

1. 背景介绍
memcache 是很早的一种缓存机制,这个缓存主要是用内存来提高数据缓存的访问量和并发处理量。 个人的理解, 它的数据格式是key和value的格式,value支持多种形式的数据格式,可以是数组,对象字符等类型。 而memcache关键是一种建立在内存的缓存机制,所以关键还是对内存的的使用和利用。直接把输入流的数据直接进入内存,然后给数据分配内存空间,对于长期不使用的数据可以根据LRU算法,清理完成。
1.1 定义
- memcached是一个高性能,分布式的内存对象缓存系统,通常是本质上的,但最初用于通过减轻数据库负载来加速动态Web应用程序。
1.2 目的是什么?
提供一套高效的基于内存的缓存服务。
- 解决key和value的内存存储,提高存储性能
- 解决高并发的处理机制,采用Libevent事件模型
- 解决珍贵的内存资源的管理,
- 采用LRU,最少使用的内存,把其序列化到辅助存储(硬盘,磁盘)。 LRU 在分配的容量基础上,计算容量池中最少使用的资源,然后把资源进行消耗。
- 内存分配的算法提供,采用Slab算法,主要是提前分配一些内存区域,可以根据存储的数据大小直接存放。 在设置的支持最大内存的基础进行chunk分块。(具体可以根据业务的存储数据大小来调优) 如2G内存,按照1M分块,这样可以分为2048块。 在1M的分块里面,我们可以采用1,2,4,... 来申请相应的内存区域来方便数据的存储。 至于是否可以使用虚拟内存算法解决内存碎片的问题,这个还需要深入的了解下。
2. 机制/工作原理 ,查看
工作原理,是建立在提供高效的内存缓存服务机制上一套缓存机制。
工作原理:基于客户端和服务端模式,客户端发送key/value 数据服务请求,服务端接收客户端的数据请求处理,并返回相应的结果。 具体的处理机制如下:
- 客户端发送大量的数据请求给memcache
- memcache 先给这些数据放进kqueue队列中, 然后基于libevent I/O多路复用算法,采用异步非阻塞的启动多线程,进行数据的存储。 对于数据查询和存储,对于数据存储OK,返回数据的结果集
- memcache 需要对于存储的内存的数据进行管理,提高内存的使用效率。 主要的算法采用LRU算法机制,根据容量池中中使用次数最少的进行淘汰,或者说是命中最少的数据进行淘汰。
- memcache 的缓存命中,主要是采用hash算法,对于已经覆盖的hash桶,分配一块更大的hash区域,然后进行重新散列。 最后根据这些数据进行充分的利用。
3. 作用
3.1 高效的缓存机制
3.2 提高memcache的集群,提高memcache的高可用。
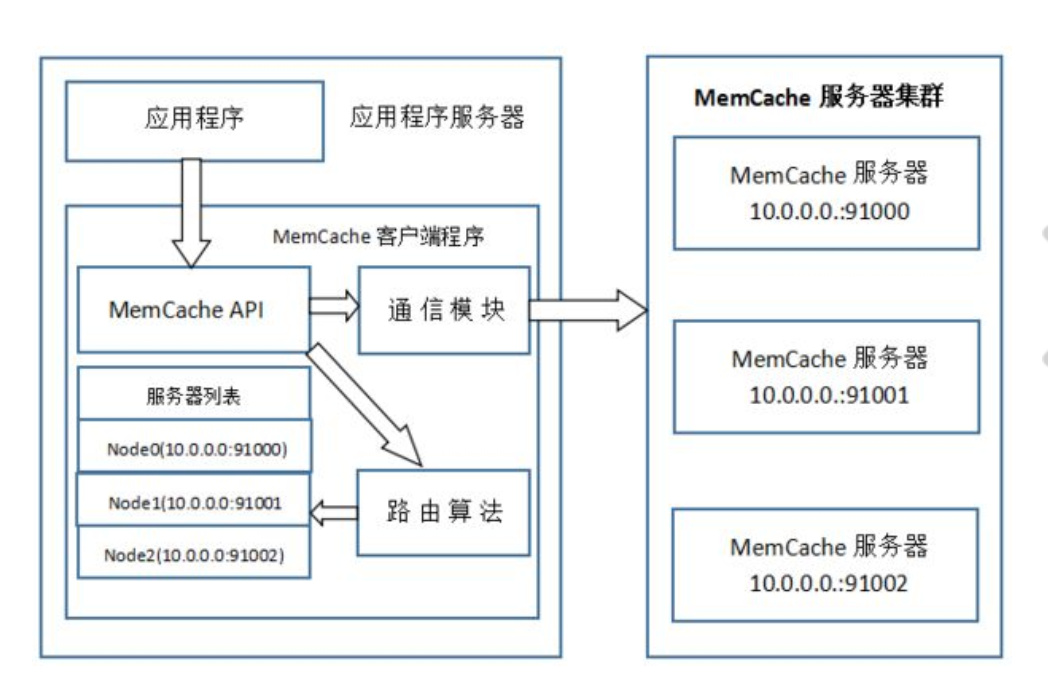
4. 存在什么风险? 优缺点
4.1 memcache集群中有一个节点失效了,这样会影响到hash值的不正确。影响整个hash的效果
那么我们还可以从数据库及服务端再次计算得到该数据,并将其记录 在其它可用的Memcached实例上。
- 采用一致性hash, 就是把多个实例的hash 分布在不同的实例,一个实例挂掉了,不会影响到所有实例的重新计算的问题。
4.2 缓存失效的问题,会导致服务器实例和数据库过载的情况。
在设计缓存的时候,我们采用超出需求容量的方法来定义缓存。 如果需要5个memcahed的节点,我们会设计一个6个节点的服务端缓存系统,以增加整个系统的容错能力。

4.3 不能够很好的日志序列话,对于节点崩溃不能很好的更加日志进行恢复?
4.4 Memcache安装的坑,Memcache有两个客户端版本一个是memcache,另外一个是memcahed(新),新客户端扩展需要安装libmemcached,查看
- mac中安装并配置memcached ,查看
1. memcached的机制
wget https://launchpadlibrarian.net/165454254/libmemcached-1.0.18.tar.gz
tar -zxvf libmemcached-1.0.18.tar.gz
cd libmemcached-1.0.18
phpize
./configure --prefix=/usr/lib/libmemcached --with-memcached
Configuration summary for libmemcached version 1.0.18
* Installation prefix: /usr/lib/libmemcached
* System type: apple-darwin16.7.0
* Host CPU: x86_64
* C Compiler: Apple LLVM version 8.1.0 (clang-802.0.42)
* C Flags: -g -O2
* C++ Compiler: Apple LLVM version 8.1.0 (clang-802.0.42)
* C++ Flags: -g -O2
* CPP Flags: -fvisibility=hidden
* LIB Flags:
* Assertions enabled: no
* Debug enabled: no
* Shared: yes
* Warnings as failure: no
* SASL support: yes
* make -j: 9
* VCS checkout: no
---
5. 概念的解析
5.1 一致性hash算法,查看
采用2的32次方,常见的是4个G的使用内存使用空间。 一直性hash在分布式哈希实现过程中充当了非常重要的角色。 它有什么要求?
- 所有的hash 尽可能的分布在所有的缓冲区中。这样避免hash分配不均,影响hash的效率。(平衡性)
- 对于节点的失效和出现问题是正常的情况,而怎么来保证新增和失效的节点是一致有效的,这样需要保证实例受到影响不会影响其,已有的实例的hash变化。 (单调性)
- 对于增加的实例的节点会靠近改实例的内容里面,并且对于新增或者删除实例都会对hash进行顺时针的迁移。
- 跟平衡性相似,整理更多的是解决,hash的分散性。 尽可能的把hash分散,并提供统一的节点视图,这样就解决相同的内容映射到不同的终端和缓冲区中。
- 负载:根据实际情况,减少实例机器的压力。 并提供过载扩容。
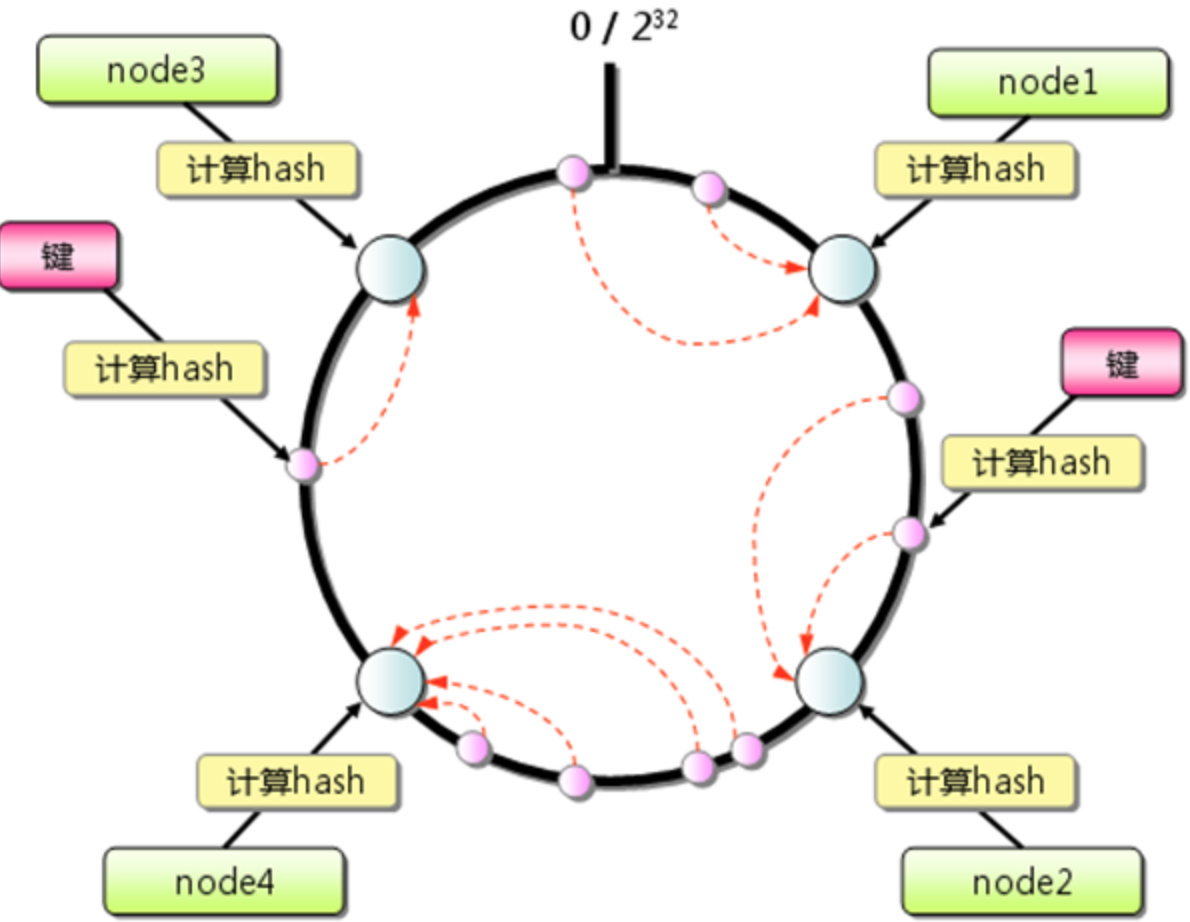
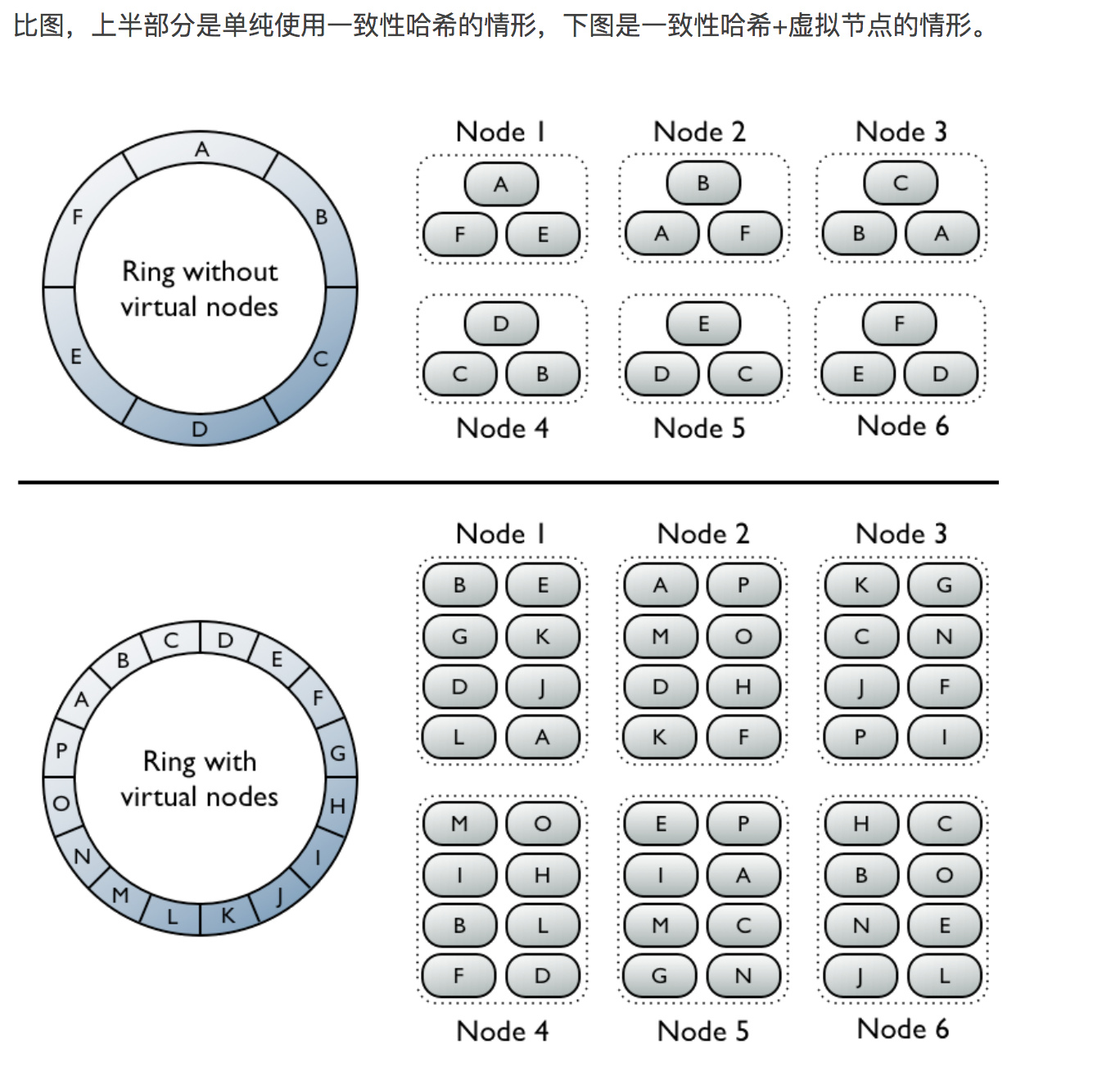
5.2 一致性hash与虚拟节点的关系
提供虚拟节点的方式,给每个节点提供多份副本,这样即使一个几点挂掉了,可以在相邻的节点调用相应的服务。
6. Case
6.1 阿里的LRU算法模式
附:阿里2014笔试题一道:
某缓存系统采用LRU淘汰算法,假定缓存容量为4,并且初始为空,那么在顺序访问一下数据项的时候:1,5,1,3,5,2,4,1,2出现缓存直接命中的次数是?,最后缓存中即将准备淘汰的数据项是?
答案:3, 5
解答:
1调入内存 1
5调入内存 1 5
1调入内存 5 1(命中 1,更新次序)
3调入内存 5 1 3
5调入内存 1 3 5 (命中5)
2调入内存 1 3 5 2
4调入内存(1最久未使用,淘汰1) 3 5 2 4
1调入内存(3最久未使用,淘汰3) 5 2 4 1
2调入内存 5 4 1 2(命中2)
因此,直接命中次数是3,最后缓存即将准备淘汰的数据项是5
