

一、 背景介绍
Xunsearch 是一个高性能的检索引擎,主要对词进行切词+索引搜索。 而Tars是腾讯开源的微服务的框架架构。 体系很完整
二、 文章的收集
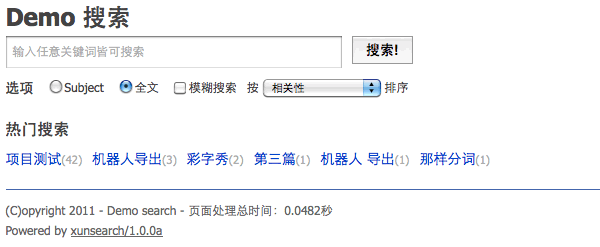
2.1 xunsearch 的一个高性能的检索解决方案
对于全文搜索引擎的处理非常的重要的。 全文搜索引擎主要是服务于文章的搜索和数据的具体的处理。 对于整体的文件的使用和查找都是非常重要的点。
对于全文搜索的操作,可以考虑轻量级的迅搜(xunsearch)、coreseek(sphinx变种,支持中文搜索),适用于中小型应用,还有适用于大型应用的 Elasticsearch
-
PHP SDK的组件包。 查看
-
基于迅搜(xunsearch) + Laravel Scout 实现 Laravel 学院全文搜索功能(支持多模型搜索) 查看
-
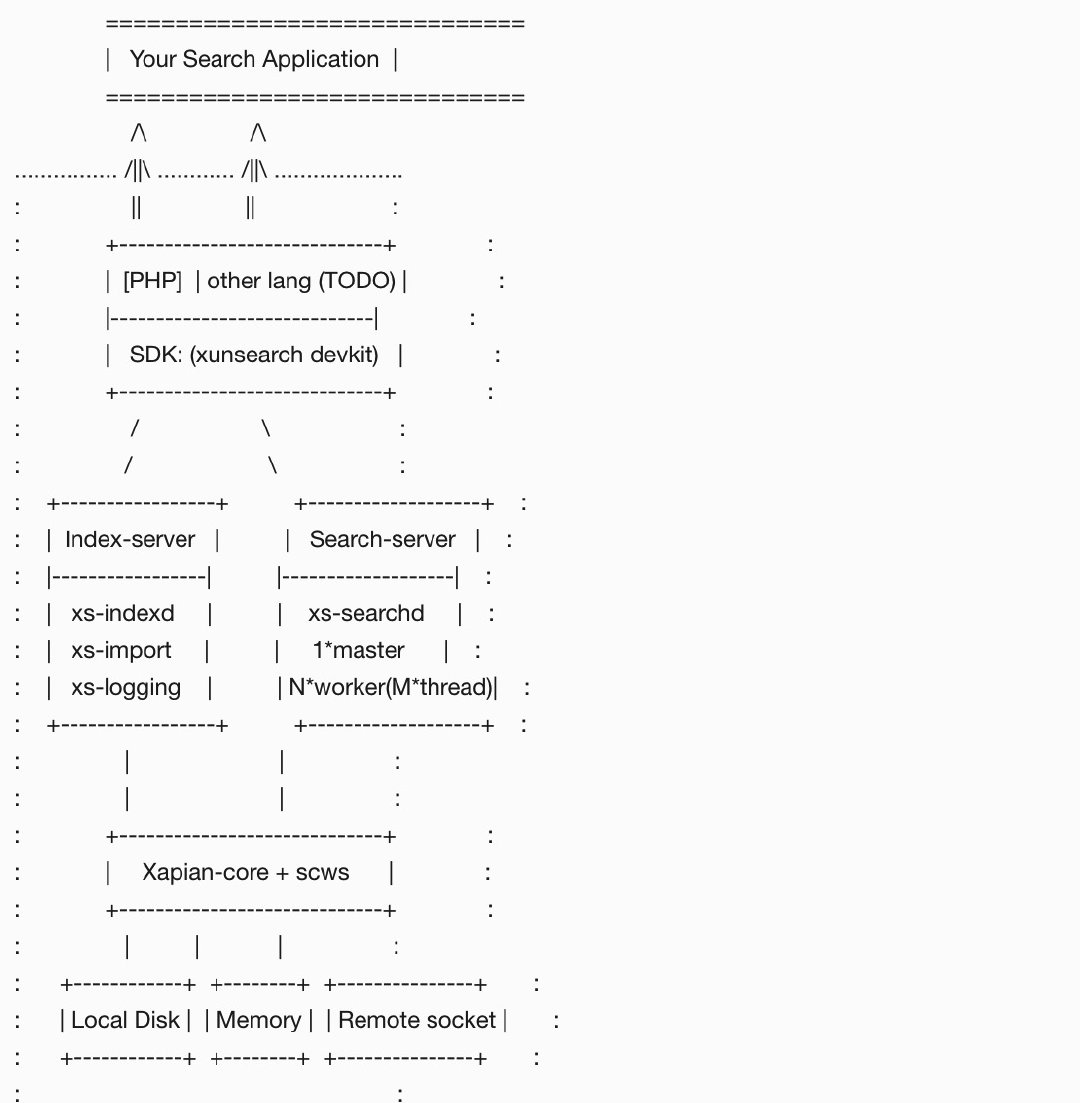
xunsearch的机制和原理
-
SCWS 中文分词逻辑, 查看
- 默认的单字切分。举个例子,有以下句子:“我们在吃饭呢”,则按字切分为[我]、[们]、[在]、[吃]、[饭]、[呢]。按这种方法分词所得到的term是最少的,因为我们所使用的汉字就那么几千个。
- 二元切分,即以句子中的每两个字都作为一个词语。继续拿“我们在吃饭呢”这个句子作例子,用二元切分法会得到以下词:[我们]、[们在]、[在吃]、[吃饭]、[饭呢]。
- 按照词义切分。这种方法要用到词典,常见的有正向最大切分法和逆向最大切分法等。我们再拿“我们在吃饭呢”作为例子。使用正向切分法最终得到词语可能如下:[我们]、[在吃]、[饭]、[呢],而使用逆向最大切分法则可能最终得到以下词语:[我们]、[在]、[吃饭]、[呢]。
- 基于统计概率切分。这种方法根据一个概率模型,可以从一个现有的词得出下一个词成立的概率,也以“我们在吃饭呢”这个句子举个可能不恰当的例子,假设已经存在[我们]这个词语,那么根据概率统计模型可以得出[吃饭]这个词语成立的概率。当然,实际应用中的模型要复杂得多,例如著名的隐马尔科夫模型。
-
SCWS的分词框架, 查看
-
Xapian 是一个用C++编写的全文检索程序, 他的作用类似于java的lucene ,查看
2.2 TARS-PHP:PHP构建高性能RPC框架,查看
腾讯开源的tars的产品系统,可以更好的支持业务的扩展和逻辑处理。
-
tars php环境搭建, 查看
-
tars php 的详细介绍,查看
-
TARS-腾讯开源微服务架构技术揭秘 ,[查看](file:///Users/Macx/Downloads/PPT-TARS-%E8%85%BE%E8%AE%AF%E5%BC%80%E6%BA%90%E5%BE%AE%E6%9C%8D%E5%8A%A1%E6%9E%B6%E6%9E%84%E6%8A%80%E6%9C%AF%E6%8F%AD%E7%A7%98%20%E9%92%9F%E7%A7%91.pdf)
2.3 thinkphp 支持多多模块的操作,查看
-
针对api的版本需要支持多个API的方式,并且对数据的库的操作。

九、 遇到的问题
- web手机唯一标识码的识别
- Fingerprinting 的识别操作 ,查看
- 其他的方式处理,[查看
