

面向墙外编程系列001:GOTOCON : 函数式编程 made simple

👨💻 Conference : GOTOCON 2018
👤 Speaker : Russ Olsen[1]
🔗 Original Link : GOTO 2018 • Functional Programming in 40 Minutes • Russ Olsen[2]
🏷 Tags : 函数式编程
函数式编程已经不是一个新概念了,最早可以溯源到上世纪五十年代的 Lambda calculus[3] 和 Lisp 。尽管如此,人们对函数式编程存在一定误解:学术性质太强,并且非常复杂。实际上并非如此,你将会看到函数式编程的思想其实非常简单。
学习函数式编程需要丢弃所有你所知道的编程思想吗?这种说法部分正确,因为函数式编程思想的确很不一样。但是这等于是把函数式编程过度神化了,函数式编程和面向对象一样,都只是一种为了降低代码复杂度的编程模式。面向对象很成功,但是代码依旧很复杂,函数式编程是一种完全不同的 approach,也许能做得更好。
先来梳理一下我们熟知的构成程序的概念有哪些:
- 变量、赋值、循环、控制流
- 基本数据类型:string integer
- 组合数据类型:arrays、hashes
- namespace
- classes、继承、方法
- 最上层的,就是最终的 program。
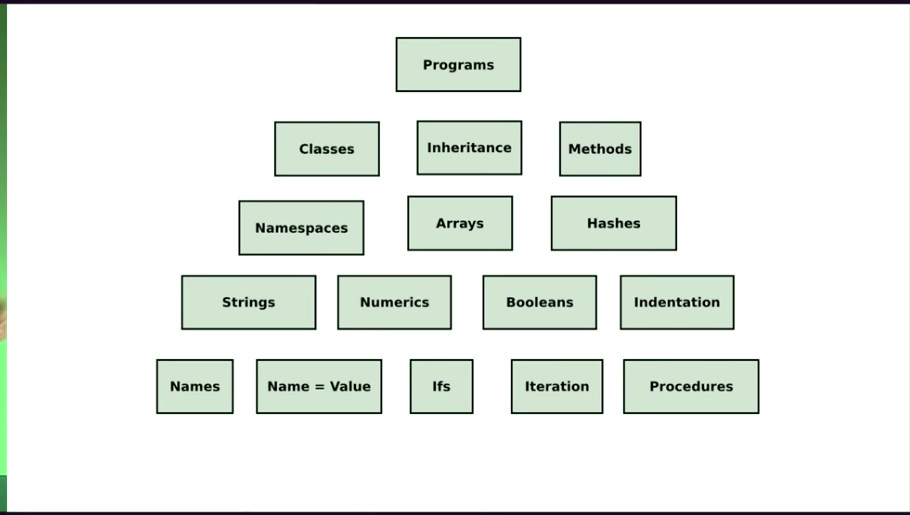
难道我们要把这些概念也丢弃吗?显然不能,所以,学习函数式编程不是从零开始,把它看作是对已有编程概念的 重构 更加恰当。
与其说学习函数式编程要 “Forget everything you know about programming”,不如说要 “Refactor everything you know about programming”。
一个应用程序的重构过程
假设你在开发下面这个程序。
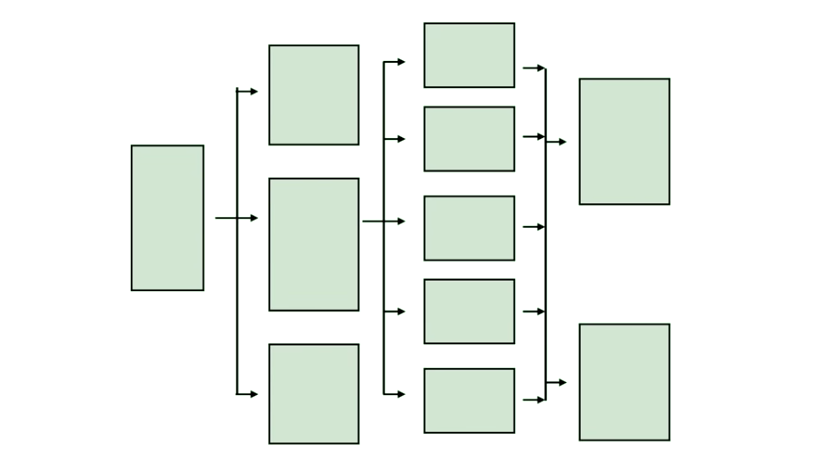
最开始程序 works ,但是随着时间发展,需求变更,你需要添加新的模块、删除某些不需要了的模块,还需要在不同模块之间修改依赖关系。 一段时间后,it works ,but in a mess。
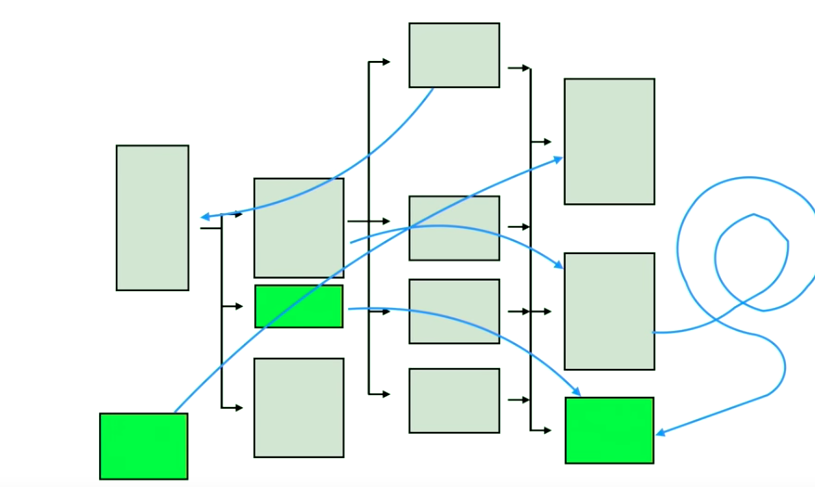
现在坐下来,从一张白纸开始,重新重构应用:

但是有趣的是,当我们要重构一个系统的时候,并不会真的从头开始,重写所有代码。我们做的是,把之前 works 的组件抽出来,重新组织。
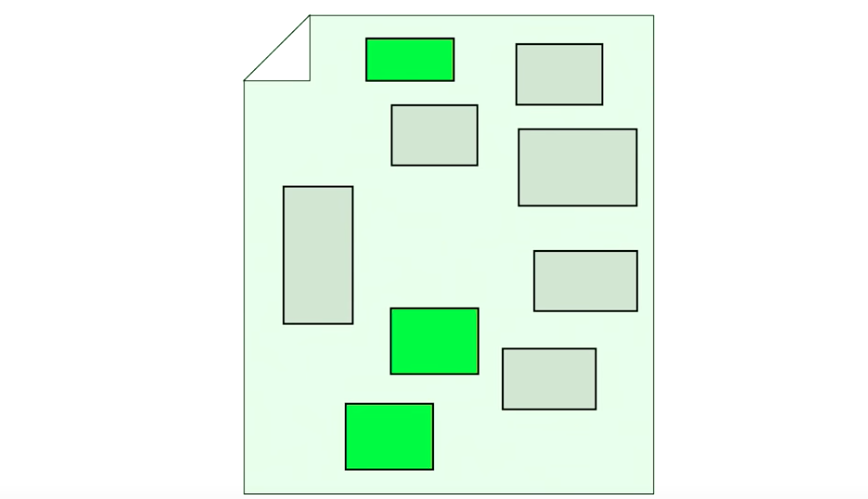
重构过后,你加了一个 message bus,来串联不同组件之间的通信。
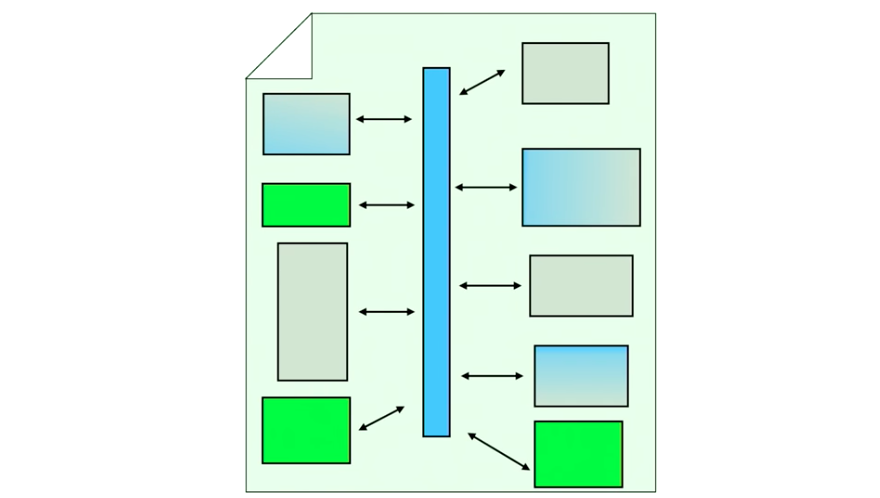
构建函数式编程世界的蓝图
面向对象编程语言到处是下面这种的定义和限制:
During the type erasure process, the Java compiler erases all type parameters and replaces each with its first bound if the type parameter is bounded, or Objectif the type parameter is unbounded.
Protected methods: a protected method is similar to a private method, with the addition that it can be called with, or without, an explicit receiver, but that receiver is alwaysself(it’s defining class)or an object that inherits fromself(ex: is_a?(self)).
A friend function of a class is defined outside that class’ scope but it has the right to access all private and protected members of the class. Even though the prototypes for friend functions appear in the class definition, friends are not member functions.
其种类繁多,你仔细想过没有,这是不是让问题本身过于复杂了?我们需要记住这么多限制吗?也许我们需要换一种方式、重构一下? 那就让我们开始吧!
还是从一张白纸开始:

把要保留的编程概念加进来:
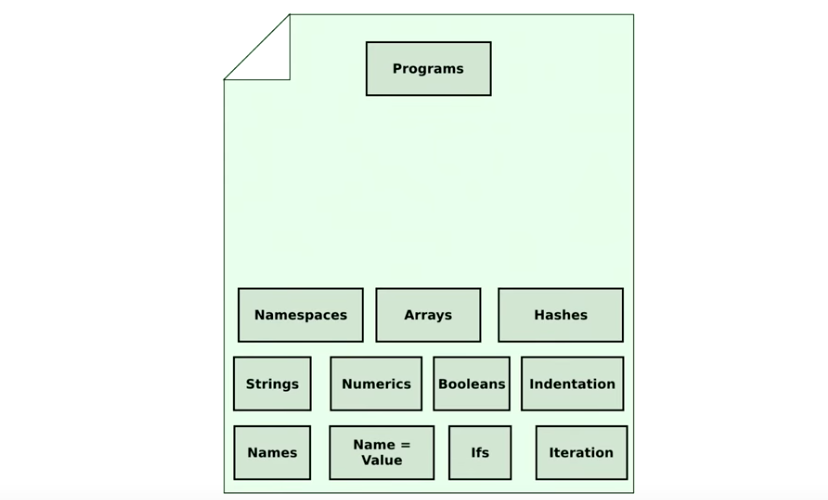
该如何把底层的编程语言基础,和顶层的程序组织起来呢?让我慢慢来看。
第一把武器:纯函数
也许数学家们能够帮我们的忙。数学和计算机科学在一个方面很像:抽象,试图从最基本的元素开始,抽象出上层概念。数学家写了一本叫《Principia Mathematica》的书,从非常非常简单的公理开始,推导出了整个数学大厦,光是证明 1 + 1 = 2 就花了 300 多页。。。
那么我们能从数学家那里借来什么概念呢?没错,函数!
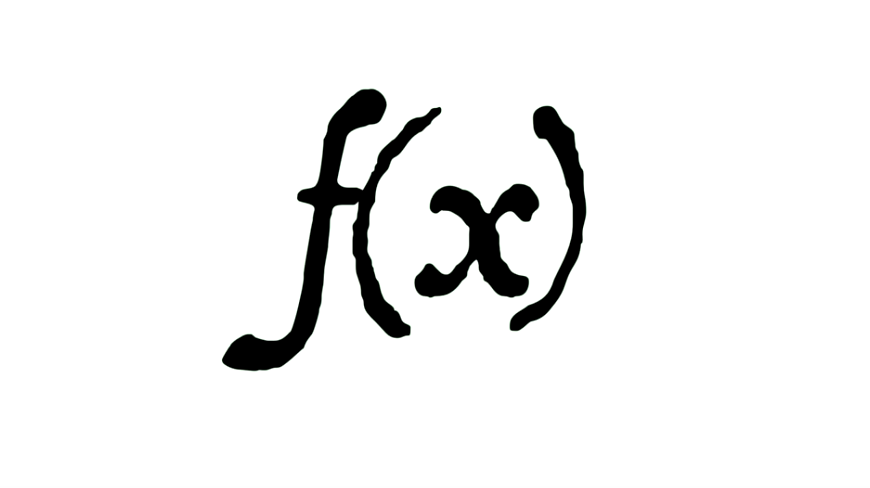
数学意义上的函数和我们程序中的函数不一样,函数就是一个集合到另一个集合的映射:给我一个输入,我还你一个输出,不会对外界做任何操作。而且更重要的是,对于任何特定的输入,我还给你的输出一定是一样的。
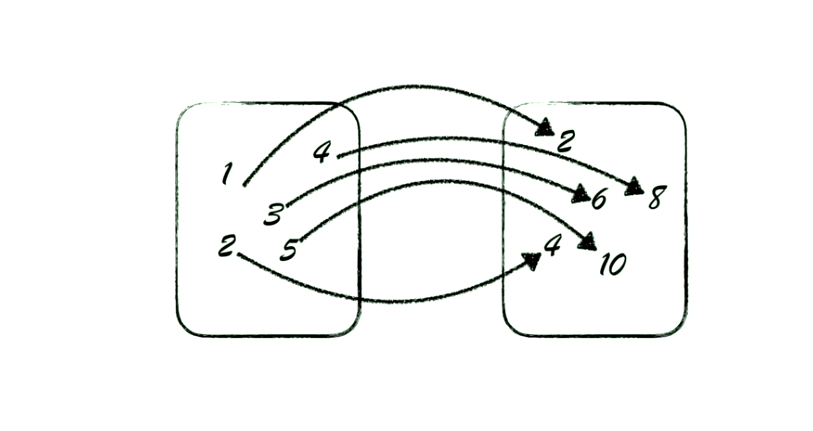
而编程语言中函数的概念不太一样,编程语言中的函数可以删除文件、插入数据库,而这些属于副作用。而且,编程语言的函数给定一个输入,输出结果可能会不一样,比如输出依赖于当前时间的情况。
如果我们想借鉴数学中的函数这个概念,就需要给编程语言中的函数强加一些特定的规则,让他表现得和数学函数一样。(我们把满足这种条件的函数叫做纯函数。)这些规则很简单:
- 一样的输入,产生一样的输出。
- 没有副作用。
我们这样做,并不是上层设计,经过严格的证明,认定纯函数一定能让我们的代码更简单,这只是一种期望。 就像面向对象一样,我们抽象出现实世界一一对应的类和对象,这并没有严格的证明可以保证这样做就是对的,只是我们期望这样做可以。
我们需要问两个问题:
- 纯函数有什么优势?
- 如果纯函数有优势,如何在语言层面确保纯函数能够实现?
When asked, “What are the advantages of writing in a language without side effects?,” Simon Peyton Jones, co-creator of Haskell, replied, “You only have to reason about values and not about state. If you give a function the same input, it’ll give you the same output, every time. This has implications for reasoning, for compiling, for parallelism.” — From the book, Masterminds of Programming[4]
如前面所说,纯函数核心在于对于特定输入,永远有一样的输出,且没有副作用。有了纯函数,你就只需要考虑 values 了,不用管 state了(相信你也听说或经历过共享变量带来的痛苦)。 这使得函数式编程具备以下几个优势:
纯函数更容易 reason about
纯函数不会说谎,你能从函数定义得到几乎所有信息。 纯函数更容易组合
这和 unix 的 pipeline 很像。
val x = doThis(a).thenThis(b)
.andThenThis(c)
.doThisToo(d)
.andFinallyThis(e)
纯函数更容易测试、debug
显而易见,纯函数只依赖于输入,不需要考虑其他复杂的状态。
纯函数更容易并行化
“If there is no data dependency between two pure expressions, then their order can be reversed, or they can be performed in parallel and they cannot interfere with one another (in other terms, the evaluation of any pure expression is thread-safe).”
只要两个纯函数之间没有数据依赖,他们的执行顺序就可以任意替换,或者能安全地并发执行,换句话说, pure expression 是线程安全的。《七周七并发模型》一书中也将函数式编程当作一种重要的并发模型,甚至这可能就是未来的趋势,因为这种方式最简单,你完全不用考虑锁的问题。 想要了解纯函数更多的优势,推荐看这篇文章:The Benefits of Pure Functions | alvinalexander.com
我们回答完了第一个问题,知道了纯函数是有优势的,现在我们的蓝图上添加了第一把武器:纯函数。
第二把武器:持久性数据结构(Persistent Data Structure)
接下来回答另一个问题:如何在语言层面确保纯函数能够实现?
我们都知道,一般的数据结构是可变的,比如一个数组,没有任何限制阻止你修改其中的某个元素:
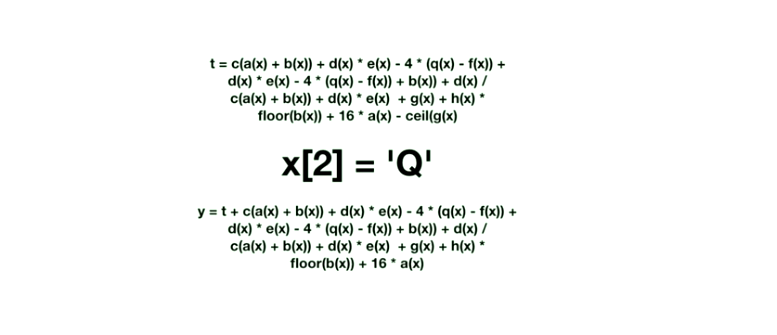
但是这样一来,就违背了我们前面说的规则:不会产生副作用。
有一个解决方案:让所有的数据结构都不可变。一旦你创建了这个列表,你不能修改它;一旦你创建了这个 hashmap,你不能修改它。当然,函数肯定是需要对输入做一系列操作(计算)的,否则这个函数有何意义。只不过操作的方式不一样: 比如有一个 array :x = ["a","b","c"],在一个纯函数内要执行 x[1] = "Q",这会先将 x 复制一份,把复制品的第二个元素修改为 "Q",原来的 x 没有变化。(copy on modification)
现在我们不用担心调用的函数会在我们不注意的情况下修改传入的值了,不过这会带来性能问题,因为拷贝太多了!所幸有人很聪明,想出了Persistent Data Structure,使得拷贝的次数尽可能达到最低。 比如,一个数组,在底层可能是一个树形结构。
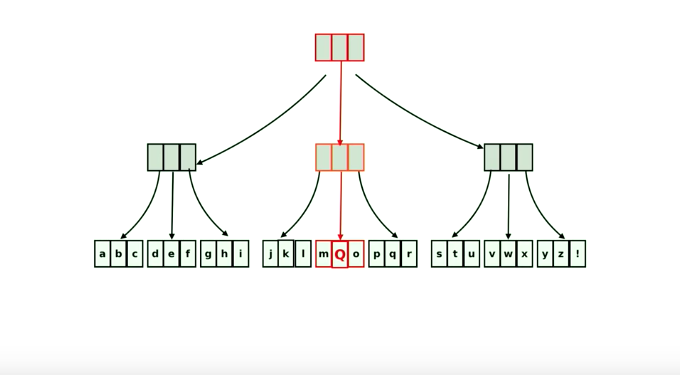
要修改的时候,只会修改树的其中一部分,其他部分是和原来的元素共用的。Persistent Data Structure 的原理这里就不细讲了,有兴趣的可以自行了解。
到目前为止,我们得到了第二把武器:Persistent Data Structure.
第三把武器:连接外部世界的桥梁
然后再来仔细想想什么是 side effect。修改文件、插入数据库、调用外部服务,这些对于我们程序员来说属于 side effects。但是对于用户来说,这就是他们所期望完成的操作!一个报表应用的使用者只关心数据库里面的数据、生成的报表,他们才不关心代码,也不懂什么函数式编程。如果一个应用完全没有“副作用”,那这个应用也就没有存在的意义。
Side effects are what we paid to do !
所以我们需要在“函数式编程理想世界” 和 “充满 side effects 的复杂多变的现实世界”之间架起一座桥梁。
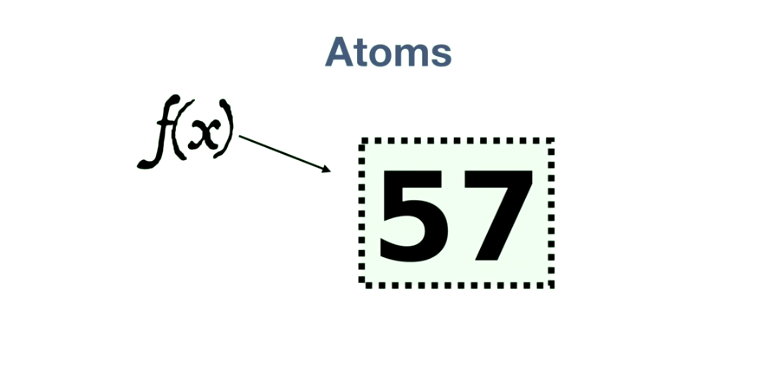
其中一个现实世界的的问题:如何实现可变状态?比如一个网站的访问次数计数器,这就是一个可变状态。可是在纯粹的函数式编程世界里,数据都是不可变的,Clojure的解决方案,是 Atoms。可以把 Atoms 看作是包含可变状态的容器。
修改一个 Atoms 的方式是:丢给它一个函数,atoms 接收到这个函数,把 atoms 当前的 value 传递给函数,函数根据这个 value 计算产生新的 value,返回给 atoms,atoms再将此 value 作为新的 value 保存下来。
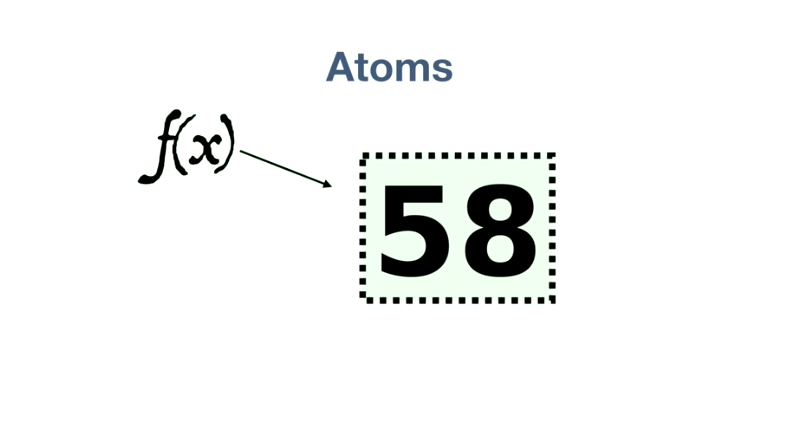
Atoms 的强大之处还体现在,当有两个函数同时到达时:
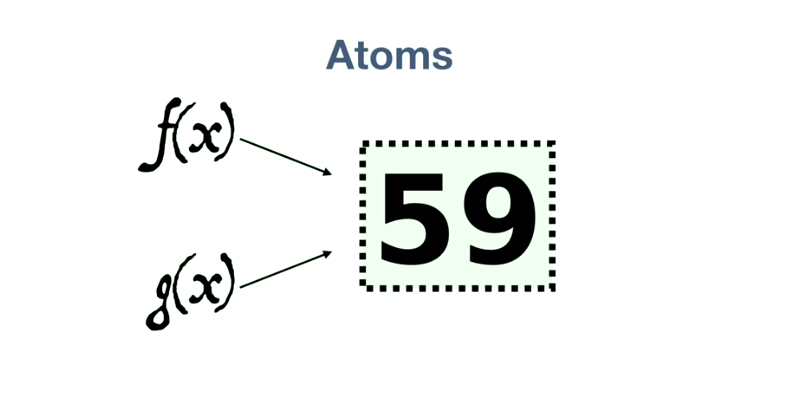
fx 和 gx 两个函数(假设都是加一函数)同时传递到 atoms 面前,他们看到的值都是 59,经过计算,两个函数产生的结果都是60。但是,总是会有一个函数(比如说是 fx )先把 59 更新为 60。另一个函数(gx)再次把值更新为 60 的时候,atoms 就会检测到底层的数据已经发生了变化,然后让 gx 再执行一次!
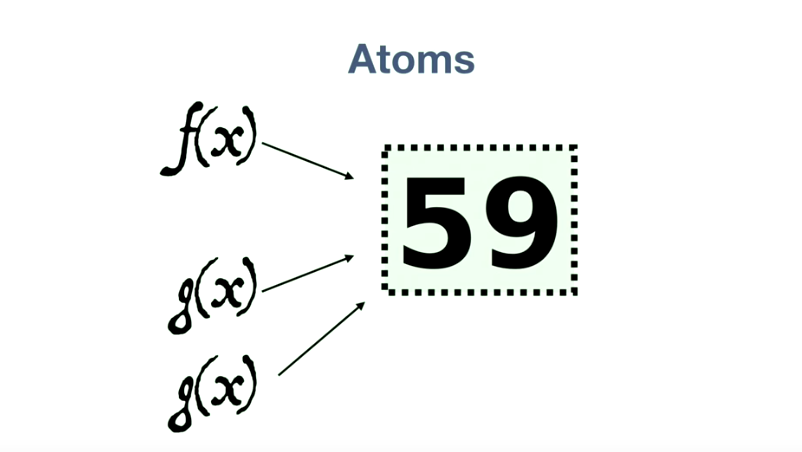
由于没有 side effects,所以重试是没有任何问题的。这属于 atoms 的冲突检测机制。 可变状态的问题解决了,那么更新数据库、操作文件这些操作该怎么办呢?Clojure 有 Agents。
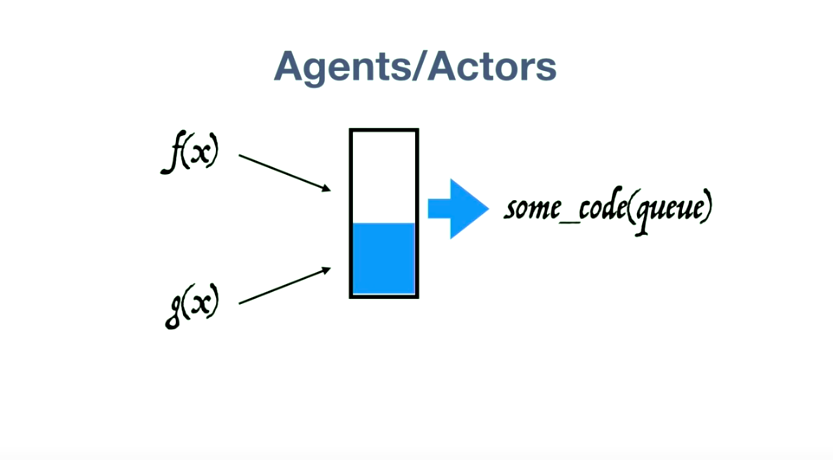
简单来说,Agents的作用是接受带有 side effects(比如进行数据库操作)的函数,加入到一个队列里面,依次执行。 现在我们有了第三把武器:连接外界的桥梁。
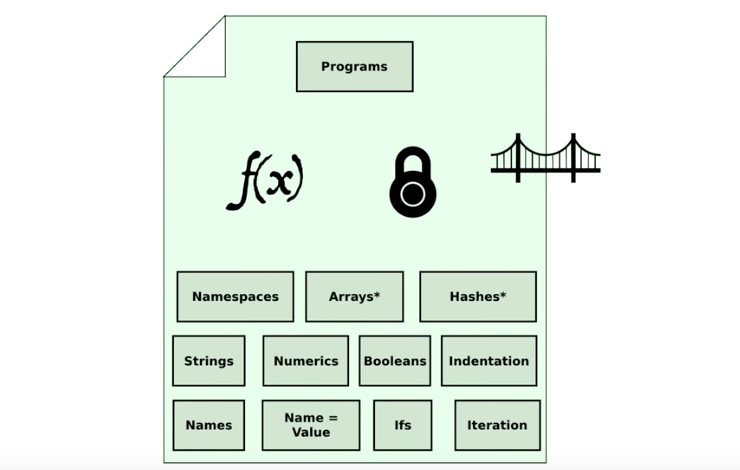
而这,也就是我们设计的函数式编程的最终蓝图了。是不是很简单,并没有想象的那么复杂。
总结
函数式编程并非万能解药,它不能完全消除重复代码,也不能阻止你写出垃圾代码。
函数式编程通过引入纯函数,具备了面向对象编程所没有的优势,能让代码更简单,更容易理解。而持久性数据结构使得纯函数变得可能。未来是一个多核时代,函数式编程语言天生线程安全(因为没有可变数据结构,一个线程不可能修改另一个线程的数据),非常适合在多核环境运行。
函数式编程编写的函数没有副作用,但是应用的使命本身就是副作用,要连接 “理想的函数式编程世界” 和 “复杂的充满副作用的现实世界”,可以用 atoms 或者 agents 这类桥梁。
面向对象依旧是当前应用最广泛的编程思想,也构建了无数大型项目,而函数式编程相比更为简单,未来前景肯定会越来越好。
参考资料
[1] Russ Olsen: russolsen.com/
[2] GOTO 2018 • Functional Programming in 40 Minutes • Russ Olsen: www.youtube.com/watch?v=0if…
[3] Lambda calculus: en.wikipedia.org/wiki/Lambda…
[4] Masterminds of Programming: amzn.to/2bedXb4
[5] The Benefits of Pure Functions | alvinalexander.com: alvinalexander.com/scala/fp-bo…
欢迎关注个人微信公众号:面向墙外编程。带你获得更多高质量的墙外编程资源。

