

ConcurrentHashMap是线程安全的HashMap:JDK6 与 JDK7 中,ConcurrentHashMap 采用了分段锁机制。JDK8 中,摒弃了锁分段机制,改为利用 CAS 算法。
那么为什么要用CAS算法呢?当散列的个数大于64,且链表碰撞数大于8的时候,就会触发courrentHashMap的扩容机制,演变为红黑树。每当链表碰撞数小于8,就会退化为链表,移除红黑树,这个过程中,面向存放元素需要不断的重试存放元素,更新元素的值,所以需要用到CAS算法。
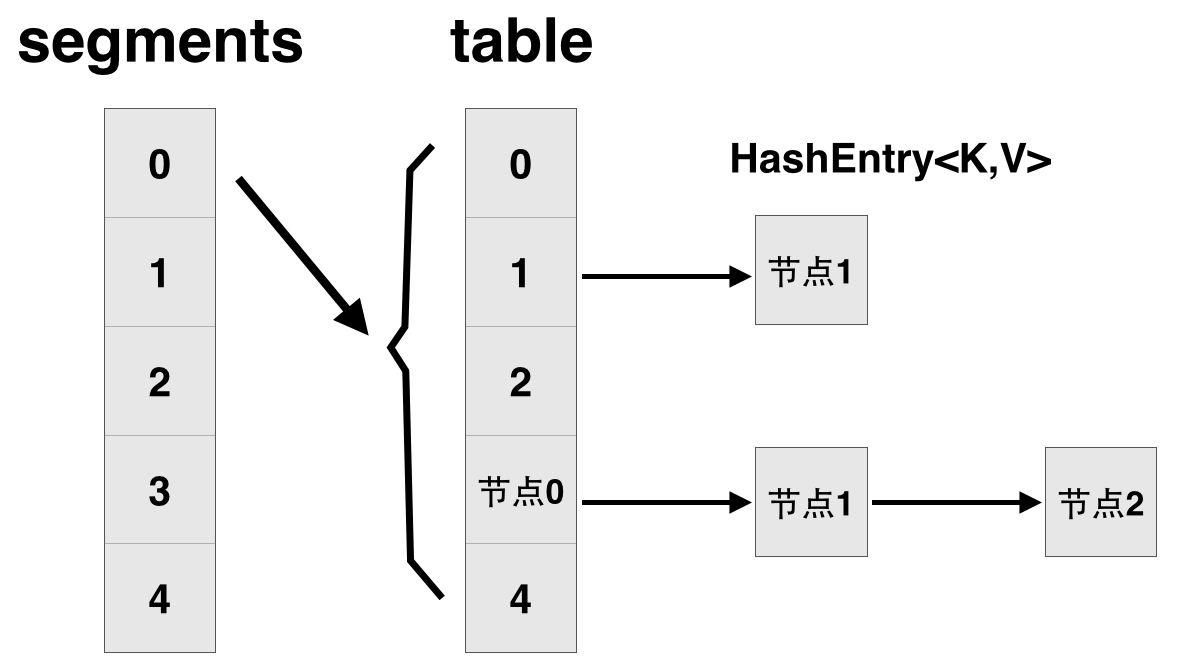
每一个segment都是一个 HashEntry<K,V>[] table, table 中的每一个元素本质上都是一个 HashEntry
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment<K,V>[] segments;
// 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本节点,存储Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
JDK8:
- 取消 segments 字段,直接采用 transient volatile HashEntry<K,V>[] table 保存数据,采用 table 数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
- 将原先 table 数组+单向链表的数据结构,变更为 table 数组+单向链表+红黑树的结构。对于 hash 表来说,最核心的能力在于将 key hash 之后能均匀的分布在数组中。如果 hash 之后散列的很均匀,那么 table 数组中的每个队列长度主要为 0 或者 1。但实际情况并非总是如此理想,虽然 ConcurrentHashMap 类默认的加载因子为 0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为 O(n);因此,对于个数超过 8(默认值)的列表,jdk1.8 中采用了红黑树的结构,那么查询的时间复杂度可以降低到 O(logN),可以改进性能。
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table为空,初始化;否则,根据hash值计算得到数组索引i,如果tab[i]为空,直接新建节点Node即可。注:tab[i]实质为链表或者红黑树的首节点。
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果tab[i]不为空并且hash值为MOVED,说明该链表正在进行transfer操作,返回扩容完成后的table。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在链表中找到值为key的节点e,直接设置e.val = value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果没有找到值为key的节点,直接新建Node并加入链表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果节点数>=8,那么转换链表结构为红黑树结构。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 计数增加1,有可能触发transfer操作(扩容)。
addCount(1L, binCount);
return null;
}
但是因为链表需要面向存放元素进行不断的重试,就算是之前碰撞了8次那也有极小的可能是因为不断插入相同hashCode的元素所导致的,所以需要将碰撞8次之后的链表的长度进行限制,看其是否满足小于64个元素的条件。
/* ---------------- Conversion from/to TreeBins -------------- */
/**
* Replaces all linked nodes in bin at given index unless table is
* too small, in which case resizes instead.
*/
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
将更新的红黑树节点暴露到unsafe定义的字节码方法,即在编译时期将红黑树的节点按照偏移量更新到Volatile类型的对象中
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
因为这里是用左移运算符对位置进行选定,相当于*2操作,那么操作后的最大值就是(64/2-1)==31,下方unsafe类就是以这种方式从根节点开始分配权重,依次遍历至子节点
// Unsafe mechanics
private static final sun.misc.Unsafe U;
private static final long SIZECTL;
private static final long TRANSFERINDEX;
private static final long BASECOUNT;
private static final long CELLSBUSY;
private static final long CELLVALUE;
private static final long ABASE;
private static final int ASHIFT;
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentHashMap.class;
SIZECTL = U.objectFieldOffset
(k.getDeclaredField("sizeCtl"));
TRANSFERINDEX = U.objectFieldOffset
(k.getDeclaredField("transferIndex"));
BASECOUNT = U.objectFieldOffset
(k.getDeclaredField("baseCount"));
CELLSBUSY = U.objectFieldOffset
(k.getDeclaredField("cellsBusy"));
Class<?> ck = CounterCell.class;
CELLVALUE = U.objectFieldOffset
(ck.getDeclaredField("value"));
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak);
int scale = U.arrayIndexScale(ak);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
下面简述一下红黑树的建树来源:
-
红黑树首先是一颗二叉查找树
-
一颗二叉查找树需要具备的特性有:
- 左子树上所有结点的值均小于或等于它的根结点的值。
- 右子树上所有结点的值均大于或等于它的根结点的值。
- 左右子树也分别是一颗二叉排序树 目的是利用二分查找的思想,查找最大次数等同于如何查找树的高度, 在插入节点的时候,通过一层层比较大小,选择新节点的插入位置。
但二叉查找树有一种不利的状态,如果本身的树结构是
8(left)- 9(root)-12(right)
接下来依次插入如下五个节点:7,6,5,4,3。就变成了
3-4-5-6-7-8(left)-9(root)-12(right),这就是不平衡的状态
红黑树除了保证平衡之外,还具备了一下特性
-
节点是红色或黑色。
-
根节点是黑色。
-
每个叶子节点都是黑色的空节点(NIL节点)。
-
每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
-
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
针对第4点,所以我们每次移动位置都要移动当前节点到当前根节点的之后两个位置,避免在遍历路径上存在两个连续的红色节点
