

查询性能低下最基本的原因是访问的数据太多。某些查询可能不可避免的需要筛选大量数据。但这并不常见。大部分性能低下的查询都可以通过减少访问数据量的方式进行优化。对于低效的查询,有两个方式:
- 确认应用程序是否在检索大量超过需要的数据,这表示访问了较多的行或者较多的列
- 确认mysql服务器是否在分析大量超过需要的数据行
请求不需要的数据
- 查询不需要的记录
mysql会返回全部的结果集再进行计算。开发者一般会这样做: 先使用select语句查询大量的结果,然后取前面的n行后关闭结果集,例如分页。
-
多表关联时返回所有列
-
总是取出全部列
除此之外
*号的开销比取出全字段的开销要大 -
重复查询相同的数据
扫描额外的记录 最简单衡量查询开销的三个质保如下:
- 响应时间
- 扫描的行数
- 返回的行数
一般mysql使用如下三种方式应用where条件来筛选存储引擎返回的记录 从好到坏依次为:
- 在索引中使用where条件来过滤不匹配的记录,这是在存储引擎层完成
- 使用索引覆盖扫描(在extra列中出现了USing index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果,这是在mysql服务器完成的
- 从数据表中返回数据,然后过滤不满足条件的记录(extra列中出现using where)这是在mysql服务器层完成的。mysql需要读出记录然后再过滤
重构查询的方式
-
一个复杂查询 vs 多个简单查询
mysql内部每秒能够扫描内存中上百万行数据,而相应数据给客户端就很慢。在其他条件都相同的时候,使用尽可能少的查询当然是更好的。
-
切分查询 删除旧的数据就是一个好的例子,定期的清除大量数据时,如果一个大的语句一次性完成的话,则可能需要一次锁住很多数据,占满整个事务日志 例如,需要每个月运行依次下面的查询
mysql>delete from message where create time <DATE(NOW().INTERTVAL 3 MONTH)
那么可以改成这样
rows_affected = 0
do{
rows_affected = do_query(
"delete from message where create time <DATE(NOW().INTERTVAL 3 MONTH)
Limit 10000"
)while row_affected > 0
}
因为我们在没有开启mysql事务的情况下,Innodb引擎默认事务是可重复读,也就是一条sql自动提交。这样分散成多次执行,就不会因为事务提交时间过长而耗费mysql服务器性能
- 分解关联查询
mysql> select * from tag JOIN tag_post ON tag_post.tag_id= tag_id
-> JOIN post ON tag_post.post_id=post_id
-> where tag.tag='mysql'
分解为
mysql>select * from tag where tag='mysql'
mysql>select * from tag_post where tag_id=1234;
mysql>select * from post where post.id in (123,456,567,9098,8904)
分解查询的优势 -让缓存效率更高 应用程序可以方便的缓存单表查询对应的结果对象 -将查询分解后,执行单个查询可以减少锁的竞争 -在应用层做关联,可以更容易对数据库进行拆分 让mysql是按照id顺序查询,而因为mysql存储引擎上一张已经讲到是用b-tree进行数据存储,所以对于存储数据的叶子结点而言,id是随机关联的,可以让查询效率更高
- 减少冗余记录的查询 也就是说某条记录只需要查询一次,而在数据库中做关联,则可能需要重复访问一部分的数据,可以减少网络和内存的消耗
- 相当于在应用中实现了hash关联,用关键值去定位具体的记录
查询执行的基础
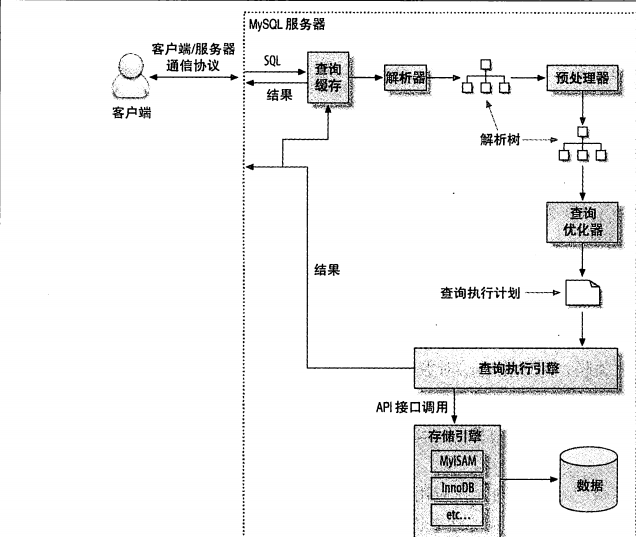
- 客户端发送一条查询给服务器
- 服务端检查查询缓存,如果命中缓存,则立即返回存储在缓存结果中进入下一阶段
- 服务端进行sql解析、预处理,再由优化器生成对应的执行计划
- mysql根据优化器生成的执行计划,调用存储引擎的api来进行查询
- 将结果返回给客户端
mysql客户端/服务端通信协议
首先要明确的是Mysql客户端和服务器的通信协议是半双工的。也就是说没办法进行流量控制。一旦开始端到端的数据传输,客户端要用一个单独的数据包将查询传给服务器,即参数max_allow_packet,用来保证客户端发送查询很长的语句,能够及时等待结果。
一般服务器响应给用户的数据很多,由多个数据包组成。当服务器开始响应客户端请求,客户端需要完整的接受整个返回结果。这种情况下,客户端若接受完整的结果,或者接收几条就断开连接是不合适的。在必要的时候应该在查询中加上limit限制
查询状态
对于一个Mysql连接,或者说一个线程。任何时刻状态表示mysql当前在做什么。比如show processlist(该命令返回结果中Command列就表示当前的状态)。重要的状态如下
sleep线程正在等待客户端发送新的请求query线程正在执行查询或者正在将结果发送给客户端locked在mysql服务器层,线程正在等待表锁。在存储引擎级别实现的锁,例如Innodb的行锁,并不会体现在线程状态中。analyzing and statistics线程正在收集存储引擎的统计信息,并生成查询的执行计划copying to tmp table线程正在执行查询,并且将结果集都复制到同一个临时表中,这种状态一般要么是做group by/file sort/union操作。如果这个状态后面还有on disk标记,就表示mysql正将一个内存临时表放到磁盘上sending data这表示多种情况,线程可能在多个状态中传送数据,或者生成结果集,或者向客户端返回数据
查询优化处理
- 语法解析器和预处理 mysql通过关键字将sql语句进行解析,并生成一颗于语法解析树。mysql解析器将使用mysql语法规则验证和解析查询。将验证是否是错误的关键字,或者顺序是否正确,再或者它还会验证引号是否能前后正确匹配
预处理器则根据一些mysql规则进一步检查语法解析树是否合法,比如检查数据表和列,字段以及别名是否有歧义
查询优化器(mysql重点)
现在语法树认为合法,并且由优化器将其转化成执行计划。一条查询有多种执行方式,最后返回相同的结果。优化器的作用找到其中最好的执行计划。
mysql使用基于成本的优化器,他将尝试预测一个查询使用某种执行计划时的成本,并且选择成本最小的一个。
如当执行一次where条件比较的成本,可以通过当前会话的last_query_cost值来得知mysql计算的当前查询的成本
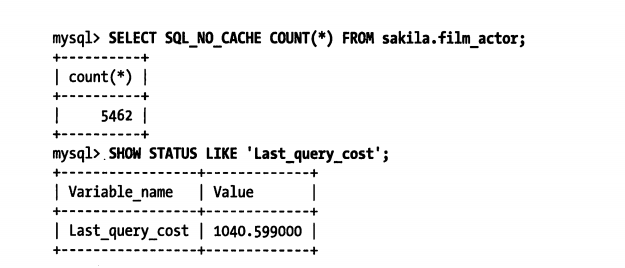
这个结果表示mysql优化器认为大概需要做1040个数据页的随机查找才能完成上面的查询。这是根据统计信息算出来的。统计信息包括:
- 每个表或者索引的页面个数
- 索引的基数
- 索引和数据行的长度
- 索引分布情况
优化器在评估的时候不考虑任何层面的缓存,他假设读取任何数据都需要一次磁盘I/O
有很多原因会导致mysql优化器选择错误的执行计划
-
统计信息不准确 Innodb因为其MVCC()的架构,不能维护一个数据表行数的精确统计信息
-
执行计划中的成本估算不等同于实际执行的成本 例如有时候某个执行计划虽然需要读取更多的页面,但他的成本更小。因为如果这些页面都是顺序读或者这些页面都已经在内存中的话,那么它的访问成本将很小,mysql层面并不知道那些页面在内存中,哪些在磁盘上,实际查询中到底需要多少次物理I/O是不知道的
-
mysql的最优是指根据其成本模型选择最优的执行计划
-
mysql从不考虑其他并发执行的查询,因为会影响到当前查询的速度·1
-
mysql也并不是任何时候都是基于成本的优化 如果存在全文搜索的match()子句,则在存在全文索引的时候就使用全文索引,例如,如果存在全文搜索的
match()子句,则在存在全文索引的时候就使用全文索引。即使有时候使用别的索引和where条件,mysql也会使用对应的全文索引
mysql优化策略分为两种 静态优化和动态优化
-
静态优化 可以直接对解析树进行分析,并完成优化。例如,优化器可以通过一些简单的代数变换可以直接对解析树进行分析,并完成优化。 例如
select id from student where sex = 1 and sex = 3可以优化为select id from student where sex between 1 and 3 if sex!=2 -
动态优化 动态优化和查询的上下文有关,也可能和很多其他因素有关,例如where条件中的取值,索引中条目对应的数据行数等,这需要在每次查询的时候重新评估,为运行时优化。
mysql能优化处理的类型
-
重新定义关联表的顺序 比如关联表的顺序,决定关联顺序是大表是否驱动小表的一点
-
将外连接转化为内连接 并不是所有的outer join都必须以外连接的方式执行。 例如where条件,库表结构都可能让一个外连接等价于一个内连接
-
等价变换规则 例如
(5=5 and a>5)将被改写为a>5,类似的,如果有(a<b and b=c) and a=5则会改写为b>5 and b=c and a=5 -
优化count(),min(),max()
索引和列是否为空通常可以帮助mysql优化这类表达式,例如要找到某一列最小值,只需要查询b-tree索引对应最左端的记录,mysql可以直接获取索引的第一行记录。在b-tree索引中,优化器生成查询计划的时候就可以利用这一点,在b-tree中,优化器会将这个表达式作为一个常数对待. 如果mysql使用了这种类型的优化,那么在explain中可以看到select tables optimized away
- 预估并转化为常数表达式 当mysql检测到一个表达式可以转化为常数的时候,就会一直把该表达式作为常数进行优化处理。如果在索引上执行min()函数,甚至唯一主键查找语句也可以转换为常数表达式。如果where子句中使用了该索引的常数条件,mysql可以在查询开始阶段就先找到这些值,这样优化器就能够知道并转换为常数表达式
Continue..QwQ
