

大数据学习路线分享Scala系列之映射Map首先我们先来看一下什么是映射(map)
在Scala中,把哈希表这种数据结构叫做映射。
1. 构建映射
在Scala中,有两种Map,一个是immutable包下的Map,该Map中的内容不可变;另一个是mutable包下的Map,该Map中的内容可变。
构建一个不可变的map
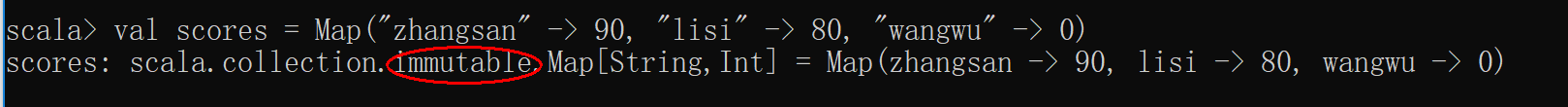
使用元组方式构建
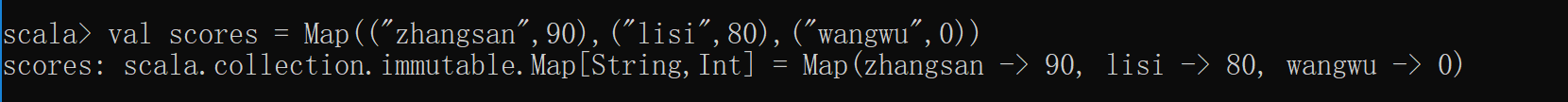
构建一个可变的map

2. 获取和修改映射中的值
根据键获取map中对应的值,可以有以下三种方法,尤其推荐使用getOrElse方法。

修改可变map信息,遍历访问map
object MappingDemo {
def main(args: Array[String]): Unit = {
val scores = scala.collection.mutable.Map ("zhangsan" -> 90, "lisi" -> 80, "wangwu" -> 0)
scores("wangwu") = 100
scores("zhaoliu") = 50
scores += ("sunqi" -> 60, "qianba" -> 99)
scores -= "zhangsan"
val res = scores.keySet
for(elem <- res)
print(elem + " ")
println()
for ((k,v) <- scores)
print(k+":"+v+" ")
}
执行结果

3. HashMap
可变map
import scala.collection.mutable
object MutMapDemo extends App{
val map1 = new mutable.HashMap[String, Int]()
map1("spark") = 1
map1 += (("hadoop", 2))
map1.put("storm", 3)
println(map1)
map1 -= "spark"
map1.remove("hadoop")
println(map1)
}
