

Hadoop
大数据处理的成熟框架,Yarn的引入解决了并行处理大量任务的资源瓶颈问题
Yarn到底做了什么
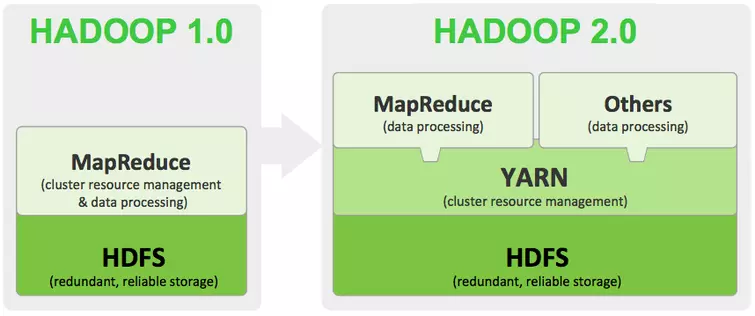
Hadoop V1.0中,数据处理和资源调度只要依赖MapReduce完成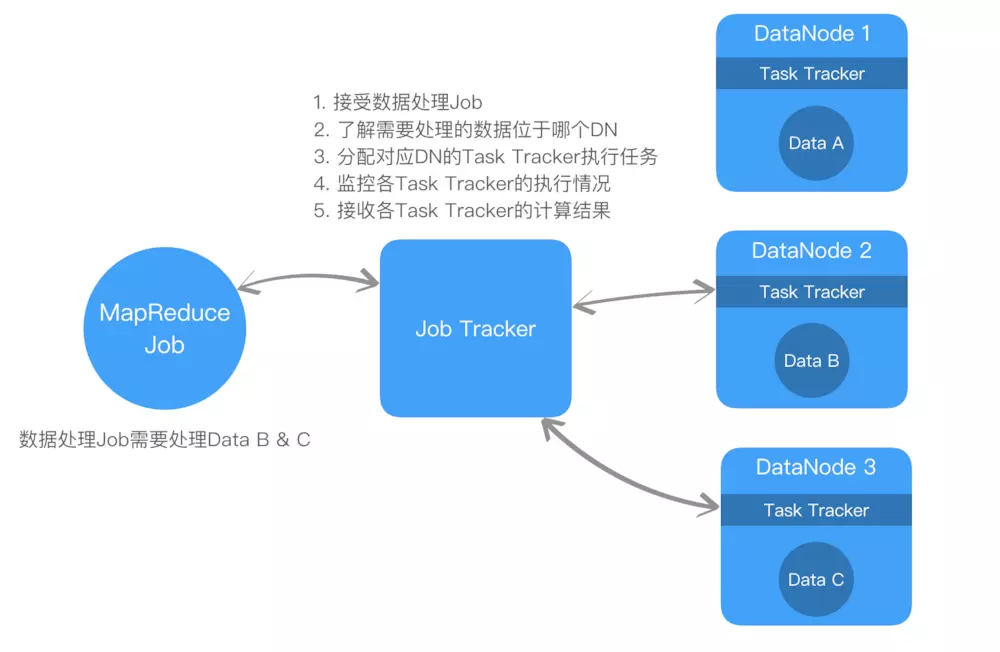
图示来看,MapReduce的综合数据处理提交给Job Tracker,
缺点: 1. 应对小规模数据流程OK,如果是大数据场景,同时处理大量Data Node,就Job Tracker由于无法均衡分配资源,非常容易成为系统瓶颈 2. 只能接收MapReduce的方式,技术栈只能是java
Yarn--解决方案
HadoopV2.0用Yarn(Yet Another Resource Negotiator),旨在分离资源管理和Job的调度监控
Yarn核心组件
全局组件
-
Resource Manager 全局统一的资源管理,调度,分配 由Scheduler和Application Manager组成,
Scheduler根据节点容量和队列情况为Application分配资源
Application Manager接收用户提交的请求,在节点中启动Applcation Master,监控其状态和必要的重启
-
Node Manager 代理监控节点上报资源使用情况给Resource Manager
Per-appliaction组件
- Application Master job的任务调度 Application Master与Resource Manager进行沟通,获取资源进行计算。得到资源后,与节点上的Node Manager进行沟通,在分配的Container汇总执行任务,并监控任务执行的情况.
- c**ontiner 资源抽象 ** 内存、CPU、磁盘、网络等,当Application Master向Resource Manager申请资源时,Resource Manager为Application Master返回的资源便是Container。
Yarn解决的痛点
- 通过Application Master 解决Job tracker的瓶颈问题,新任务提交后,Resource Manager在恰当的节点启动新的Applcation Master ,避免Job Tracker成为瓶颈
- 更有效的资源调度
- 支持MapReduce之外的数据处理方式,比如spark
Yarn的问题
大量任务提交后,用尽计算资源导致新job即使优先级很高,也需要等待很久才能被处理, 可以通过配置不同的资源调度规则[优先级]来缓解该问题,
Spark框架
先上杰伦:sparksql和hive都不直接计算,而是告诉各个节点计算任务,最后汇总计算结果
简介:Spark和MapReduce在同一个层级,解决分布式计算
架构:Driver Master Worker Executer
特点: 可部署在Yarn上 原生支持HDFS 使用Scala
部署模型: 单机模型 伪集群模型 独立集群(又叫做原生集群模式) YARN集群等
YARN集群:YARN生态中的ApplicationMaster角色使用Apache开发好的Spark ApplicationMaster代替,每一个YARN生态中的NodeManager角色相当于一个Spark生态中的Worker角色,由NodeManger负责Executor的启动。
关于Spark SQL
简介
两大组件:SQLContext和DataFrame
用于结构化数据处理(JSON,Parquet,carbon(Huawei),数据库),并执行ETL操作,最后完成特定的查询. 一般来说,Spark没支持一种新的应用开发,都会引入一个新的Context和响应的RDD
sql支持
解析(parser)、优化(optimizer)、执行(execution)
处理顺序:
-
SQlParser生成LogicPlan Tree;
-
Analyzer和Optimizer将各种Rule作用于LogicalPlan Tree;
-
最终优化生成的LogicalPlan生成SparkRDD;
-
最后将生成的RDD交由Spark执行;
Hive On Spark
简介: 从Hive on MapReduce演进而来,将Spark作为Hive的计算引擎,提交到Spark集群上运算,提高HIve查询性能
和SparkSQL区别 都是在Spark上实现SQL的解决方案,sql引擎不同 都是一个翻译层,把一个sql翻译成分布式的可执行的Spark程序 比如
SELECT item_type, sum(price)
FROM item
GROUP item_type;
步骤:
上面这个SQL脚本交给Hive或者类似的SQL引擎,它会“告诉”计算引擎做如下两个步骤:读取item表,抽出item_type,price这两个字段;对price计算初始的SUM(其实就是每个单独的price作为自己的SUM)因为GROUP BY说需要根据item_type分组,所以设定shuffle的key为item_type从第一组节点分组后分发给聚合节点,让相同的item_type汇总到同一个聚合节点,然后这些节点把每个组的Partial Sum再加在一起,就得到了最后结果。不管是Hive还是SparkSQL大致上都是做了上面这样的工作。
