

Lucene搜索
-
普通数据库like的缺陷
答:
- 没有高效的索引,大量数据下查询很慢
- 只能完整关键字首尾模糊匹配
- 输入稍有差池,就匹配不到结果
2.
luence是什么
答:
用于全文检索和搜寻的开源程序库,不是产品,但可以提供制作搜索引擎产品!
-
Lucene小Demo
1. 引入依赖
<dependencies>
<!-- Junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- lucene核心库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.2</version>
</dependency>
<!-- Lucene的查询解析器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>4.10.2</version>
</dependency>
<!-- lucene的默认分词器库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.2</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>4.10.2</version>
</dependency>
</dependencies>
- 代码实现
@Test
public void indexCreate() throws IOException {
// 创建文档对象
Document document = new Document();
// 添加字段,参数Field是一个接口,要new实现类的对象(StringField, TextField)
// StringField的实例化需要3个参数:1-字段名,2-字段值,3-是否保存到文档,Store.YES存储,NO不存储
document.add(new StringField("id", "1", Store.YES));
// TextField:创建索引并提供分词,StringField创建索引但不分词
document.add(new TextField("title", "谷歌地图之父跳槽FaceBook", Store.YES));
// 创建目录对象,指定索引库的存放位置;FSDirectory文件系统;RAMDirectory内存
Directory directory = FSDirectory.open(new File("C:\\tmp\\indexDir"));
// 创建分词器对象
Analyzer analyzer = new StandardAnalyzer();
// 创建索引写入器配置对象,第一个参数版本VerSion.LATEST,第一个参数分词器
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
//设置索引模式 覆盖CREATE或者追加OpenMode.APPEND
conf.setOpenMode(OpenMode.CREATE)
// 创建索引写入器
IndexWriter indexWriter = new IndexWriter(directory , conf);
// 向索引库写入文档对象
//添加多个文档对象 addDocuments(docs);
indexWriter.addDocument(document);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();}
3. 打开索引查询工具run.bat即可看到
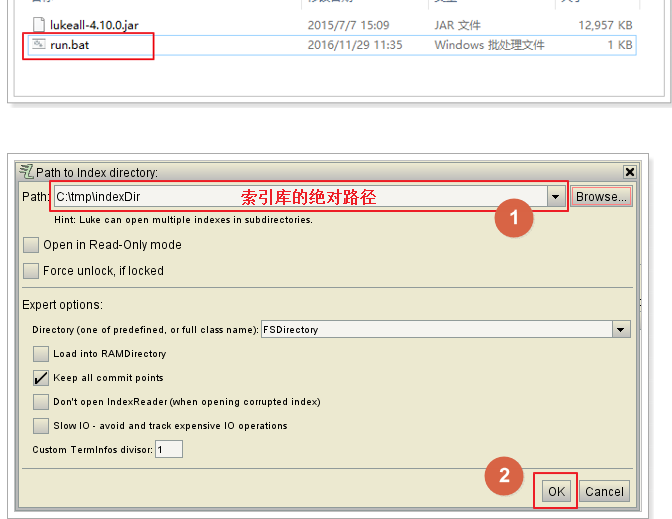
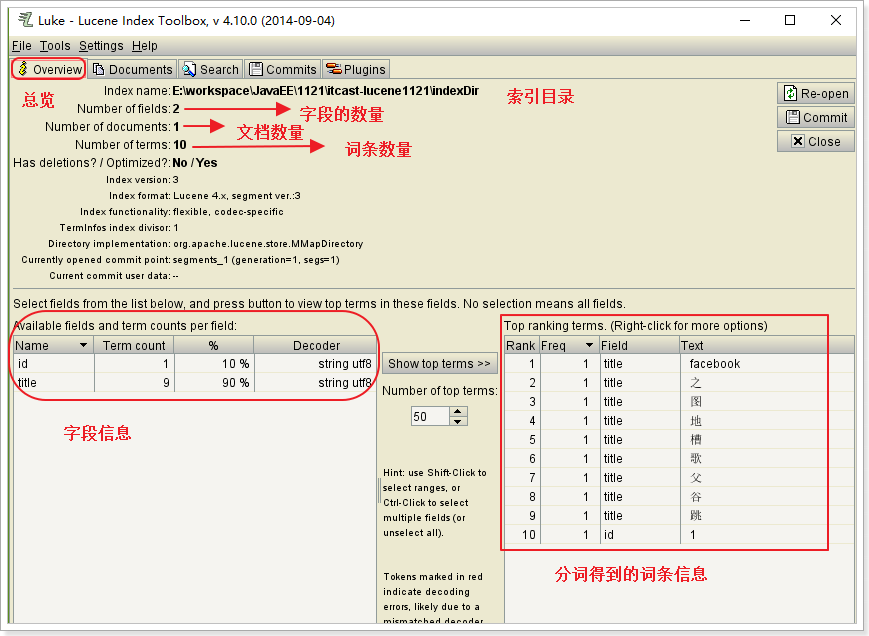
- 索引 DoubleField、FloatField、IntField、LongField、StringField、TextField这些子类一定会有索引,但不一定被存储到文档列表,需要通过构造函数的布尔参数指定
- 索引+分词 TextField 索引+分词, StringField只创建索引 不分词掉膘必须完全匹配用户输入
- 存储 StoreField一定被存储,而且一定不创建索引
Tips: 问题1:如何确定一个字段是否需要存储?
答:如果字段需要被显示到最终的结果中
问题2:如何确定一个字段是否需要创建索引?
答:如果要根据这个字段搜索
问题3:如何确定一个字段是否需要分词?
答:需要分割的字符串
-
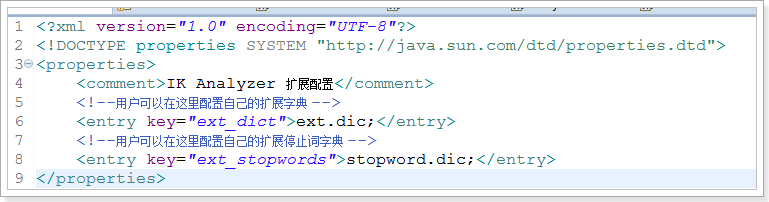
IK分词器的特性
- 自定义词库 扩展词典 停用词典
-
查询索引数据
@Test
public void testSearcher() throws IOException, ParseException{
// 初始化索引库对象
Directory directory = FSDirectory.open(new File("C:\\tmp\\index"));
// 索引读取工具
IndexReader indexReader = DirectoryReader.open(directory);
// 索引搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 单一字段"title"查询解析器对象
QueryParser parser = new QueryParser("title", new IKAnalyzer());
// 创建查询对象
Query query = parser.parse("谷歌");
// 执行搜索操作,返回值topDocs包含命中数,得分文档
//打分排序后前N名结果,这里是全部,用最大整数限制
TopDocs topDocs = indexSearcher.search(query, Integer.MAX_VALUE);
// 打印命中数
System.out.println("一共命中:"+topDocs.totalHits+"条数据");
// 获得得分文档数组对象,得分文档对象包含得分和文档编号
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
System.out.println("得分:"+scoreDoc.score);
// 文档的编号
int doc = scoreDoc.doc;
System.out.println("编号:"+doc);
// 获取文档对象,通过索引读取工具
Document document = indexReader.document(doc);
System.out.println("id:"+document.get("id"));
System.out.println("title:"+document.get("title"));}
-
Luence核心API
- QueryParser 查询解析器
- MultiFieldQueryParser
- Query 查询对象,存储了查询的关键字,通过子类,后续直接实现高级查询
- IndexSearcher(query,N) 索引搜索对象 执行搜索功能(快速搜索和排序等)
- TopDocs Searcher的结果集 包含totalHits命中数和scoreDocs
- ScoreDocs 得分文档对象 int doc编号和float score文档得分 doc编号用来获得文档Document doc=reader.document(doc)
-
特殊查询
- TermQuery(词条查询)
- WildcardQuery(通配符查询)
- FuzzyQuery(模糊查询)
- NumericRangeQuery(数值范围查询)
- BooleanQuery(组合查询)
-
修改和删除索引
/** * 更新索引 * 本质先删除再添加 * 先删除所有满足条件的文档,再创建文档 * 因此,更新索引通常要根据唯一字段 * @throws IOException */@Test public void testUpdate() throws IOException{ // 创建文档对象 Document document = new Document(); document.add(new StringField("id", "9", Store.YES)); document.add(new TextField("title", "谷歌地图之父跳槽FaceBook", Store.YES)); // 索引库对象 Directory directory = FSDirectory.open(new File("C:\\tmp\\index")); // 索引写入器配置对象 IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer()); // 索引写入器对象 IndexWriter indexWriter = new IndexWriter(directory, conf); // 执行更新操作 indexWriter.updateDocument(new Term("id", "1"), document); // 提交 indexWriter.commit(); // 关闭 indexWriter.close();} /* 删除索引 */ @Test public void testDelete() throws IOException { // 创建目录对象 Directory directory = FSDirectory.open(new File("C:\\tmp\\indexDir")); // 创建索引写入器配置对象 IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer()); // 创建索引写入器对象 IndexWriter indexWriter = new IndexWriter(directory, conf); // 执行删除操作(根据词条),要求id字段必须是字符串类型 // indexWriter.deleteDocuments(new Term("id", "5")); // 根据查询条件删除 // indexWriter.deleteDocuments(NumericRangeQuery.newLongRange("id", 2l, 4l, true, false)); // 删除所有 indexWriter.deleteAll(); // 提交 indexWriter.commit(); // 关闭 indexWriter.close();} -
特殊功能
- 高亮
- 排序
- 分页
- 得分算法
