

众所周知,互联网从一开始就伴随着高并发的问题,高并发的解决方案除了应用分而治之的技术手段,还有就是在内存、硬盘、DB层面的折中处理,大家都知道访问数据的优先级:内存 磁盘 数据库;由此也催生了众多的缓存系统,例如memcache、redis等等;今天我们要说的zookeeper也是如此,有自己的缓存数据;
zookeeper的各个节点的分工不同,大致如下:
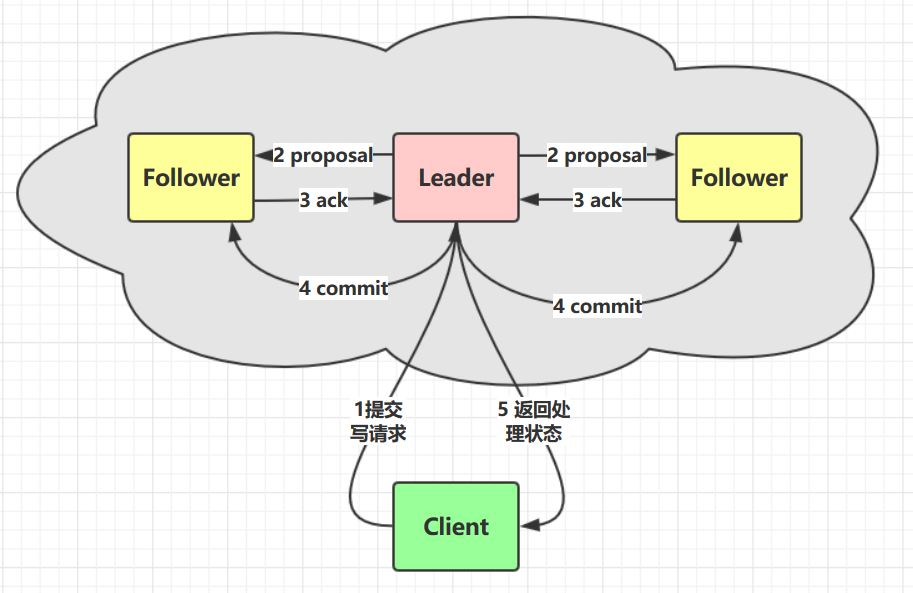
leader节点-处理事务与非事务请求;
follower节点-参与决议,转发事务请求;
observer节点-主要是分担系统负载的功能,不参与决议;
那么这些节点是如何进行数据同步的呢,也就是说,zookeeper在启动期间如何快速的完成节点之间的数据同步,来提供对外服务的呢;
zkdatabase.java 中有一个committedLog,它存放的已经提交的事务消息记录,最大存放500个这样的记录;
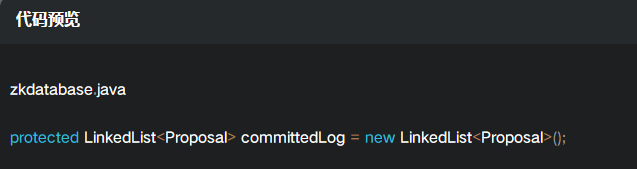
系统加载期间:
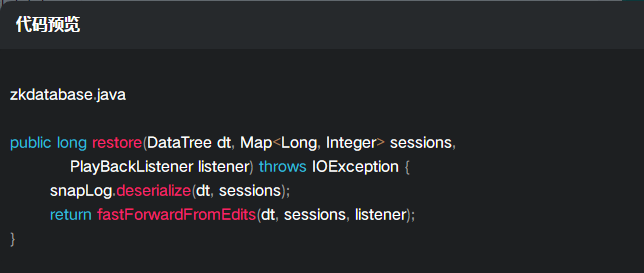
这里先从snapshot文件中反序列化出数据,然后再从增量事务日志中获取大于snapshot文件最大zxid的一些数据进行加载; 注意这里传入了一个PlayBackListener,它的含义是数据加载完后的监听处理工作;也就是说我们在初始化期间committedLog里面存放的事务消息,一定是在增量事务日志中的,而不存在snapshot文件中;我们看到在加载期间循环调用了onTxnLoaded
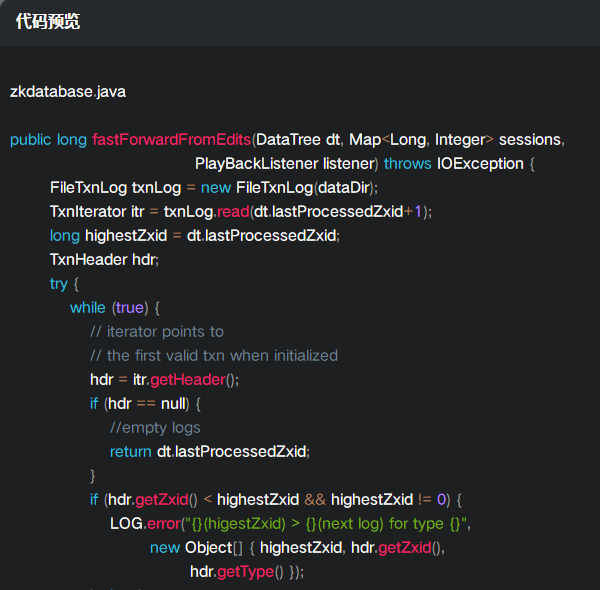
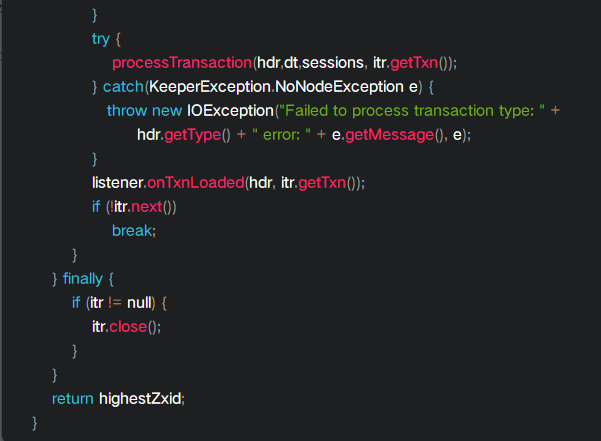
而onTxnLoaded的实例化函数如下:
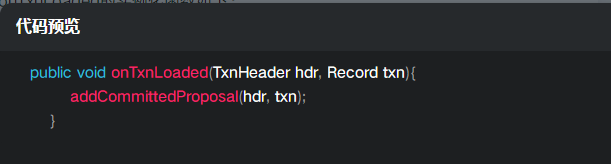
其实就是调用了addCommittedProposal;
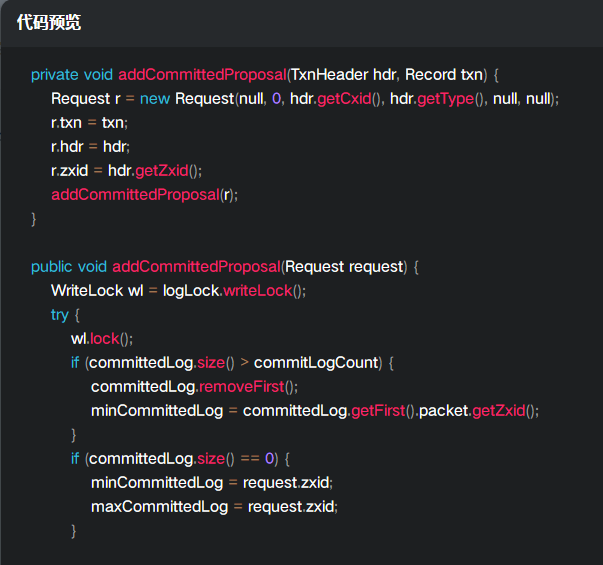
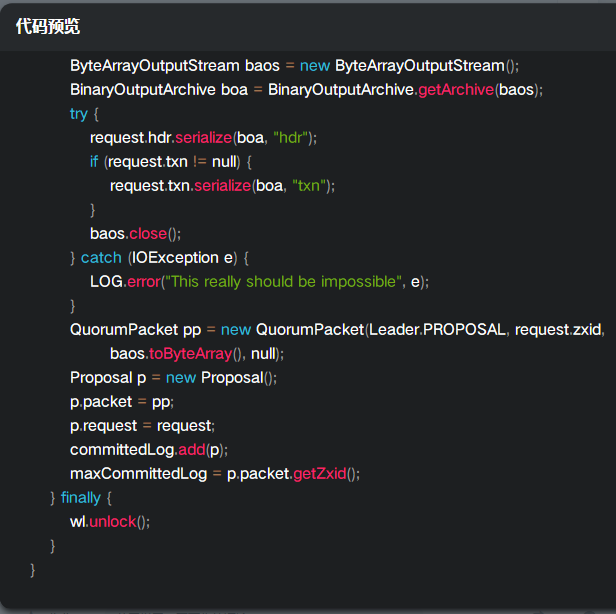
上述的本质是将事务消息封装为一个Request消息,然后存放到committedLog,然后更新了minCommittedLog和maxCommittedLog;committedLog 存放最大消息数量为500;
public static final int commitLogCount = 500;
加载完之后,就可以进行数据节点之间的选举流程和同步流程;
系统运行期间:
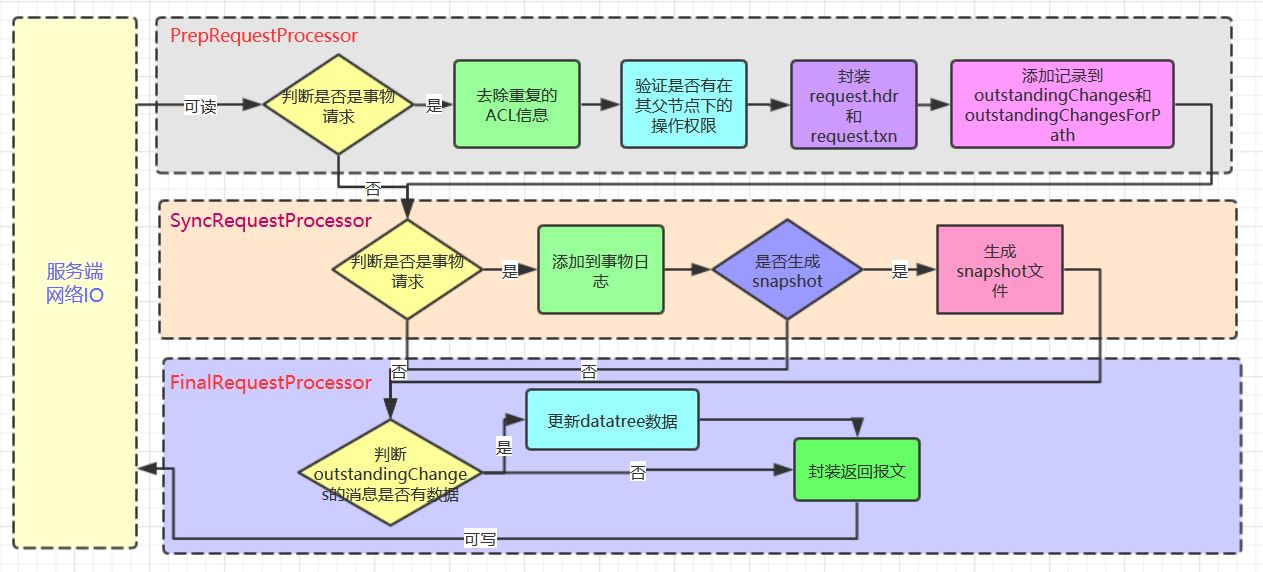
zookeeper的责任链的最后一个环节是FinalRequestProcessor,它处理完后,会去判断是否是事务请求,如果是事务请求则会将该消息添加到committedLog;
FinalRequestProcessor.java
if (Request.isQuorum(request.type)) {
zks.getZKDatabase().addCommittedProposal(request);
}
说白了,就是在运行期间,事务消息请求也会存放到committedLog中,那么这个committedLog在运行期间呢,就起到了一个非常关键的作用,就是数据同步;下节再讲一下初始化期间的同步规则。
