

flume 1.6 日志采集。
flume 挂了怎么办?新版本有配置可以实现了,如果公司是老版本呢?
搭建
- 解压
rm -rf docs删除文档 - 配置环境变量
FLUME_HOME mv flume-env.sh.template flume-env.sh修改一下里面的JAVA_HOME
example
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
# 缓冲区
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
# 一个事务(一次)发送100个event
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# telnet localhost 44444 发送消息测试。
bin/flume-ng agent --conf conf --conf-file example.conf --name a1(对应配置文件中的名字) -Dflume.root.logger=INFO,console 启动。
- flume能通过环境变量找到hdfs、hbase、hive
- 不建议使用java代码连flume
多个flume

- 两个flume用avro连接。即第一个的sink是avro第二个的source是avro。
- 引出 工作中的场景
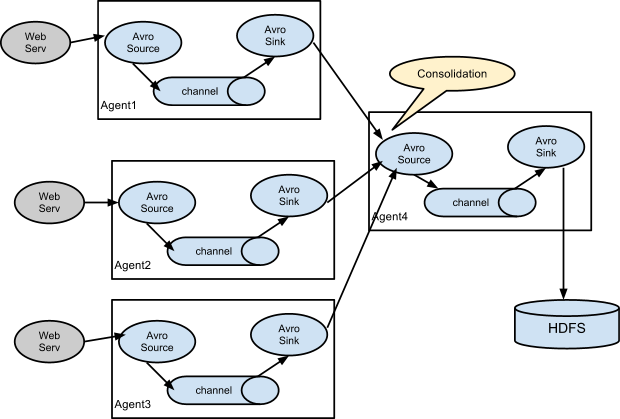
flume HA
flume source
# tailf 读文件。 详细配置见官网
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
a1.sources.r1.channels = c1
- kafka 是重点结合对象。
flume channel
memory
一般都用内存 但是有断电风险
jdbc
效率太低了
kafka
也可以用。
flume sink
hdfs
# Describe the sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
# hdfs 中的目录
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
