

接着上篇学习的内容,今天我们主要来学习如下内容:
(10)单选按钮(Radio)操作
通过elenium.is_selected()来判断单选按钮是否被选择。
案例:单选按钮(Radio)操作。
对于下面的HTML。
<h4>单选:性别</h4>
<form>
<label value="radio">男</label>
<input name="sex" value="male" id="boy" type="radio"><br>
<label value="radio1">女</label>
<input name="sex" value="female" id="girl" type="radio">
</form>
如下Selenium测试代码。
def test_CheckRadio (self):
sexRadio = self.driver.find_element_by_xpath("//input[@value='male']")
sexRadio.click()# 点击选择“男”选项
self.assertTrue(sexRadio.is_selected(),"男单选框未被选中!")# 断言“男”单选框选中。
(11)复选框(CheckBox) 操作
仍旧通过elenium.is_selected()来判断复选按钮是否被选择。
案例:选择复选框中的一个选项。
对于下面的HTML。
<h4>选择课程</h4>
<form>
<input id="c1" type="checkbox">selenium<br>
<input id="c2" type="checkbox">python<br>
<input id="c3" type="checkbox">appium<br>
如下Selenium测试代码。
def test_CheckChecxBoxByOne(self):
element = self.driver.find_element_by_id("c1")#定位第一个选项
if not element.is_selected():#由于多选框,如果是选择状态,点击变为未选择状态。反之,如果是未选择状态,点击变为选择状态,所有这里用if语句进行判断
element.click()#如果复选框未选,则点击它
self.assertTrue(element.is_selected(),"复选框未被选中!")# 断言“selenium”复选框被选中
案例4-65:选择复选框中的所有选项。
对于案例同一个的HTML,有如下Selenium测试代码。
def test_CheckChecxBoxByAll(self):
checkbox= self.driver.find_elements_by_xpath("//input[@type='checkbox']")#这里用find_elements…
for i in checkbox:#遍历所有复选框
if not i.is_selected():#如果这项没有被选择
i.click()#点击它
self.assertTrue(i.is_selected(),"selenium未被选中!")# 断言最后一项是否被选择
(12)警告框、弹出个确认框、弹出个输入框(Alert、Confirm、Prompt) 操作
这三个元素共有以下五个操作语法。
driver.switchTo().alert()#获取alert
alert.accept()#点确定
alert.dismiss()#点取消
alert.text()#获取alert的内容
alert.send_key(keysToSend) #向Prompt发送文字
案例:警告框操作
def test_CheckAlert(self):
alertInformation="这是一个alert弹框"
self.driver.execute_script("alert('"+alertInformation+"')")
time.sleep(2)
#self.driver.switch_to_alert().accept() #相当于点击"确定"
#self.driver.switch_to_alert().dismiss() #相当于点击"取消"
text=self.driver.switch_to_alert().text #获取弹窗框里面的文字
self.assertEqual(text,alertInformation)
(13)Cookie操作
Cookie共有以下五个操作语法。
get_cookies()#获得所有cookie
get_cookie(name)#返回字典key为name的cookie
add_cookie(cookie_dict)#添加cookie,cookie_dict为字典信息
delete_cookie(name,optionsString)#根据key为name删除cookies,optionsString支持路径、域
delete_all_cookies()#删除所有cookies
案例:对csrftoken的操作。
附录A登录模块HTML代码如下。
<form class="form-signin" method="post" action="/login_action/" enctype="multipart/form-data">
<input type="hidden" name="csrfmiddlewaretoken" value="gNSK53BZIlPXK1wkRh6ZPeMIsCJOqTUtklfNsqxqnSEKrMoBUYoT2SWuo2Z4ouo3">
<h2 class="form-signin-heading">电子商务系统-登录</h2>
<p><label for="id_username">用户名:</label> <input type="text" name="username" maxlength="100" required id="id_username"></p>
<p><label for="id_password">密码 :</label> <input type="password" name="password" required id="id_password"></p>
<button class="btn btn-lg btn-primary btn-block" type="submit">登录</button><br>
<a href="\register\">注册</a>
</form>
为了破解csrftoken,需要获取name="csrfmiddlewaretoken" 隐藏文本框的内容,将其放入一个名为csrftoken的Cookies中。其Selenium测试代码如下。
def test_CheckLogin(self):
username='cindy'#定义用户名
password='123456'#定义密码
self.driver.find_element_by_id("id_username").clear()#清空并写入用户名
self.driver.find_element_by_id("id_username").send_keys(username)
self.driver.find_element_by_id("id_password").clear()#清空并写入密码
self.driver.find_element_by_id("id_password").send_keys(password)
csrftoken = self.driver.find_element_by_name("csrfmiddlewaretoken").get_attribute("value")#获取name="csrfmiddlewaretoken" 隐藏文本框的内容
self.driver.add_cookie({"name":"csrftoken","value":csrftoken})#将其放入一个名为csrftoken的Cookies中
self.driver.find_element_by_class_name("form-signin").submit()#进行登录操作
self.assertEqual(self.driver.title,"电子商务系统",msg="标题不正确")#验证登录知否成功
(14)文件上传
这里仅对HTML为<input type="file">的文件介绍
案例:文件上传
def test_CheckUpload (self):
file ="c:\\python\\song.txt"#上传文件路径
self.driver.find_element_by_name("upfile").send_keys(file)
time.sleep(4)
self.driver.find_element_by_id("submit").click()#提交表单
time.sleep(4)
self.assertIsNotNone("文件成功上载",self.driver.page_source)
(15)文件下载
案例:文件下载。
def setUp(self):
f = open("info.txt", "r")
brower = f.readline()
f.close()
if brower.lower() == "firefox":
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.dir', 'c:\\')
profile.set_preference('browser.download.folderList', 2)
profile.set_preference('browser.download.manager.showWhenStarting', False)
profile.set_preference('browser.helperApps.neverAsk.saveToDisk', 'application/rar’)
elif brower.lower() == "chrome":
options = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory': 'c:\\'}
options.add_experimental_option('prefs', prefs)
else:
print("该浏览器不支持下载")
self.assertEqual(1,2)
d = drivers()
self.driver=d.driver
self.driver.implicitly_wait(5)
self.driver.get("http://127.0.0.1:8080/sec/37/index.html")
def test_Download(self):
self.driver.find_element_by_link_text('下载').click()
time.sleep(3)
这里Chrome与Firefox支持方式是不一样的,另外IE Selenium Webdriver是不支持下载的。
对于Chrome
Ø browser.download.dir:指定下载路径。
Ø browser.download.folderList:设置成 2 表示使用自定义下载路径;设置成 0 表示下载到桌面;#设置成 1 表下载到默认路径。
Ø browser.download.manager.showWhenStarting:在开始下载时是否显示下载管理器(没作用)。
Ø browser.helperApps.neverAsk.saveToDisk:对所给出文件类型不再弹出框进行询问。
对于Firefox
Ø download.default_directory:设置下载路径。
Ø profile.default_content_settings.popups:设置为 0 禁止弹出窗口。
(16)对HTML5 Vedio的操作
对HTML5 Vedio的操作共有以下四个操作语法。
url = driver.execute_script("return argument[0].currentSrc",video) #获取视频的路径
driver.execute_script("return argument[0].load() ",video) #调用视频
driver.execute_script("return argument[0].play() ",video) #播放视频
driver.execute_script("return argument[0].pause() ",video) #暂停视频
案例:HTML5 Vedio的操作。
以下测试程序将调用一段视频播放3秒钟后暂停5秒钟,然后继续播放。
class CheckVideo(unittest.TestCase):
def setUp(self):
d = drivers()
self.driver=d.driver
self.driver.implicitly_wait(5)
self.driver.get("http://127.0.0.1:8080/sec/16/index.htm")
def test_CheckVideo(self):
video= self.driver.find_element_by_id("video")#获取视频元素
print("start")
self.driver.execute_script("return arguments[0].play()",video)#播放视频
time.sleep(3)
print("pause")
self.driver.execute_script("return arguments[0].pause()",video)#暂停视频
time.sleep(5)
print("restart")
self.driver.execute_script("return arguments[0].play()",video)#继续播放视频
(17)执行Javascript代码&对HTML5 canvas的操作
Selenium可以用过execute_script(Java_Script)方法执行Javascript代码,语句则为参数Java_Script。canvas也是HTML5的一个亮点,Selenium对canvas操作其实就是执行一段javascript语句。
案例:HTML5 canvas的操作。
简单起见,在这里使用w3school的画布进行操作,代码如下。
def test_CheckCanvas (self):
self.driver.execute_script("var c=document.getElementById('myCanvas');"
"var cxt=c.getContext('2d');"
"cxt.fillStyle='#FF0000';"
"cxt.fillRect(0,0,150,50);")
time.sleep(3)
self.driver.save_screenshot("./HTMLCanvas.png")
运行这段代码产生的截图如图所示。

(18)Selenium Grid
如果测试用例非常多的时候,往往在一台机器上运行会消耗很多时间,Selenium提供的Grid技术,如图所示。
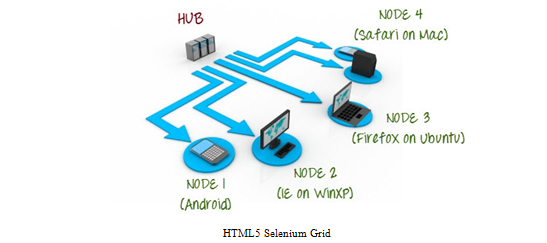
Selenium Grid是一个HUB-NODE接口,需要测试的代码都在HUB节点上,通过HUB的管理,所有Selenium测试程序被随机分配到Node节点上进行运行。
为了能够运行Selenium Grid,需要作如下的配置。
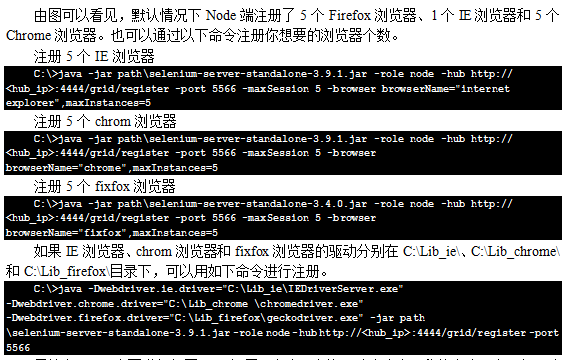
l hub端与node端都能下载selenium-server-standalone-3.9.1.jar放在本地目录中,比如C:\Lib\下。
>下载selenium-3.X driver。
>在hub端启动hub节点(注意hub的4444端口必须是空闲的)。
C:\>java -jar path\selenium-server-standalone-3.9.1.jar -role hub
其中path为存放selenium-server-standalone-3.9.1.jar的目录,下同。
> 在node端向hub端进行注册(注意node的5566端口是空闲的,否则重新在命令中分配)。
C:\>java -jar path\selenium-server-standalone-3.9.1.jar -role node -port 5566 -hub http://:4444/grid/register
其中是Hub端的IP地址。
> 在Hub端打开浏览器,地址栏中输入:http://localhost:4444/grid/console,出现如图界面。
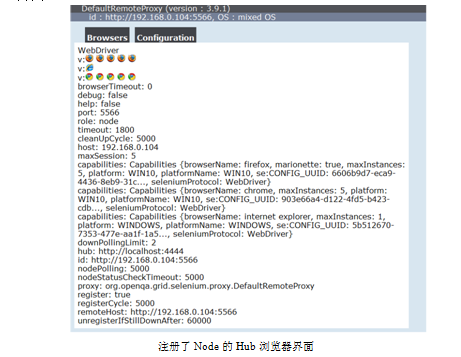
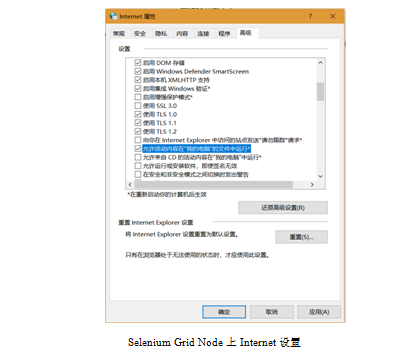
另外在Node上要进行如图设置,点亮“允许活动内容在‘我的电脑’上运行”选项。
案例:Selenium Grid。
import time
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import unittest,time
class grid(unittest.TestCase):
def setUp(self):
#CHROME浏览器
capabilities = DesiredCapabilities.CHROME
#微软浏览器
#capabilities = DesiredCapabilities.INTERNETEXPLORER
#FIREFOX浏览器
#capabilities = DesiredCapabilities.FIREFOX
self.driver = webdriver.Remote(command_executor="http://10.10.7.238:4444/wd/hub",desired_capabilities=capabilities)# 10.10.7.238为本地Hub端的IP地址
"""
如果grid的hub可以接收到消息,但是测试不成功,则可以使用本地方法来调试。
如driver = webdriver.Ie()来进行本地测试,"""
#self.driver = webdriver.Ie()
self.driver.implicitly_wait(3)
self.driver.get("https://www.baidu.com")
def test_grid(self):
self.driver.find_element_by_id("kw").send_keys("大数据")
self.driver.find_element_by_id("su").click()
time.sleep(5)
self.assertEqual(self.driver.title,"大数据_百度搜索",msg="Title is not right")
def tearDown(self):
self.driver.quit()
其中:
>capabilities = DesiredCapabilities.CHROME:表示在CHROME浏览器中运行。
>capabilities = DesiredCapabilities.INTERNETEXPLORER:表示在微软浏览器中运行。
> capabilities = DesiredCapabilities.FIREFOX:表示在FIREFOX浏览器中运行。
Selenium Grid测试程序在Hub端启动,将会被随机平均分配到各个Node端运行。
(18)数据化驱动
通过Python读取xml、excel文件、数据库可以对Selenium进行数据驱动操作。
案例:XML文件的数据驱动。
定义以下config.xml文件,文件中定义了所用浏览器类型,一组定义了百度查询关键字数据。
chrome
软件测试
大数据
软件工程
云计算
其测试代码如下。
from selenium import webdriver
import unittest,time
from xml.dom import minidom
from util import drivers,findby
class checkbaidu(unittest.TestCase):
def setUp(self):
d = drivers()
self.driver=d.driver
self.driver.implicitly_wait(5)
def test_CheckBaidu(self):
dom = minidom.parse('config.xml')
root = dom.documentElement
words = root.getElementsByTagName('words')
i=0
for word in words:
self.driver.get("https://www.baidu.com")
inputstring=words[i].firstChild.data
self.driver.clear(self.driver.find_element_by_id("kw"))
self.driver.send_keys(self.fd.find_element_by_id("kw"),inputstring)
self.driver.click(self.driver.find_element_by_id("su"))
time.sleep(3)
self.assertEqual(self.driver.title,inputstring+"_百度搜索",msg="标题错误")
i=i+1
def tearDown(self):
self.fd.quit(self.driver)
if __name__=="__main__":
unittest.main()
案例:Excel文件的数据驱动。
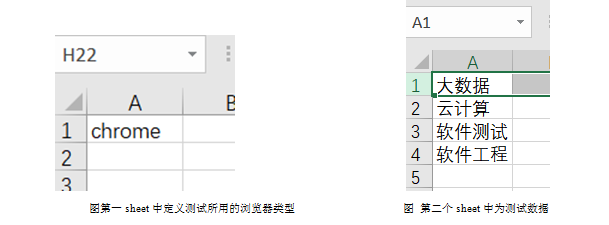
建立Excel文件:config.xlsx。在这个文件中第一个sheet中书写测试所用的浏览器类型(为方便起见,从第一行第一列开始书写),如图所示。第二个sheet中为测试数据,定义了百度查询关键字数据,如图所示。
测试代码如下
#coding=utf8
# 导入xlrd模块
import xlrd
from xlutils.copy import copy
import unittest
from selenium import webdriver
import unittest,time
from xml.dom import minidom
from util import drivers,findby
class checkbug2report(unittest.TestCase):
def setUp(self):
#设置文件名和路径
fname = 'config.xlsx'
# 打开文件
filename = xlrd.open_workbook(fname)
#获取当前文档的表(得到的是sheet的个数,一个整数)
self.sheets=filename.nsheets
self.sheet1 = filename.sheets()[0]#获得sheet1
self.sheet2 = filename.sheets()[1]#获得sheet2
# print sheet
self.nrows1 = self.sheet1.nrows#获得sheet1的行数
self.nrows2 = self.sheet2.nrows#获得sheet2的行数
d = drivers()
self.driver=d.driver
self.driver.implicitly_wait(5)
def test_baidu(self):
for i in range(0,self.nrows1):#读取sheet1中的数据
row_datas = self.sheet1.row_values(i)
browser = row_datas[0]
for i in range(0,self.nrows2): #循环读取sheet2中的数据
row_datas = self.sheet2.row_values(i)
inputstring = row_datas[0]
self.driver.get("https://www.baidu.com")
self.driver.clear(self.driver.find_element_by_id("kw"))
self.driver.send_keys(self.driver.find_element_by_id("kw"),inputstring)
self.driver.click(self.driver.find_element_by_id("su"))
time.sleep(3)
self.assertEqual(title,inputstring+"_百度搜索",msg="标题错误")
def tearDown(self):
self.driver.quit()
if __name__=="__main__":
unittest.main()
3.断言API
由于这里采用的是unittest,所以直接使用unittest的断言函数。读者可以考虑如何采用Pytest框架来实现。
