

开宗明义:正则(regular expression)是干什么的?
- 正则表达式是用来处理字符串的,它的特长在于处理复杂的字符串。
- 正则表达式定义的是字符串的模型(或叫模式,英文pattern),我们可以使用这个模型来去验证某个字符串(或字符串里的一部分)是否和这个模型(或叫模式)相匹配,或使用这个模型把某个字符串里和这个模型匹配的那一部分找出来。
再重述一遍:1、正则定义了一个字符串的模型。2、正则的第一个作用是“验证某字符串是否和这个模型相匹配”。3、正则的第二个作用是“把匹配到的内容找出来”。
- 其实正则只是定义了一个字符串的模型,至于如何去验证字符串和查找字符串,是正则类上的方法完成的。
比如:var reg=/\d+/;
写在两个/斜杠之间,是语法规范,表示定义了一个正则对象。 \d在正则中表示数字,+表示出现一到多次。 那这样就定义了一个出现一到多次的数字的模型。 它可以和以下字符串匹配:”ab23839cd”,”a4d”、”33928”、”3490cf”、”0938FA”、”z9”,因为这些字符串里,都出现了一到多次的数字,如果用正则类的test方法去验证它们,都会返回true。
例:
var reg=/\d+/; //相当于定义了“一个数字出现一到多次”的模型
var str=”ab23839cd”;
alert(reg.test(str)); //弹出true
这里的test方法,是正则类的方法,以字符串为参数,就是负责验证str是否符合reg定义的模式。下面再定义一个字符串:
var str2=”abcdef”;
alert(reg.test(str2));//这次弹出的是false,因为str2里,没有出现数字。
以上只是验证字符串,如果想把符合验证的字符串找出来,则就要用其它方法了,例:
alert(reg.exec(str));//弹出23839
alert(reg.exec(str2));//弹出null,因为reg和str2不匹配。
当然,我也还可以用String类的match方法来找到和reg正则相匹配的内容,例:
alert(str.match(reg));//弹出23839
exec和match,都是处理字符串功能很强大的方法,后边的章节里会有非常详细的阐述。
如果严格的匹配一到多个数字,不能出现其它字符,应该这样写:
var reg=/^\d+$/;
这个模型才表示从开头到结尾都是数字。^表示后边出现的数字必须在开头,$表示前面出现的数字必须出现在结尾。
-
像^、$、\d、+这些在正则里表示特殊含义的符号,叫“元字符”。
在正则里,不是只允许出现元字符,普通的字符也是可以出现的。在正则里出现的普通字符,就表示此字符本来的含意。比如:
var reg=/^\d8\d$/;
//这个表示匹配一个只包含三位数字,中间是8的字符串。
详解:^\d表示以任意数字开头,一个\d表示出现一次;
中间的8就表示字符8本身, 后边的\d$表示一个任意数字结尾。
所以这个正则可以匹配以下这些字符串:”282”,”389”,”081”等
,但不匹配”1899”,”819”,”08”这样的字符串。
在/^\d8\d$/这个正则里,首尾的两个\d和中间的8,都表示一个字符,它们是组成正则的最基本单位,我们叫它们“原子”,\d是原子,8也是原子。 更多的基础知识,请看下面
一、定义正则
1、创建一个正则的两种方式:
var reg=/abcd/; //这个叫对象直接量方式
var reg=new RegExp(‘abcd’)//这个叫构造函数方式
这两种定义是一样的
2、如果有模式修正符,比如说全文查找abcd这个字符串,两种写法分别是(g是模式修正符,表示在整个字符串里多次查找)
var reg=/abcd/g;
var reg=new RegExp(‘abcd’,’g’);
3、有一种情况要注意,就是如果正则中出现了斜杠“\”(回车上边的斜杠),在用构造函数创建正则对象时,要转义,比如:
reg = new RegExp("\w+")//这里的\要转义 reg = /\w+/ //这样就不需要 这两种定义方式之间有什么区别,请参考在线视频
二、元字符常用例表
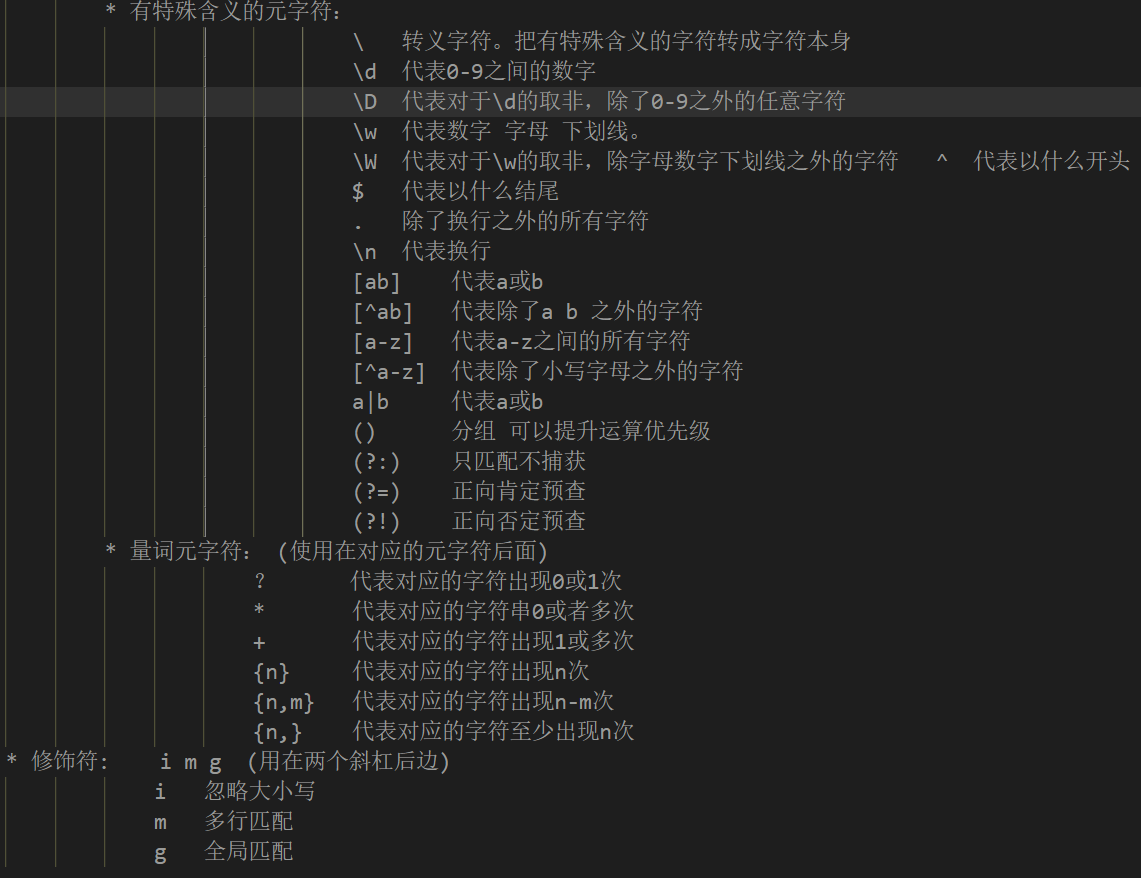
正则表达式的exec方法简介
语法:
reg.exec(str);
其中str为要执行正则表达式的目标字符串。例如:
<script type="text/javascript">
var reg = /test/;
var str = 'abcdtestString';
var result = reg.exec(str);
//result是个数组,result[0]保存的是正则匹配到的字符串”test”
alert(result);
</script>
将会弹出test,因为正则表达式reg会匹配str(即字符串:‘abcdtestString’)中的’test’的部分,并将’test’保存在一个数组的第一项中。然后把数组返回赋给result。
这里exec的返回值是一个length为1的数组:[“test”],当alert(result)的时候,系统会自动执行[“test”].toString()方法,所以我们见到的弹出结果是test。
补充:把上面的正则改一下:
<script type="text/javascript">
var reg = /(t)(e)(s)(t)/;//把test的每个字符都用小括号包起来
var str = 'abcdtestString';
var result = reg.exec(str);//现在result就变成[“test”,”t”,”e”,”s”,”t”]
alert(result);//弹出 test,,t,e,s,t
</script>
在正则中给每个原子加了括号,那就表示在一个大正则里,又出现了若干个子正则,那么exec不但要把总正则匹配到的字符找出来,还要把子正则里的字符也要找出来,依次放到数组里。关于子正则,这里先做简单了解即可,这会不必纠缠这个知识点。 exec是个很强大的方法,下面会有更详细的介绍
四、和正则相关的方法详解
exec方法详解 (重点和难点)
- 1、exec方法的返回值
-
exec方法的返回值是一个数组 var reg = /b/; var str='bbs.zhufengpeixun.cn'; var result = reg.exec(str);
我们使用for in循环来遍历一下这个数组有那些额外属性:
for(var attr in result){
console.log("reslut的属性:"+attr+",此属性的值:"+result[attr])
}
控制台中输出的结果是(写在【】里的是解释)
reslut的属性:0,此属性的值:b 【表示匹配到的结果存在索引0这个位置,即result[0]是'b'】
reslut的属性:index,此属性的值:0 【这个属性表示”b”在原字符串中的起始位置】
reslut的属性:input,此属性的值:bbs.zhufengpeixun.cn 【这个属性表示原字符串】
还有一个不可枚举的属性length没有被输出到控制台。如果正则中还有分组,则length的值就不是1了。比如:
var reg = /(\w)(\w)(\w)/ //不加模式修正符g。
var str='bbs.zhufengpeixun.cn';
var result=reg.exec(str);//exec执行两次,是为了配合本章第2小节的讲解
var result=reg.exec(str);//故意执行两次,如果没加修正符g,执行多少次,返回的结果都一样
for(var attr in result){
console.log("reslut的属性:"+attr+",此属性的值:"+result[attr])
}
结果为:
reslut的属性:0,此属性的值:bbs 【整个正则匹配到的内容】
reslut的属性:1,此属性的值:b 【第一个括号里的子正则匹配到的内容】
reslut的属性:2,此属性的值:b 【第二个括号里的子正则匹配到的内容】
reslut的属性:3,此属性的值:s 【第三个括号里的子正则匹配到的内容】
reslut的属性:index,此属性的值:0 【被匹配到的内容,出现在原字符串str中的位置】
reslut的属性:input,此属性的值:bbs.zhufengpeixun.cn 【原字符串str】
现在result.length的值是4,表示有四个匹配项被保存在result中,result[0]就是整个正则表达式所匹配的内容。后续的result[1]、result[2],result[3]则是各个子正则表达式(分组)的匹配内容。
2、exec方法对正则表达式的更新
exec方法在返回结果对象的同时,还可能会更新原来的正则(注意:是把正则对象给更新了),这就要看正则表达式是否设置了g修饰符。先来看两个例子吧:
var reg = /(\w)(\w)(\w)/g; //这里加了模式修正符g,表示要在全文内多次匹配查找
var str='bbs.zhufengpeixun.cn';
reg.exec(str); //exec第一次运行
var result=reg.exec(str); //注意这里:result是exec是第二次运行的返回值
for(var attr in result){
console.log("reslut的属性:"+attr+",此属性的值:"+result[attr])
}
输出的结果为:
reslut的属性:0,此属性的值:zhu 【字符.(点)与\w这个原字符的描述不能匹配,所以是zhu】
reslut的属性:1,此属性的值:z
reslut的属性:2,此属性的值:h
reslut的属性:3,此属性的值:u
reslut的属性:index,此属性的值:4 【表示’zhu’出现在str中的索引位置是4】
reslut的属性:input,此属性的值:bbs.zhufengpeixun.cn
可以看得出来,第二次执行exec方法还能继续匹配并查找,同样还可以进行第三次第四次的匹配和查找。这也就是g修饰符的作用了。如果是多次查找,那如何知道下一次从那个位置开始的呢?这就是正则(这个属性是正则对象的)的一个很重要的属性在发挥作用了,它叫:lastIndex。
- 每个正则实例上都会有一个叫lastIndex的属性,它的作用是规定当前这次的匹配的开始位置是从那儿开始的。
- 如果正则表达式没有设置模式修正符g,那么lastIndex的值永远是0,则表示无论这个正则被使用过多少次,每次都是从字符串0的位置去匹配。
- 所以第1小节中的exec方法虽然也是执行了两次,但对返回的值没有任何的影响,因为每次执行exec,都是从头开始的。
- 如果设置了g,那么exec执行之后会更新正则表达式的lastIndex属性,表示本次匹配后,所匹配字符串的下一个字符的索引,下一次再用这个正则表达式匹配字符串的时候就会从上次的lastIndex属性开始匹配,也就是上面两个例子结果不同的原因了。
一定要注意的是,lastIndex属性是正则对象的属性;而index属性和input属性是exec方法返回的那个数组的属性。
特别强调:两点,
- 一、即使正则设置了g修饰符,exec方法不会自动的进行全文查找,但会修改正则对象的lastIndex的值。
- 二、但它的特长在于不但可以捕捉到整个正则匹配的内容,还可以捕捉到子正则(分组)匹配到的内容,如果想把字符串所有的匹配项和子匹配项都取到(就是把总正则和子正则的匹配项都取到),那需要自定义下面一个这样的方法:
RegExp.prototype.autoExec=function (str){//定义在正则类上
//this是指当前执行autoExec方法的正则实例
if(this.global){//必须设置修正符g
this.lastIndex=0;//把lastIndex的值修正为0,以免reg被使用过
var a=[];//准备一个数组用来保存每一次捕获到的结果。
var result=null;
/*
//第一方法:用while循环。
while(result=this.exec(str)){//先执行exec(str),然后把返回值赋给result,最后判断result是否为null
a.push(result);
}
*/
do{//第二种方法用了do-while循环,并且判断的是lastIndex。你能理解吗?
a.push(this.exec(str))
}while(this.lastIndex);
return a;//如果有捕获结果,则会返回一个二维数组
}else{
throw new Error("未设置修正符g");
}
}
//要求:在str字符串中,把所有的完整的时间字符串和年月日时分秒都提取出来。
var str="times is 2013-11-2 12:03:36 ;
times is 1998-10-12 3:03:36;
times is 2012-11-03 12:22:34";
var reg=/(\d{4})-(\d{1,2})-(\d{1,2}) +(\d|[01]\d|[2][0-3]):(\d|[0-5]\d):([0-5]\d|\d)/g;
var r=reg.autoExec(str);
alert(r)
//结果是这样的一个二维数组:
[
["2013-11-2 12:03:36","2013","11","2","12","03","36"],
["1998-10-12 3:03:36","1998","10","12","3","03","36"],
["2012-11-03 12:22:34","2012","11","03","12","22","34"]
]
test方法
test方法仅仅检查是否能够匹配str,并且返回布尔值以表示是否成功。
实例1
var reg = /b/;
var str = 'bbs.zhufengpeixun.cn’;
alert(reg.test(str));
成功,输出true。
实例2
var reg = /9/;
var str = 'www.zhufengpeixun.cn';
alert(reg.test(str));
失败,输出false。
