

日志分析平台(练手项目)
练习hdfs mr hive hbase
- 各种公司都需要,例如电商、旅游(携程)、保险种种。
- 数据收集-数据清洗-数据分析-数据可视化。
- 数据:用户的行为日志,不是系统产生的日志。
数据量
如何谈数据量
- 站长工具:PV(页面访问量) UV(日均IP访问)
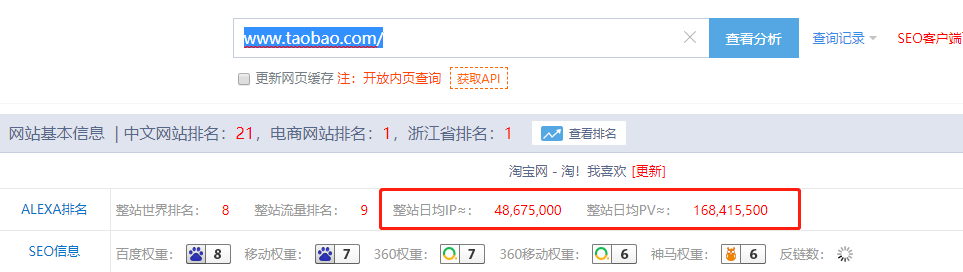
- 说条数。
- 大小慎重说不要瞎说。
技术选型
- 存储引擎:hbase/hdfs
- 分析引擎(计算):mr/hive 为了练手用MR
- 可视化:不做。
模块
用户基本信息分析模块
- 分析新增用户,活跃用户,总用户,新增会员,活跃会员,会话分析等。
- 公司开始的钱都花在推广上。
- 所有指标值都是离线跑批处理。而且没必要做实时,每天早上来看指标就好了。
浏览器来源分析
时间和浏览器两个维度
地域分析模块
调整仓库,根据IP定位
用户访问深度分析模块
某一个会话、某个用户访问的页面个数。业务强相关。
外链数据分析模块
广告投放。拼多多砍一刀
数据源
使用nginx的log module
nginx
upstream 中 下划线 坑?!
log module
- 内嵌变量
- $remote_host 远程IP地址
- $request_uri 完整的原始请求行(带参数)
- log module
- $mesc 产生时间。单位有意思。
location
location文档 location有精准匹配>正则匹配>前缀匹配
js发送日志
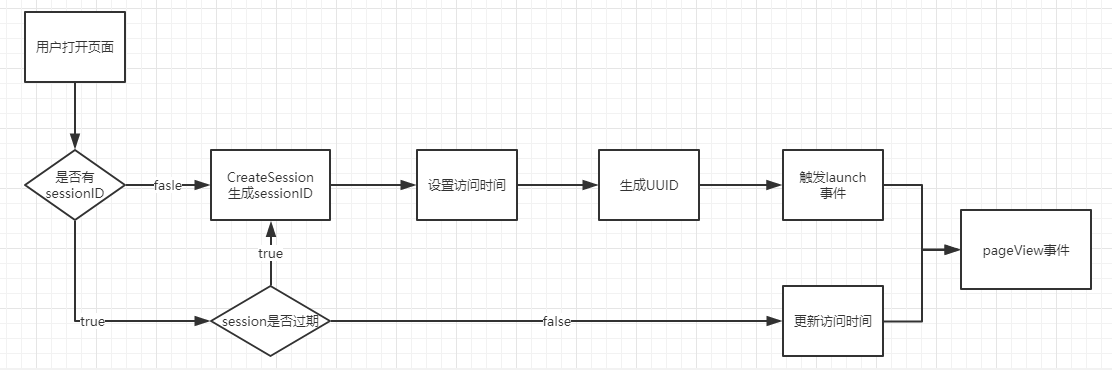
- 用图片发数据。请求一个图片资源,里面有参数给nginx抓到。
sendDataToServer : function(data) {
alert(data);
// 发送数据data到服务器,其中data是一个字符串
var that = this;
var i2 = new Image(1, 1);// <img src="url"></img>
i2.onerror = function() {
// 这里可以进行重试操作
};
i2.src = this.clientConfig.serverUrl + "?" + data;
},
java代码发送(订单的成功或失败)
发送日志到nginx,如果出现网络延迟等问题,不能让后面的业务受到影响
- 开启一个阻塞队列,开一个线程从里面一直取然后发送。
// 只负责扔到队列中。
public static void addSendUrl(String url) throws InterruptedException {
getSendDataMonitor().queue.put(url);
}
// 第一次发送 开启一个线程 监听队列。
public static SendDataMonitor getSendDataMonitor() {
if (monitor == null) {
synchronized (SendDataMonitor.class) {
if (monitor == null) {
monitor = new SendDataMonitor();
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// 线程中调用具体的处理方法
SendDataMonitor.monitor.run();
}
});
// 测试的时候,不设置为守护模式
// thread.setDaemon(true);
thread.start();
}
}
}
return monitor;
}
数据采集
将nginx的日志通过flumesink到hdfs
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/data/access.log
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
# hdfs 中的目录
a1.sinks.k1.hdfs.path = /project/events/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 10k 滚动一个文件
a1.sinks.k1.hdfs.rollSize = 10240
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollCount = 0
# 默认是SequenceFile
a1.sinks.k1.hdfs.fileType = DataStream
数据清洗
上MR代码。将hdfs->hbase
- 具体需不需要
reducer是看需不需要。差别还是很大的。从map->reduce中间需要落一次盘。差别很大。
