

自然语言处理,是人工智能的一个分支,简单来说就是用计算机来处理、理解以及运用人类语言,属于“认知智能”的范畴。从NLP被提出至今,就一直被人们赋予了这样的期待——善解人意。
这个的“人意”具体是指什么呢,这就不得不提到语言的三个层面:语法、语义和语用。
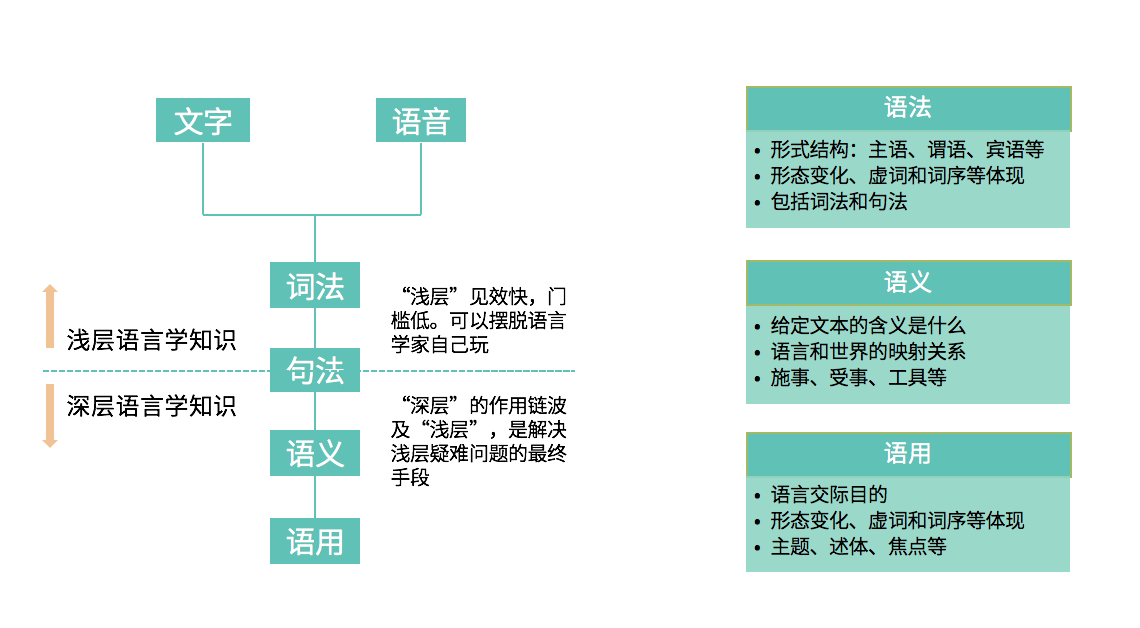
01语法
语法貌似抽象,但我们大多数人在中学时都已接触过。小学语文课上学过的主谓宾、定状补,或是在英语课上接触过的形态变化、虚词、词序的体现,都属于语言的语法层面。我们的语言,从词语到句子的构成,都是遵从这些语法规则。NLP技术的发展,也是从突破这些问题开始的。
02语义
简单来讲就是判断一段给定文本的含义是什么。当看到“小明欺负了小强,所以我批评了他。”这句话时,为什么人类会自然而然地确定“他”指代“小明”;当我们看到一个完全符合语法规则的句子“没有颜色的蓝色在愤怒地睡觉”时,为什么会马上感到这句话完全不符合语义逻辑?在语义层面,我们更多关注的是语义成分,施受关系、动词类别及支配关系等等,即语言和我们所理解的世界的映射关系是什么样子的。目前来看,NLP厂商的很多竞争基本上也是在这个层面展开的。
03语用
这个层面回归到的语言的根本目的:交际。一段文本传递了什么信息,它的主题是什么,焦点在哪里。在对话中,应该如何合理地考虑情境、上下文、甚至是肢体语言等种种因素对语义作出判断。一个人笑意盈盈地说出“你很讨厌”,跟一个人咬牙切齿地说出“你很讨厌”所传递的信息必定是不同的。这个层面目前鲜有厂商涉猎,而竹间已经在电话外呼、多模态情感计算等业务场景中做出过尝试,成果突出,受到客户极大认可。 做NLP,只有解决了这三个平面的问题,才能真正达到人们所期待的“善解人意”。
在解决语言在三个平面上的问题时,面临一些挑战:
01输入的不规范性
这种不规范性表现在错别字、口语化输入、或者语法错误等多个方面。错别字,包括将“芈月传”误输为“半月传”,“生生不息”误输为“升升不息”等等。这类问题业内的做法是通过训练纠错模型来自动纠错,我们的纠错模型也经过了长虹、华夏等等多个项目的验证,目前已经是标准产品的一部分。 至于口语化的输入,多见于外呼转文本处理的过程中,其特点是冗长且夹杂了很多无用信息。将这种类型的问题修剪、理顺并提取关键信息是解题思路。竹间已在外呼服务中成功帮助多家企业解决了电视报装、问卷回访、保险身份核实等几十个场景,对于长难句的处理已经申请了专利。
02语言普遍存在的不确定性造成的歧义问题
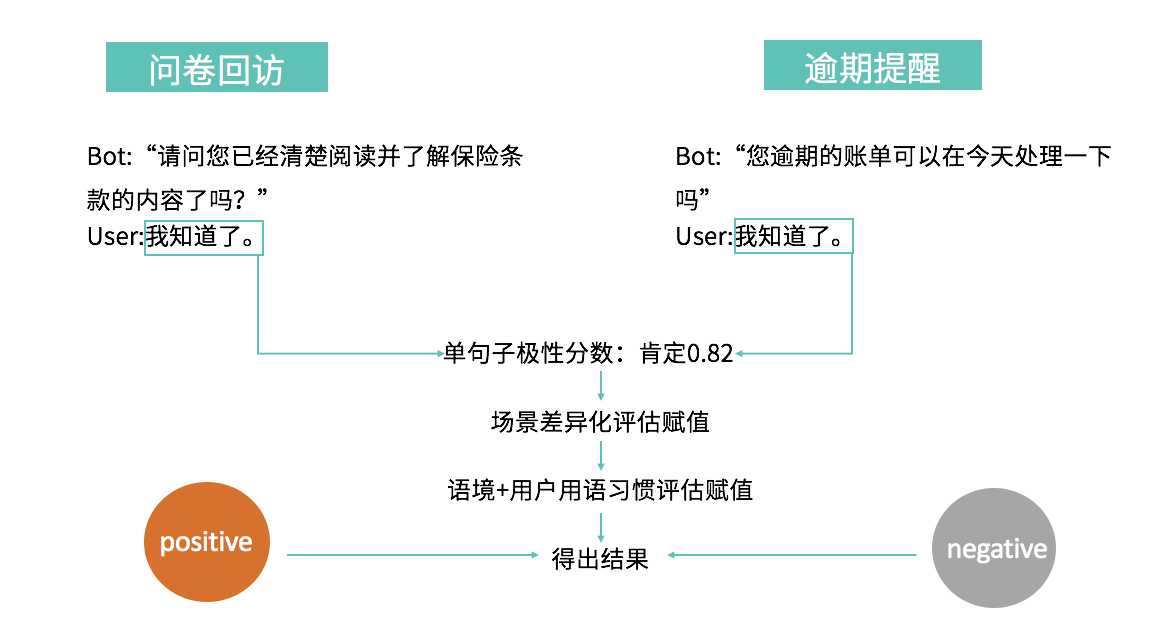
在分词中我们会遇到这样的情况: e.g. 网球拍卖完了 网球/拍卖/完/了 or 网球拍/卖完/了 两种切分方式都对,那究竟应该按照哪个结果输出呢?我们的答案是:按照上下文输出正确的那个。如果没有上下文呢?输出两个,由下游模块根据需要灵活使用。 很多时候,同一句话根据所处的业务场景、语境、语气不同,语用也不同。 “我知道了”在问卷回访和逾期提醒这两个场景中,分别可以代表“好的,我知道了”和“别说了,我知道了”这两种意思。在实际的业务处理中,除了考虑这句话在语法和语义层面上的结果,我们也从语用层面出发,将场景差异化、语境、和用户习惯等特称纳入赋值范围,实现了同一句话的灵活解析:
03语言知识获取的复杂性
回到我们在之前谈到的那个问题:
e.g. 小明欺负了小强,因此我批评了他
小明欺负了小强,因此我安慰了他
人类因为知道“欺负”“批评”和“安慰”的含义,才能得出第一个“他”指的是“小明”,第二个“他”指的是小强 。对于计算机来说,需要建立动词支配关系图谱,建立语义图谱(semantic graph),并同已有的NLP模块一起协作,才能赶上人脑一瞬间的判断,真正达到认知的智能。
