console.log(result);
// => "12,345,678 123,456,789"
- 密码验证问题:密码长度 6-12 位,由数字、小写字符和大写字母组成,但必须至少包括 2 种字符
- 至少包含数字,(?=.*[0-9])
- 同时包含具体两种字符,比方说包含数字或小写字符(?=.[0-9])(?=.[a-z])
var regex = /(?=.*[0-9])(?=.*[a-z])^[0-9A-Za-z]{6,12}$/;
- 这里可能不太好理解的地方在于(?=.[0-9])(?=.[a-z])^,其实表示开头前面还有个位置,当然也是开头,即同一个位置
<!--三种“都不能”,不能全部是数字,不能全部是小定字母,不能全部是大写字母-->
var regex = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/;
<!--同时包含数字和小写字母-->
<!--同时包含数字和大写字母-->
<!--同时包含小写字母和大写字母-->
var regex = /((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[AZ]))^[0-9A-Za-z]{6,12}$/;
- 说下正则当中的或与非
- 要判断字符串中是否包含目标字符串,比方说包含hello
/^.*hello.*$/im.test(page)
/^(?=.*hello).*$/im.test(page)
- 比方说包含hello 还要同时包含 world
/^(?=.*hello)(?=.*world).*$/im.test(page)
- 比方说包含hello 或者 包含 world
/^.*(hello|world).*$/im.test(page)
- 比方说包含hello 但是同时不包含world
/^(?=.*hello)(?!.*world).*$/im.test(page)
- 比方说先出现hello后包含world
/^.*hello(?=.*world).*$/im.test(page)
讲讲正则中的括号的作用
- 起到分组作用
- /a+/ 匹配连续出现的 "a",而要匹配连续出现的 "ab" 时,需要使用 /(ab)+/
- 起到分支结构作用
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression") );
- 分组引用
- 也就是说在匹配过程中,给每一个分组都开辟一个空间,用来存储每一个分组匹配到的数据。既然分组可以捕获数据,那么我们就可以使用它们。

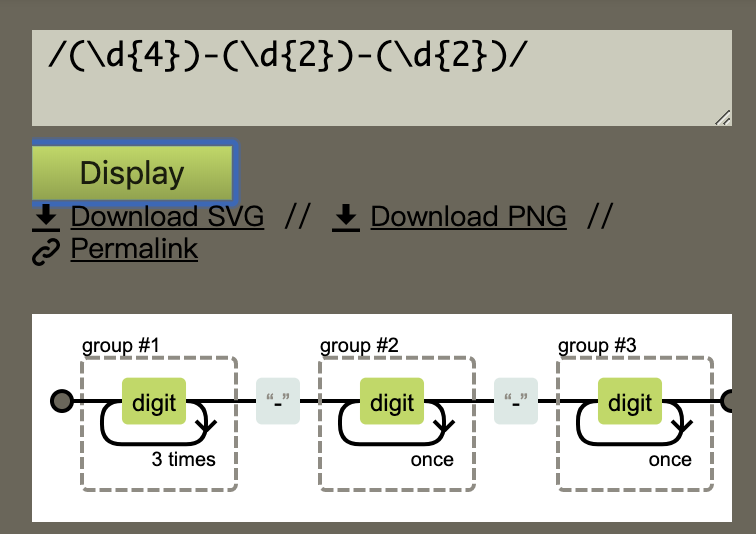
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log(regex.exec(string));
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
console.log(RegExp.$1); // "2017"
console.log(RegExp.$2); // "06"
console.log(RegExp.$3); // "12"
- 想把 yyyy-mm-dd 格式,替换成 mm/dd/yyyy 怎么做
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017"
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function () {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function (match, year, month, day) {
return month + "/" + day + "/" + year;
});
console.log(result);
// => "06/12/2017"
- 起到反向引用作用
- 比方说要匹配一个日期,它有可能分隔符为-、.、/、
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // false
- \1,表示的引用之前的那个分组
- \2 和 \3 的概念也就理解了,即分别指代第二个和第三个分组,\10表示第10个分组
- 如果真要匹配 \1 和 0 的话,请使用 (?:\1)0 或者 \1(?:0)。?:表示非捕获性分组
- 括号嵌套应该怎么算,以左括号为准
var regex = /^((\d)(\d(\d)))\1\2\3\4$/;
var string = "1231231233";
console.log( regex.test(string) ); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 1
console.log( RegExp.$3 ); // 23
console.log( RegExp.$4 ); // 3
- 如果引用了不存在的分组,正则不会报错,只是匹配 反向引用的字符本身。例如 \2,就匹配 "\2"。注意 "\2" 表示对 "2" 进行了转义。
var regex = /\1\2\3\4\5\6\7\8\9/;
console.log( regex.test("\1\2\3\4\5\6\7\8\9") );
console.log( "\1\2\3\4\5\6\7\8\9".split("") );
- 分组后面有量词的话,分组最终捕获到的数据是最后一次的匹配
var regex = /(\d)+/;
var string = "12345";
console.log( string.match(regex) );
// => ["12345", "5", index: 0, input: "12345"]
var regex = /(\d)+ \1/;
console.log( regex.test("12345 1") );
// => false
console.log( regex.test("12345 5") );
// => true
- 文中出现的括号,都会捕获它们匹配到的数据,以便后续引用,因此也称它们是捕获型分组和捕获型分支。非捕获性分组:(?:p)
- 匹配成对标签
var regex = /<([^>]+)>[\d\D]*<\/\1>/;
var string1 = "<title>regular expression</title>";
var string2 = "<p>just test bye bye</p>";
var string3 = "<title>wrong!</p>";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // false
- 举一些反向引用的示例
// 相邻字符串过滤重复
function distinct(string) {
return string.replace(/(.)\1+/g, '$1')
}
console.log(distinct("abbccc"))
// => "abc"
// 使用循环去掉重复出现的
function distinct(string){
while(/(.).*?\1/.test(string)) {
string = string.replace(/(.)(.*?)\1/, '$1$2')
}
return string;
}
console.log(distinct("abbacbc"))
// => "abc"
// 看当前字符是否会在后面出现,如果出现就删除
function distinct(string) {
return string.replace(/(.)(?=.*?\1)/g, '')
}
console.log(distinct("abbacbc"))
// => "abc"
// 这种实现方式有一个问题,就是重复字符只保留最后出现的字符。如果在原来字符串后面加个 "a" 变成 "abbacbca",最终结果却是 "bca"。
function distinct(string) {
return string.replace(/(.)(?<=\1.*?\1)/g, '')
}
console.log(distinct("abbacbc"))
// => "abc"
正则表达式的拆分
- 比如要匹配目标字符串 "abc" 或者"bcd"时,如果一不小心,就会写成 /^abc|bcd$/,而位置字符和字符序列优先级要比竖杠高。所以应该写成/^(abc|bcd)$/
- 假设我们要匹配每个字符为 "a、"b"、"c" 任选其一,字符串的长度为3的倍数,而如果我们写成 /^[abc]{3}+$/,所以应该是/^([abc]{3})+$/


- 用到的元字符总结如下:
- ^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、-
- 当匹配到上面这些元字符时,可以把每个字符进行转义
- 有些时候也可以视情况而定,比方说如果要匹配字符串 "[abc]" 时,可以写成 /\[abc\]/,也可以写成 /\[abc]/,总结来说跟字符组相关的元字符有 [、]、-。只需要在会引起歧义的地方进行转义
- =、!、:、-、, 等符号,只要不在特殊结构中,并不需要转义。
- 括号需要前后都转义的,如 /(123)/。
- 至于剩下的 ^、$、.、*、+、?、|、\、/ 等字符,只要不在字符组内,都需要转义的
正则表达式的构建
- 能够使用api解决的事情就不需要正则来处理
- 是否有必要构建一个复杂的正则表达式
- 如果使用括号仅仅是为了分组的话,尽是使用非捕获性分组
- 确定出独立字符,比方说:/a+/ 可以修改成 /aa*/
- 提取出分支中公共部分,比方说:/this|that/修改成 /th(?:is|at)/
- 减少分支的数量,缩小它们的范围,比方说:/red|read/ 可以修改成 /rea?d/。
- 其实一般的步骤就是针对每种情形,分别写出正则,然用分支把它们合并在一起,再提取分支公共部分,
正则在JS中的实践
- String#search
- String#split
- String#match
- String#replace
- RegExp#test
- RegExp#exec
- 字符串实例的那 4 个方法参数都支持正则和字符串。
- 下面的例子说明在使用search和match方法时,会把字符串转换成正则进行操作
var string = "2017.06.27";
console.log( string.search(".") );
// => 0
//需要修改成下列形式之一
console.log( string.search("\\.") );
console.log( string.search(/\./) );
// => 4
// => 4
console.log( string.match(".") );
// => ["2", index: 0, input: "2017.06.27"]
//需要修改成下列形式之一
console.log( string.match("\\.") );
// => [".", index: 4, input: "2017.06.27"]
console.log( string.match(/\./) );
// => [".", index: 4, input: "2017.06.27"]
console.log( string.split(".") );
// => ["2017", "06", "27"]
console.log( string.replace(".", "/") );
// => "2017/06.27"
- match返回结果的格式,与正则对象是否有修饰符 g 有关。(当没有匹配时,不管有无 g,都返回 null。有 g,返回的是所有匹配的内容。当正则没有 g 时,使用 match 返回的信息比较多。但是有 g 后,就没有关键的信息 index 了。)
var string = "2017.06.27";
var regex1 = /\b(\d+)\b/;
var regex2 = /\b(\d+)\b/g;
console.log( string.match(regex1) );
console.log( string.match(regex2) );
// => ["2017", "2017", index: 0, input: "2017.06.27"]
// => ["2017", "06", "27"]
function urlQueryToObject(source) {
var keys = {};
source.replace(/([^=&]+)=([^&]*)/g, function (full, key, value) {
keys[key] = (keys[key] ? keys[key] + ',' : '') + value;
});
return keys
}
- split方法不引人注目的两个点
-
- 它可以有第二个参数,表示结果数组的最大长度
var string = "html,css,javascript";
console.log( string.split(/,/, 2) );
// =>["html", "css"]
-
- 正则使用分组时,结果数组中是可以包含分隔符的:
var string = "html,css,javascript";
console.log( string.split(/(,)/) );
// =>["html", ",", "css", ",", "javascript"]
- replace方法的
- replace 有两种使用形式,这是因为它的第二个参数,可以是字符串,也可以是函数。
| 属性 | 描述 |
|---|---|
| $1,$2,…,$99 | 匹配第 1-99 个 分组里捕获的文本 |
| $& | 匹配到的子串文本 |
| $` | 匹配到的子串的左边文本 |
| $' | 匹配到的子串的右边文本 |
| ? | 美元符号 |
var result = "2,3,5".replace(/(\d+),(\d+),(\d+)/, "$3=$1+$2");
console.log(result);
// => "5=2+3"
var result = "2,3,5".replace(/(\d+)/g, "$&$&$&");
console.log(result);
// => "222,333,555"
var result = "2+3=5".replace(/=/, "$&$`$&$'$&");
console.log(result);
// => "2+3=2+3=5=5"
// 要把 "2+3=5",变成 "2+3=2+3=5=5",其实就是想办法把 = 替换成
=2+3=5=,其中,$& 匹配的是 =, $` 匹配的是 2+3,$' 匹配的是 5。
- 当第二个参数是函数时,我们需要注意该回调函数的参数具体是什么
"1234 2345 3456".replace(/(\d)\d{2}(\d)/g, function (match, $1, $2, index, input) {
console.log([match, $1, $2, index, input]);
});
// => ["1234", "1", "4", 0, "1234 2345 3456"]
// => ["2345", "2", "5", 5, "1234 2345 3456"]
// => ["3456", "3", "6", 10, "1234 2345 3456"]
| 静态属性 | 描述 | 简写形式 |
|---|---|---|
| RegExp.input | 最近一次目标字符串 | RegExp["$_"] |
| RegExp.lastMatch | 最近一次匹配的文本 | RegExp["$&"] |
| RegExp.lastParen | 最近一次捕获的文本 | RegExp["$+"] |
| RegExp.leftContext | 目标字符串中lastMatch之前的文本 | RegExp["$`"] |
| RegExp.rightContext | 目标字符串中lastMatch之后的文本 | RegExp["$'"] |
var regex = /([abc])(\d)/g;
var string = "a1b2c3d4e5";
string.match(regex);
console.log( RegExp.lastMatch );
console.log( RegExp["$&"] );
// => "c3"
// 正则判断一个数是不是质数
function isPrime(n){
return n<2?false:!/^(11+?)\1+$/.test(Array(n+1).join('1'))
}
- 先创建一个长度是n的字符串,里面铺满了1
- ^11+?表示以1开头,后面惰性匹配多个1
- \1+$反向引用 表示重复^11+?这段匹配到的内容
- 首先,惰性匹配的是一个1,也就是11,后面重复11的整数次,也就是重复2次4次6次...等等,如果刚刚好匹配到了,说明这个数能被整除,说明他不是质数。如果后面的字符串不能构成2的整数倍个11,那么第一轮惰性匹配失败。 接着第二轮惰性匹配,匹配11,也就是前面捕获的是111,那么后面就开始重复111的整数倍,如果刚刚好能匹配完,说明不是质数 接着第三轮,匹配111,捕获到1111,后面重复1111的整数倍 ... 直到不能再匹配,说明这个数就是质数
具体可参见老姚的《JavaScript正则迷你书》
