


作者:嵇智
Renderer
在所有 Parser 编译生成完 tokens 的时候,就传给 Renderer.render 方法了。我们来看下 Renderer 的定义。它位于 lib/renderer.js。
default_rules.code_inline = function (tokens, idx, options, env, slf) {
var token = tokens[idx];
return '<code' + slf.renderAttrs(token) + '>' +
escapeHtml(tokens[idx].content) +
'</code>';
};
default_rules.code_block = function (tokens, idx, options, env, slf) {
var token = tokens[idx];
return '<pre' + slf.renderAttrs(token) + '><code>' +
escapeHtml(tokens[idx].content) +
'</code></pre>\n';
};
default_rules.fence = function (tokens, idx, options, env, slf) {
var token = tokens[idx],
info = token.info ? unescapeAll(token.info).trim() : '',
langName = '',
highlighted, i, tmpAttrs, tmpToken;
if (info) {
langName = info.split(/\s+/g)[0];
}
if (options.highlight) {
highlighted = options.highlight(token.content, langName) || escapeHtml(token.content);
} else {
highlighted = escapeHtml(token.content);
}
if (highlighted.indexOf('<pre') === 0) {
return highlighted + '\n';
}
if (info) {
i = token.attrIndex('class');
tmpAttrs = token.attrs ? token.attrs.slice() : [];
if (i < 0) {
tmpAttrs.push([ 'class', options.langPrefix + langName ]);
} else {
tmpAttrs[i][1] += ' ' + options.langPrefix + langName;
}
tmpToken = {
attrs: tmpAttrs
};
return '<pre><code' + slf.renderAttrs(tmpToken) + '>'
+ highlighted
+ '</code></pre>\n';
}
return '<pre><code' + slf.renderAttrs(token) + '>'
+ highlighted
+ '</code></pre>\n';
};
default_rules.image = function (tokens, idx, options, env, slf) {
var token = tokens[idx];
token.attrs[token.attrIndex('alt')][1] =
slf.renderInlineAsText(token.children, options, env);
return slf.renderToken(tokens, idx, options);
};
default_rules.hardbreak = function (tokens, idx, options /*, env */) {
return options.xhtmlOut ? '<br />\n' : '<br>\n';
};
default_rules.softbreak = function (tokens, idx, options /*, env */) {
return options.breaks ? (options.xhtmlOut ? '<br />\n' : '<br>\n') : '\n';
};
default_rules.text = function (tokens, idx /*, options, env */) {
return escapeHtml(tokens[idx].content);
};
default_rules.html_block = function (tokens, idx /*, options, env */) {
return tokens[idx].content;
};
default_rules.html_inline = function (tokens, idx /*, options, env */) {
return tokens[idx].content;
};
function Renderer() {
this.rules = assign({}, default_rules);
}
default_rules 对象存在不同类型的 token 渲染函数。
1. `code_inline` 是渲染 `我是 code_inline ` 语法
2. `fence` 是渲染 ``` js ``` 语法
3. `html_block` 是渲染 HTMl 标签
再来细看 render 方法的逻辑,因为 内部使用到这些渲染函数。
Renderer.prototype.render = function (tokens, options, env) {
var i, len, type,
result = '',
rules = this.rules;
for (i = 0, len = tokens.length; i < len; i++) {
type = tokens[i].type;
if (type === 'inline') {
result += this.renderInline(tokens[i].children, options, env);
} else if (typeof rules[type] !== 'undefined') {
result += rules[tokens[i].type](tokens, i, options, env, this);
} else {
result += this.renderToken(tokens, i, options, env);
}
}
return result;
};
render 逻辑很简单,传入 tokens,options,env。遍历所有的 token,根据它的 type 采用不同的渲染 rule 函数。
-
type 是 inline
Renderer.prototype.renderInline = function (tokens, options, env) { var type, result = '', rules = this.rules; for (var i = 0, len = tokens.length; i < len; i++) { type = tokens[i].type; if (typeof rules[type] !== 'undefined') { result += rules[type](tokens, i, options, env, this); } else { result += this.renderToken(tokens, i, options); } } return result; };据我们之前分析的 ParserInline,它的作用是进一步解析
type为inline的 token,并且它的 children 属性上放了编译出来的 token。那么renderInline就是用到它的 children 上的 token。如果 renderer.rules存在对应类型的渲染 rule 函数,就会用这个渲染 rule 函数去处理对应 type 的 token,否则都走render.renderToken的逻辑。 -
typeof rules[type] !== 'undefined'
用不同渲染 rule 来处理对应 type 的 token。比如 type 为 fence 的就用 default_rule.fence 来渲染。每个 rule 都很简单,就不细谈。
-
renderToken
如果都不满足以上条件,就用
renderToken来渲染 token。Renderer.prototype.renderToken = function renderToken(tokens, idx, options) { var nextToken, result = '', needLf = false, token = tokens[idx]; // Tight list paragraphs if (token.hidden) { return ''; } if (token.block && token.nesting !== -1 && idx && tokens[idx - 1].hidden) { result += '\n'; } result += (token.nesting === -1 ? '</' : '<') + token.tag; result += this.renderAttrs(token); if (token.nesting === 0 && options.xhtmlOut) { result += ' /'; } if (token.block) { needLf = true; if (token.nesting === 1) { if (idx + 1 < tokens.length) { nextToken = tokens[idx + 1]; if (nextToken.type === 'inline' || nextToken.hidden) { needLf = false; } else if (nextToken.nesting === -1 && nextToken.tag === token.tag) { needLf = false; } } } } result += needLf ? '>\n' : '>'; return result; };renderToken的作用就是渲染开标签或者闭合标签,内部还会调用renderAttrs来生成attributes。
render 的最后,就是输出 HTML 字符串。
总结
至此,MarkdownIt 的全部流程已经分析完毕,在整个 parse 抑或是 tokenize、render 的过程中,都是不同的 rule 函数在各司其职,这也就赋予了 MarkdownIt 极大的灵活性和扩展性,你可以去替换 parse rule,也可以去替换 tokenize rule 或者 render rule。来张流程图大致感受一下:
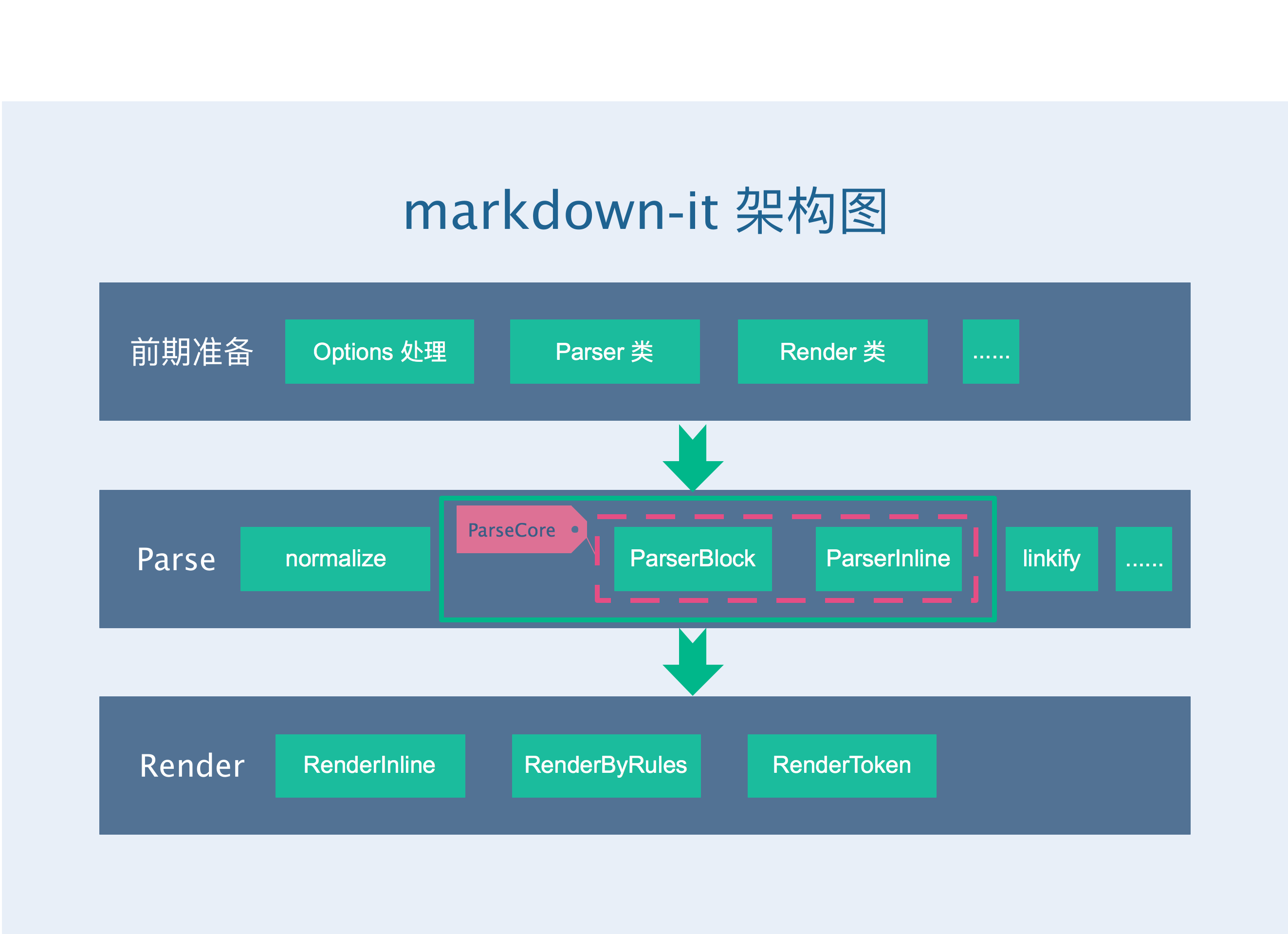
假如我们需要在 markdown 里面支持 emoji 语法呢,甚至还有更多定制化的需求呢?那我们就必须得写插件,你可能并不需要对某个 rule 的所有细节都知根知底,但是你必须对源码的整体流程是特别熟悉,我们将在插件篇讲解一些比较有趣的插件。
