

关系型数据库
1. 数据库架构

2. 索引
2.1 为什么要使用索引
加快查询速度,避免全表扫描
2.2 什么样的数据能使用索引
主键、唯一键和普通键
2.3 索引的数据结构
- 二叉查找树
- B-Tree
- B+-Tree
- Hash 结构
2.4 密集索引和稀疏索引的区别
- 密集索引文件中的每个搜索码都对应一个索引值
- 稀疏索引文件只为索引码的某些值建立索引项
3. 锁
3.1 InnoDB 与 MyISAM 在锁方面的区别
- MyISAM 只支持表级锁,不支持行级锁
- InnoDB 默认使用行级锁,也支持表级锁
3.2 MyISAM 适用于:
- 频繁查询 count
- 查询多,增删改少
- 不用事务
3.3 InnoDB 适用于:
- 增删改查都多的情况
-
- 可靠性要求高
3.4 数据库锁的分类
- 按锁的粒度划分:表级锁、行级锁和页级锁
- 按锁级别划分:共享锁和排它锁
- 按加锁方式划分:隐式锁和显示锁
- 按操作划分:DML 锁和 DDL 锁
- 按使用方式划分:乐观锁和悲观锁
3.5 数据库事务的四大特性:ACID
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
ps: 数据库的终极目标就是使数据库从一个一致的状态转换到另一个一致的状态,这就是ACID中的一致性,而原子性、隔离性、持久性是为了实现这个目标的手段。
3.6 事务隔离级别以及各级别下的并发访问的问题
- 更新丢失:MySQL 所有事务隔离级别在数据库层面上均可避免
- 脏读:READ-COMMIT 事务隔离级别以上可避免
- 不可重复读:REPEATABLE-READ
- 幻读:SERIALIZABLE
查看 MySQL8.x 事务隔离级别
show variables like 'transaction_isolation'
临时设置当前 Session 的事务隔离
set session transaction isolation level read uncommitted;
3.7 InnoDB 可重复读隔离级别下如何避免幻读
- 表象:快照读(非阻塞读)—— 伪 MVCC
- 内在:next-key 锁(行锁 + gap锁)
3.7.1 RC 级别下的 InnoDB 的非阻塞读如何实现
-
数据行里的 DB_TRX_ID、DB_ROLL_PTR 和 DB_ROW_ID
- DB_TRX_ID:最后一次对该行数据插入或删除的事务 ID
- DB_ROLL_PTR:回滚指针
- DB_ROW_ID:如果表中不存主键 或者 唯一索引,那么数据库 就会采用DB_ROW_ID生成聚簇索引。否则DB_ROW_ID不会出现在索引中。
-
undo 日志
- insert undo log:插入时的 log,在 commit 之后被丢弃
- update undo log:修改和删除时的 log,在快照读时会使用
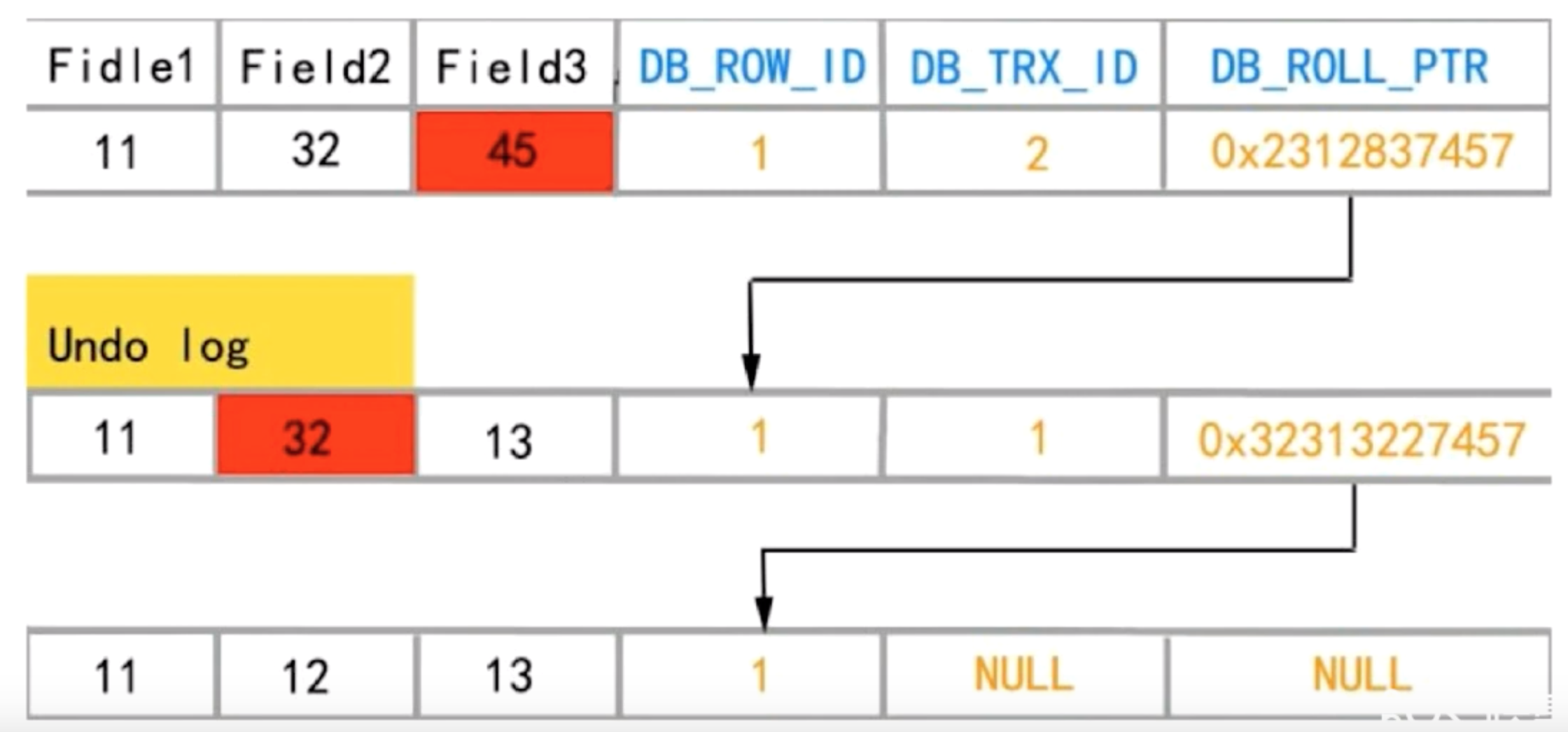
-
read view
3.7.2 RR 级别下的 InnoDB 的非阻塞读如何实现
- 行锁
- Gap 锁:where 条件全部命中,不会使用 Gap 锁,部分与全不命中就会加
