

仓库地址
起源
突然想看小欢喜,但是腾讯的视频广告太多了,所以就想去电影天堂下载,但是电影天堂的链接复制太麻烦了,而且如果我是想全部复制的,也没有,想起以前用puppeteer写过一个爬虫,刚好拿来改下
使用方案
1.安装
npm instal dytt -g
2.使用
dytt url1 url2 ...
3.查看生成的text,复制到迅雷一键下载
url 是具体的详情页,例如:www.dytt8.net/html/tv/hyt…
又来源码解读??
bin/dytt.js ,处理参数,asserUrl判断是否电影天堂链接,crawl爬数据
#!/usr/bin/env node
const crawl = require('../crawl')
const urls = process.argv.slice(2)
if (!urls.length) throw('请输入电影天堂的链接')
const asserUrl = (url) => {
if (!url || typeof url !== 'string') return false
if (/^https?:\/\/www\.dytt8\.net(\/\w+?)+\.html?$/.test(url)) return true
return false
}
const start = async() => {
for (let url of urls) {
if (!asserUrl(url)) continue
await crawl(url)
}
process.exit(0)
}
start()
crawl.js 使用puppeteer.launch启动浏览器,browser.newPage打开新页面,toGoPage.evaluate分析页面,其中evaluate无法使用外部参数,只有传进去,evaluate里面的值可以return出来给外界使用,evaluate里面是dom环境
const puppeteer = require('puppeteer')
const fs = require('fs')
const path = require('path')
let crawl = async (browser, url, format = false) => {
if (typeof browser === 'string') {
url = browser
browser = await puppeteer.launch()
}
if (!url) return
const toGoPage = await browser.newPage()
try {
await toGoPage.goto(url ,{
timeout: 60000
})
} catch (error) {
await browser.close()
console.log(url+'失败')
}
const result = await toGoPage.evaluate((format) => {
const fallbackLink = (node) => {
// 检查是否满足ftp或者thunder
// 否则从html里面获取
// 去掉开头和末尾的空格
const link = (node.innerText || '').replace(/^\s*|\s*$/g, '')
// 支持 ftp thunder http(s) 这三种主要协议的下载链接
if(/^(ftp|thunder|https?):\/\//.test(link)) return link
const html = node.outerHTML || ''
const match = html.match(/((ftp|thunder|https?):\/\/[^"]+)/)
if(match) {
return match[1]
} else {
return ''
}
}
name = document.querySelector('#header > div > div.bd2 > div.bd3 > div.bd3r > div.co_area2 > div.title_all > h1 > font').innerHTML || Date.now()
const links = document.querySelectorAll('#Zoom > span table tr>td a')
let resLinks = format ? [] : ''
links.forEach((item, index)=> {
if (format) {
resLinks.push({
// TODO 修复集数问题,因为有些不是从第一集开始的
index: index +1,
link: fallbackLink(item)
})
} else {
resLinks+= '\n'+ fallbackLink(item)
}
})
return {
link: resLinks,
name: name
}
}, format)
fs.writeFileSync(path.join(process.cwd(),`${result.name}.text`), format ? JSON.stringify(result.link, null, 2) : result.link)
await browser.close()
}
module.exports = crawl
遇到的坑
1.由于把源设置为淘宝源了,导致npm login总是失败,后面才发现需要
npm login --registry http://registry.npmjs.org
npm publish --registry http://registry.npmjs.org
- 由于迅雷支持一键下载全部需要每个链接单独一行,所以把每个链接前加'\n'
效果图
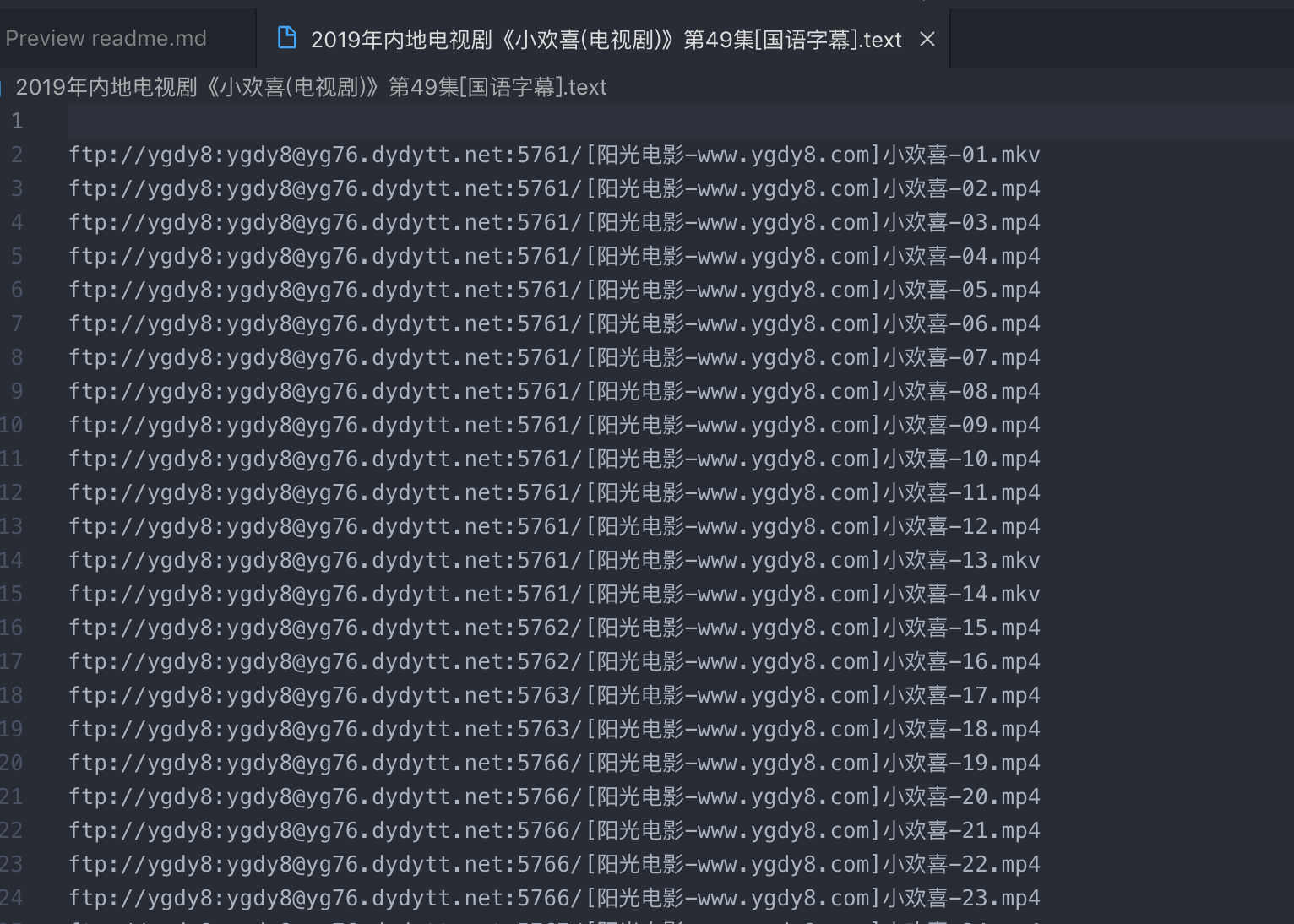
- 下载回来的资源列表
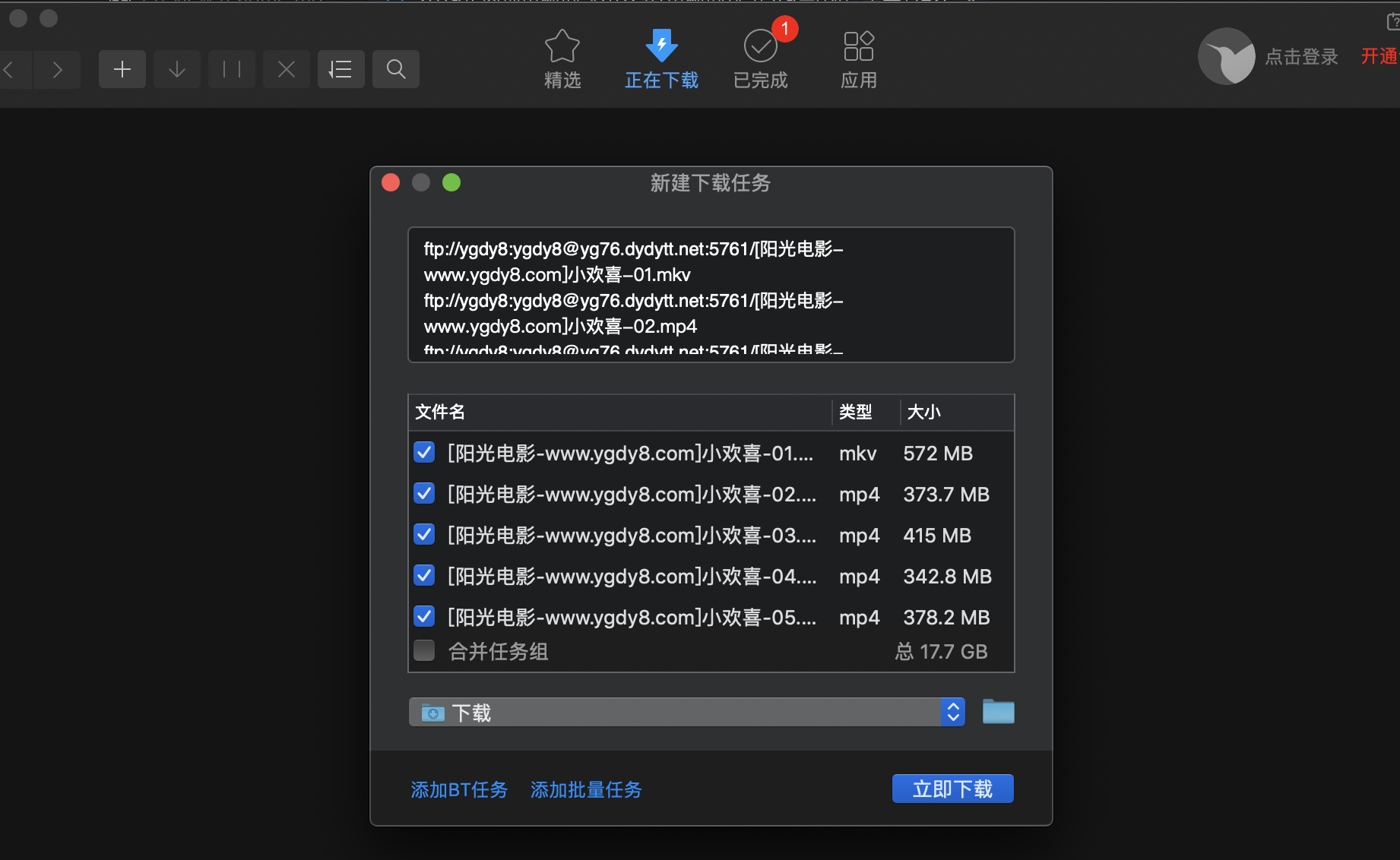
- 复制全部链接后,迅雷的效果
结语
这个小项目里面还有很多优化的空间,看有没有时间吧,逃:)
