

写在前面:
学习的过程是对知识消化理解的过程,但往往只有转换成自己的语言表达出来,才能发现逻辑上的漏洞和缺失的细节。
下述内容纯粹作为自己学习理论知识的个人总结,不对正确性和准确性负责。
如果热心的你发现个人理解有问题并帮我指出来,个人将不胜感激,谢谢。
Java的内存模型的简单理解
首先,现代高速处理器为了缓解CPU运算速度与主存读取速度上的巨大差异,不得不引入读写速度尽可能接近CPU处理速度的高速缓存来作为缓冲。即先将使用到的数据复制到高速缓存,运算结束后再写会到内存中。
其次,JVM的内存结构中,方法区和堆内存区域属于所有线程可见并操作的区域,即多个线程可以同时进行读写这些区域的数据。这些区域的数据定义为共享变量。
第三,线程是CPU调度的最小单位,在存在CPU高速缓存的处理器上,在对共享变量进行读写运算时,实际操作的CPU高速缓存的数据,而非真实主内存中共享变量。在完成数据运算后,再将运算结果写会到主内存中,最终更新多线程可操作的共享变量的值。
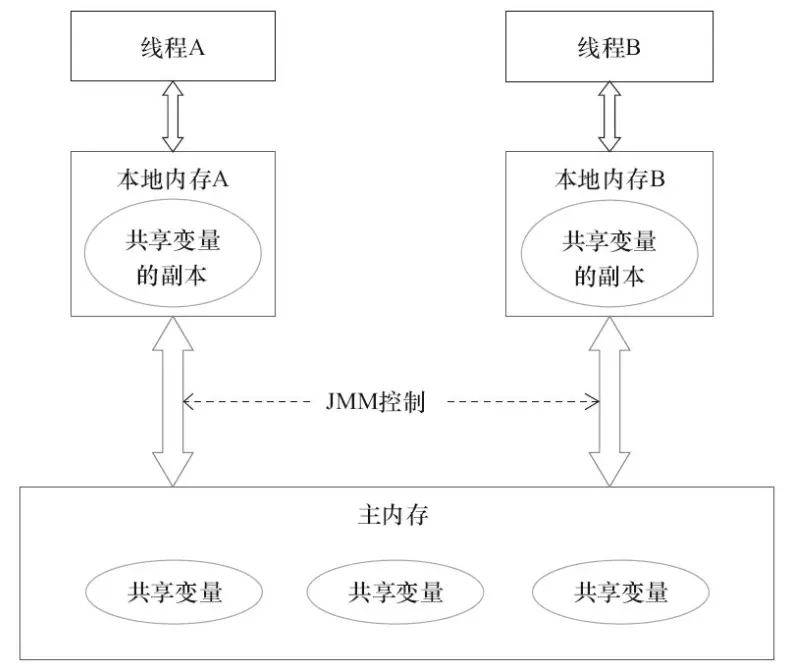
基于上述机制,JMM抽象出内存模型如下:
Java共享变量存储在主内存中,每个线程都有自己的工作内存。在运行时线程会从主内存中拷贝共享变量到自己的工作内存中,之后的读写操作都是对线程工作内存变量的操作,并在某个时刻将操作结果写会到主内存中。
Java内存模型实际上是在多处理系统中对内存和高速缓存进行读写访问的过程抽象,在实际物理上并不存在这种模型的直接实现。
Java内存模型主要围绕在并发过程中如何处理原子性、可见性和有序性三个特性,对虚拟机内存交互作出规范和定义。
模型如下所示:
重排序
为了尽可能提高指令执行的并行程度,编译器和处理器会在编译和指令运行阶段进行重新排序,以提高并行程度;
编译器重排序和处理器重排序都遵循数据依赖原则,即目标数据存在依赖关系的两个操作不能进行重排序;
重排序遵从as-if-serial: 线程内表现串行的语义,即不管如何重排序,单个线程内的运行结果不受影响;
Java内存模型中对lock/unlock的约定、volatile变量的规则,会通过volatile可见性、内存屏障实现对重排序的影响。
happens-before
又称为"先行发生"原则,主要定义了数据在多线程场景下的操作的偏序关系,通过其规则判断数据是否是线程安全的。用白话描述即为: 如果A操作先行发生于B操作,那么A操作的结果都能被操作B观察到。
happens-before规则有:
1. 程序次序规则;
2. 管程锁定规则;
3. volatile变量规则;
4. 线程启动规则;
5. 线程中断规则;
6. 线程终止规则;
7. 对象终结规则;
8.传递性规则.
