

本文是Raft算法论文的学习笔记,Raft是一个用于管理多副本日志的共识算法。共识算法运行集群即使在少数节点崩溃的情况下,让集群中的节点一致工作。Raft算法有以下特性:
- 强领导:相对于其他一致算法,Raft使用强领导;
- 领导选举:Raft使用随机时间来选举领导;
- 成员变更:使用联合一致运行配置变更时存在重叠状态。
多副本状态机
共识算法涉及到了多副本状态机的概念,多副本状态机就是一组服务器做相同的状态副本,即使在一些服务器下线之后还是可以继续操作。多副本状态机通常使用多副本日志实现,而维护多副本日志就是共识算法的任务。
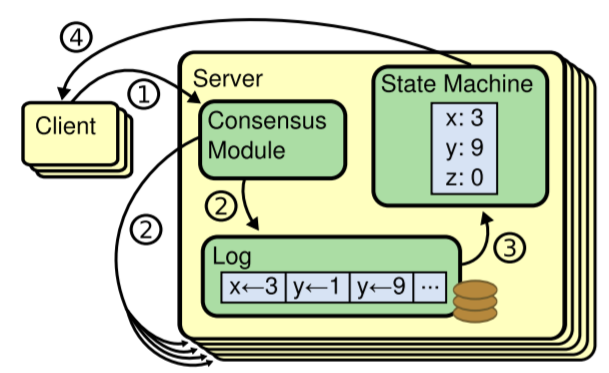
共识算法有以下特性:
- 在非拜占庭条件下保证安全性;
- 只要多数服务器可操作能够相互通信,共识算法就是可用的;
- 不依赖时钟;
- 只要大部分节点相应了,那么提交的命令就认为已经完成。
为了便于理解而设计
Paxos首次解决了一致性协议问题,但是问题在于:
- Paxos很难理解
- Paxos并没有给工程实现提供很好的基础
Raft主要使用了两个思路提高可理解性:
- 将问题分为多个子问题独立解决;
- 简化需要考虑的状态数量,提高系统一致性,排除不确定性。
Raft共识算法
Raft完整算法如下图所示:

Raft算法可以分为三个子问题进行讨论:
- 领导选举:当存领导故障之后,如何选举出新的领导;
- 日志备份:领导从客户端接收日志条目备份到集群上;
- 安全性:Raft的安全性保证如下
- 选举安全性:一个term中最多选举出一个领导;
- 领导只能追加:领导永远不会删除日志中的条目,只会追加新的条目;
- 日志匹配:如果两个日志中的条目具有相同的
index和term,那么到这条为止的日志条目都是相同的; - 领导完整性:如果一个日志条目被提交到了一个term里,那这个日志条目会出现在所有高term领导的日志中;
- 状态机安全性:如果一个服务器将一个日志条目应用到了状态机中,不存在其他服务器应用了相同
index的其他不同命令。
Raft基础
任何服务器会处于三种状态的一种:领导、下属和候选,状态的切换状态机如下所示:
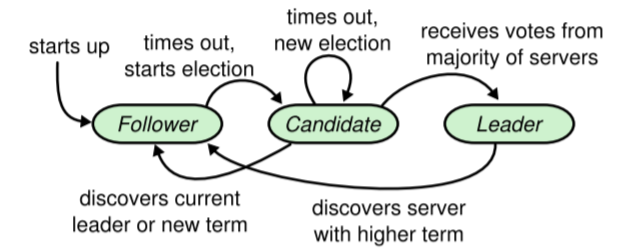
Raft将时间划分为任意长度的term,每个term从一次选举开始,赢得选举的节点作为当前term的领导。当选举失败或者领导节点崩溃,那么需要开始一个新的term。
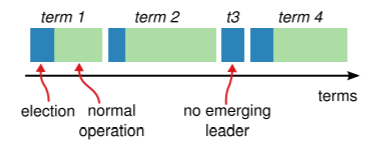
领导选举
领导周期性向下属发送AppendEntries RPC来保持“心跳”,如果没有新增的日志就发送空内容,当下属在一段时间(选举超时)内没有收到任何消息时,那么进入候选状态启动选举。如果候选人得到多数服务器的投票,服务器转换为领导状态,向其他服务器发送AppendEntries RPC。
为了避免同时产生多个候选节点,每个服务器的选举超时时间都需要从一个区间中随机选择。在集群没有领导的时候,候选节点需要等待一段选举超时时间后再开始下一轮选举。
日志备份
领导节点从客户端接收条目后追加到自己的日志中,然后通过AppendEntries RPC将日志发送给其他节点建立副本。当领导得知副本到达多数节点后,即可提交日志条目。Raft保证已经提交的条目是持久的,并且最终会被全部可用的状态机执行。当日志条目备份到了多数的服务器上,那么即可提交:
Raft满足以下特征来保证日志匹配性:
- 如果不同日志中两个条目有相同的
term和index,那么他们保存同一条命令; - 如果不同日志中两个条目有相同的
term和index,那么他们之前的所有日志都是相同的。
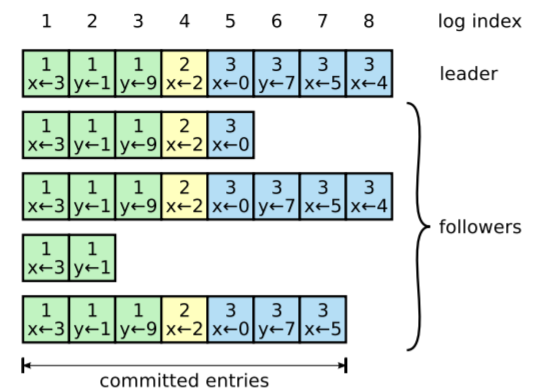
当领导节点开始管理集群的时候,各个服务器上的日志可能如下:
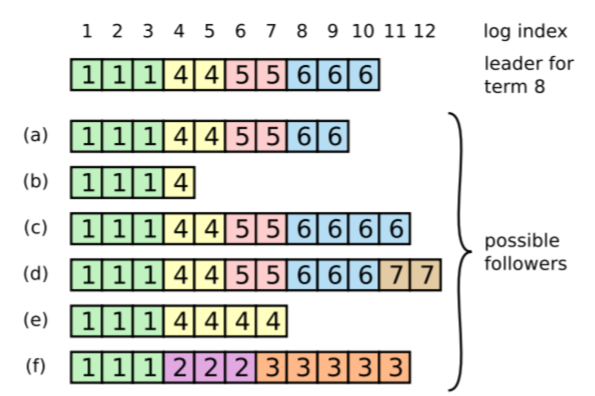
有些下属丢失了日志条目(a-b),有些下属包含了额外但是尚未提交的条目(c-d),或者两种情况都有(e-f)。其中f是因为它是term2和3的领导,但是都没有提交成功任何条目。无论如何,下属服务器上的日志中冲突的条目会被领导的日志所覆盖。
领导服务器维护了nextIndex来保存需要发送给下属的下一个条目,当领导初始化的时候,将nextIndex初始化为服务器的最后一个条目。如果下属服务器的日志和领导服务器日志不一样,那么AppendEntries RPC会失败,这个时候领导将nextIndex减一之后重试。对于那些因为故障导致日志丢失或者落后的服务器,AppendEntries的一致性检查能够帮助恢复日志。
安全性
选举限制
领导完整性要求任意一个term的领导必须包含之前term提交的所有日志条目。为了保证这个特征,Raft要求候选服务器必须包含所有的提交日志才能获得选举。因此,RequestVote RPC包含了候选服务器的日志,如果投票服务器的日志更新,那么拒绝投票。
提交先前term的条目
Raft永远不会提交之前term的条目。如下图,假设领导节点S1将2备份到S2之后掉线(a),然后S5成为领导收到3后掉线(b),然后S1重新成为领导后继续备份2到大多数节点后提交2,但是再次下线(c),但是如果S5重新成为领导之后会覆盖2(d),但是如果4被提交的话,2就不会被覆盖,因为S5不可能成为领导。
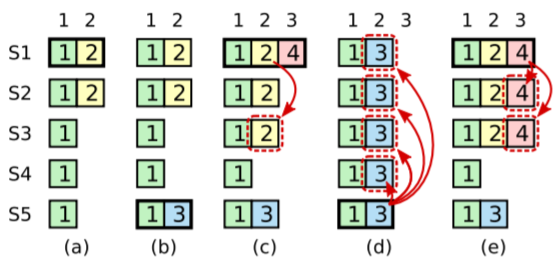
Raft领导只会提交当前term之内的条目;这样一来,当一个条目提交之后,能够确保之前所有的条目都被提交,满足日志匹配性。
安全性讨论
我们可以使用反证法证明领导完整性成立。假设在term提交的一条日志条目没有保存到未来的领导服务器日志中。那么令不包含该条条目的最小term为U()。
- 那么在选举的时候,该条目一定不在领导U的日志中(领导服务器绝不删除和覆盖日志);
- 那么领导T一定在多数服务器熵备份了该日志,同时领导U收到了多数投票;
- 那么至少有一个投票给领导U服务器收到了提交的条目;
- 因此在投票给U的时候必然已经保存了该条目;
- 既然投票给了U,那么领导U的日志至少和投票者一样新,那么不可能不包含该日志条目,与假设冲突。
领导完整性成立进一步可以证明状态机安全性。
下属和候选服务器崩溃
下属和候选服务器崩溃之后,RPC请求就会失败,Raft采用无限次尝试的方法,当服务器重启之后随着RPC处理的进行自然恢复。
时间和可用性
Raft的安全性并不依赖于时间:系统不会因为某些事件发生地更快或者更慢而产生不正确地结果。
但是,Raft对于选举超时时间还是有着一定地要求:
broadcastTime是服务器并行向所有其他服务器发送RPC需要地时间,MTBF是单个服务器发送故障的平均时间。
集群成员管理变更
为了保障安全性,配置更改需要使用两阶段的形式。在Raft中应用配置更改的时候,首先进入一个称为联合共识的过渡状态,在这个状态中
- 日志条目在两种配置的服务器上均保留副本;
- 两个配置的服务器都可以称为领导;
- 一致需要分别得到两种配置服务器的多数认同。
集群配置被保存在一个特殊的日志条目中,一旦一个服务器将新配置条目加入日志,它就会在未来所有操作中使用新的配置。
配置变更过程如下:
- 提交并应用过渡状态
(保存在新集群中的多数和旧集群中的多数),这时就可以安全地尝试提交
了;
- 提交并应用新的配置
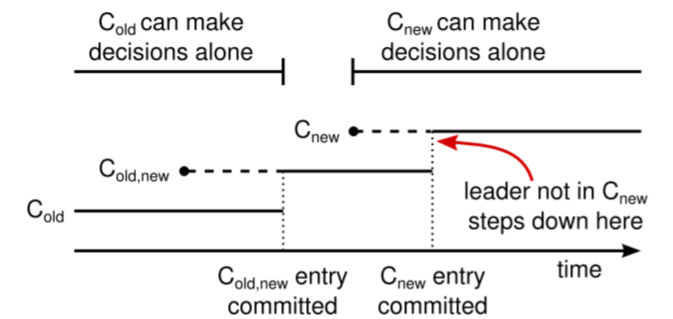
在变更配置的时候会存在以下三个问题:
- 新的服务器最初没有任何日志条目。如果直接参与共识,需要耗费大量时间。因此,在添加新服务器之前,可以将它作为无投票权节点直接从领导节点获取日志条目。
- 领导节点不再是新配置下的成员。这种情况下,在提交
- 已经移除的服务器可能会干扰现有的集群。
提交之后,旧节点不再会接收到心跳,它们会超时发起选举干扰新节点,可以让新节点无视收到心跳包一定时间内的RequestVote来解决。
日志压缩
根据Raft算法,重启的节点可以重放日志进行恢复,但是如果日志很长会给恢复过程带来压力。一个直观的方法就是通过快照来压缩日志。
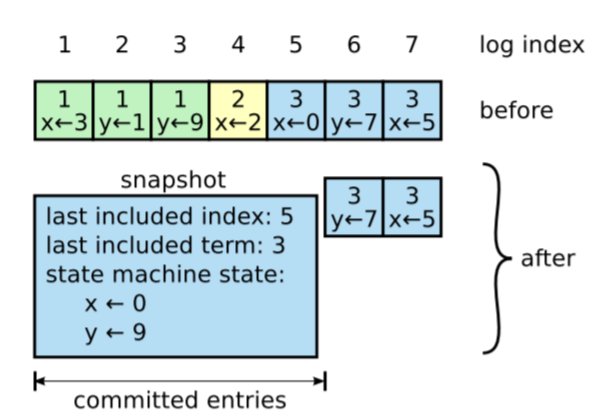
每个节点独立维护自己的快照,只将已经提交的日志保存到快照中。节点需要保存快照包含的最后一个term和index用于处理AppendEntries是检查一致性。对于领导节点,需要发送InstallSnapshot远程调用将自己的快照给那些落后的节点帮助其赶上最新状态。

快照机制存在两个性能问题:
- 创建快照的时机:太快消耗存储,太慢拖慢恢复,简单的策略可以在达到一定大小后再写入;
- 写入快照会花费大量的时间:针对快照更新采用写时复制,避免了不必要的复制。
客户端交互
客户端需要找到正确的领导节点,客户端会随机连接一个节点,随机节点会告知客户端领导节点的信息。
如果领导节点在提交某日志条目后没来得及通知客户端时崩溃,那么客户端联系新领导节点重试的时候重复执行指令,可以让客户端给每一个指令设置一个序列号解决。
由于只读操作不需要提交日志条目,因此可能会从旧的领导节点读取旧数据,Raft使用了两个额外要求来解决:
- 首先领导节点必须拥有最新的提交条目;
- 领导节点在响应只读操作的时候需要确认自己是否被遗弃。
参考文献
- Ongaro, Diego, and John K. Ousterhout. "In search of an understandable consensus algorithm." USENIX Annual Technical Conference. 2014.
