

前言
前一章我们已经知道了答题的服务器和客户端的工作流程,大体的请求头和响应头的结构如下图
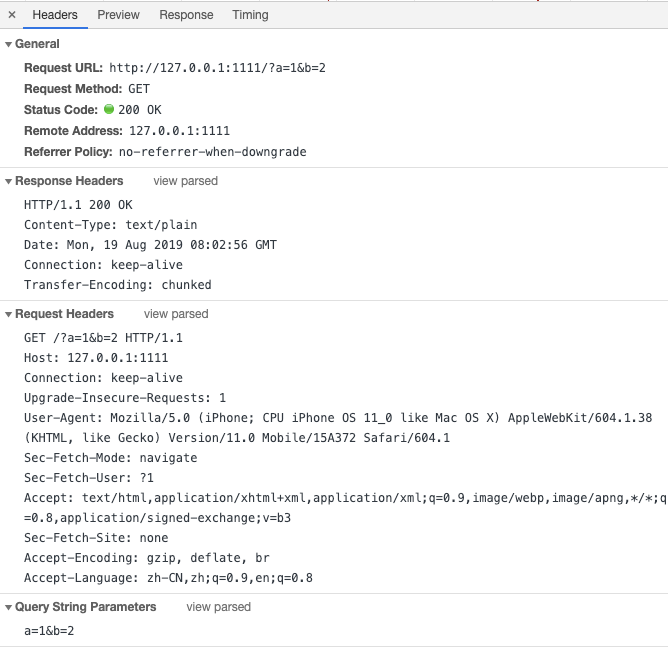
在具体的业务中,我们可能的需求有:
* 请求方法的判断
* URL的路径解析
* URL中查询字符串解析
* Cookie的解析
* Basic认证
* 表单数据的解析
* 任意格式文件的上传处理
* session会话
基础功能
请求方法
在web应用中最常见的是GET 和 POST 请求。
除此之外,还有HEAD、DELETE、PUT、CONNECT等方法
请求方法一般位于报文的第一行的第一个单词,通常是大写
> GET /?a=1&b=2 HTTP/1.1
HTTP_Parse在解析报文的时候,将报文头取出来,设置为req.method
路径解析
路径通常存储于报文的第一个行的第二部分
> GET /?a=1&b=2 HTTP/1.1
HTTP_Parse在解析报文的时候,设置为req.url :
http://127.0.0.1:1111/?a=1&b=2
查询字符串
查询字符串通常存储于报文的第一个行的第二部分
> ?a=1&b=2
Node提供了 queryString 模块处理这部分数据
var url = require('url');
var queryString = require('queryString');
var query = queryString.parse(url.parse(req.url).query);
会将 a=1&b=2 解析为一个JSON对象
{
a: 1,
b: 2
}
Cookie
Cookie用于认证用户,一般的处理分为以下几步:
服务器向客户端发送Cookie
浏览器存储Cookie
之后每次浏览器都会将Cookie发向服务器
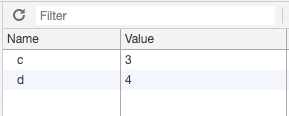
HTTP_Parse会将所有的报文文字解析到req.headers上。 Cookie 就可以通过 req.headers.cookie 格式为 key=value;key2=value2形式
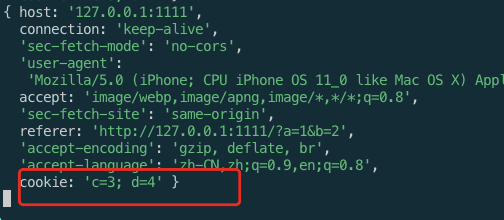
设置cookie有以下几个选项
path:表示这个cookie影响到的路径
Expirse:和Max-age:用来告诉浏览器何时过期
httpOnly:告知浏览器不允许通过脚本设置cooikie这个值,且设置该属性后,document.cookie是获取达不到的 但在http请求中还是会发送到服务器重的
Secure:当为true时,在http中无效。
cookie对性能的影响
一但cookie过多,就会造成带宽的浪费,所以
1.减小cookie的大小
2.为静态组建使用不同的域名
3.减少DNS解析
Session
Session数据只存在于服务器端,客户端无法修改
相当于与cookie 而言,cookie对于敏感数据的保存是无效的
将客户端的数据和服务器中的数据一一对应起来,有两种方式
第一种。基于cookie来实现用户和数据的映射
第二种。通过查询字符串来实现浏览器端和服务端数据的对应
缓存
web应用需要传输构成页面的组建(HTML、JavaScirpt、CSS文件等),这部分内容在大多数情境下不需要经常变更,却需要每次在应用中向客户端传递,如果不禁想处理,将导致不必要的带宽浪费,如果网络速度差,就需要花费更长的事件打开页面,对于用户体验不是很好。所以,为了提高性能YSlow中提到几条关于缓存的规则:
1.添加Expirse 或者 Cache-Control到报文头中
2.配置ETags
3.让ajax可以缓存
清除缓存
虽然知道了如何设置缓存,以达到节省网络宽带的目的,但是一旦缓存设立,当服务器意外更新内容时候,却无法通知客户端进行刷新。所幸得是浏览器是根据url进行缓存的,只要重新发起新的URL,就可以是的新内容能够被客户端更新,一般的更新机制有以下两种
1.每次发布,路径跟随web应用的版本号,http://url.com/?v=6797897890
2.每次发布,路径中跟随文件内容更新的hash值: http://url.com/?hash=dsgfjsdfds
Basic 认证
当客户端与服务器进行请求时,允许通过用户名和密码实现的一种身份认证方式,
他会检查报文重的Autorization字段,该字段的值由认证方式和加密值构成
数据上传
在业务中,我们往往需要接收一下数据:表单提交、文件提交、JSON上传、XML文件上传等
表单数据
默认的表单提交,请求头中的Content-Type字段值为application/x-www-form-urlencided
由于他的报文体内容跟查询字符串相同 a=1&b=2
所以解析它十分简单 req.body就可以得到
其他格式
除了表单之外,常见的提交还有JSON 和 XML文件。
JSON 的 Content-Type字段值为application/json
XML 的 Content-Type字段值为application/xml
附件上传
通常的表单。可以通过urlencoded的方式编码内容形成报文体,在发送给服务器端,但是业务场景往往需要用户直接提交文件。
特殊表单与普通表单的差异在于该表中可以含有file类型的控件。以及需要制定表单属性enctype为multipart/form-data
报文是一下这种形式的
Contetn-Type: multipart/form-data; boundary=Aabo3x
Content-Length: 17689
boundary值得是每部分内容的分界。Content-Length报文的长度
数据长传与安全
1.内存限制
解析表单时候,先保存用户的提交的所有数据,然后再解析处理,最后才传递给业务逻辑。潜在的隐患是,仅仅适合数量小的请求,一旦数据量过大,就会导致内存益处,攻击者只要伪造大量的请求,就可以把内存吃光。要解决这个问题有两个方法
a:限制文件上传的大小,一旦超出限制,停止接收数据并返回400状态码
b:通过流式解析,将数据流导向到磁盘中,Node中只保留文件路径等小数据
2.CSRF 跨站请求伪造
路由解析
通常我们对于不同的业务有不同的处理方式,执行不同的模块或者页面,这就引入了路由的问题。MVC、RESTful等路由的方式
文件路径型
1.静态文件
这种方式的路由,其网站目录的路径与URL路径一致,无需转换,
2.动态文件
在MVC模式流行起来之前,根据文件路径执行动态脚本,也是基本的路由方式,服务器根据文件名称后缀去寻找脚本的解析器,并且传入HTTP请求的上下文
MVC
MVC模型的主要思想是将业务逻辑按指责分离,主要分为以下几种
1.控制器(Controller),一组行为的集合
2.模型(Model),数据相关演的操作和封装
3.视图(view),视图的渲染
工作模式大概:
路由解析:根据URl寻找对应的控制的器的行文
行为调用相关的模型,进行数据操作
数据操作结束后,调用视图和相关的数据进行页面渲染,输出的客户端
1.手工映射
手工映射除了需要手工配置路由比较原始以外,他对URL的要求非常灵活
/user/setting
/settting/user
路径解析的方式:正则解析,参数解析
//这里假设已经拥有一个处理设置用户信息的控制器
exports.setting = function (req, res) {
//TODO
}
//再添加一个映射的方法就可以了,这个方法名字叫做 use()
var routers = [];
var use = function(path, action) {
routers.push([path, action]);
}
//入口程序判断url,执行对相应的逻辑,于是就完成了基本的路由映射过程
function(req, res) {
var pathname = url.parse(req.url).pathname;
for(var i=0; i < routers; i++) {
var route = routers[i];
if (pathname = route[0]) {
var action = routep[1];
action(req, res);
return;
}
}
//处理404请求
handle404(req, res)
}
user('/user/setting', exports.setting);
2.自然映射
RESTful 将HTTP的方法也加入了路由的操作,通过accept决定资源的表现形式
app.post(url, addFn);
app.delete(url2,deletFn);
中间件 Connect
Connect 是一个 node 中间件框架。Express 就是基于 Connect 开发的。
如果把一个 HTTP 处理过程比作是污水处理,中间件就像是一层层的过滤网,过滤网有各自不同的作用。
Connect 中间件就是 JavaScript 函数。函数一般有三个参数:
req(请求对象)
res(响应对象)
next(回调函数)
一个中间件完成自己的工作后,如果要执行后续的中间件,需要调用 next 回调函数
const connect = require('connect');
// 输出 HTTP 请求的方法和 URL 并调用 next() 执行后续中间件
function logger(req, res, next) {
console.log('%s %s', req.method, req.url);
next();
}
// 响应 HTTP 的请求
function hello(req, res, next) {
res.setHeader('Content-Type', 'text/plain');
res.end('hello world');
}
// 按顺序组合中间件
connect()
.use(logger)
.use(hello)
.listen(3000);
注意组合中间件的顺序很重要,如果某个中间件不调用next() ,那么在它后面的中间件就不会被调用
中间件如何进行错误处理?
Connect 有一种用来处理错误的中间件变体,比常规中间件多了一个错误对象参数。
必须有四个参数:err 、req 、res 、next
错误处理中间件有两种工作机制:
用 Connect 的默认错误处理器(自动处理)
自行处理
当 Connect 遇到错误时,会跳过常规中间件,只去调用错误处理中间件。比如:
connect()
.use(mw1) // 出错
.use(mw2) // 跳过
.use(mw3) // 跳过
.use(errorHandler) // 执行
页面渲染
内容响应
内容响应的过程中,响应报文头重的Content-* 字段非常重要
下列响应的报文中告诉客户端内容是以gzip编码的,其中内容长度为21170字节,内容类型为JS,字符集为utf-8
Content-Encoding: Gzip;
Content-Length: 21170;
Content-Type: Text/JavaScript; Charset=Utf-8; (不同的文件有不同的MIME值)
附件下载
Content-Disposition字段 inline/即时查看 attcahment/附件查看
响应JSON
res.setHeader('Content-type', 'application/json');
视图渲染
app.get('/error', function(req, res){
res.status(500);
res.render('error');
});
模版
express中间件
新建网页模板
新建模板文件的index.html。
<!-- views/index.html文件 -->
<h1>文章列表</h1>
{{#each entries}}
<p>
<a href="/article/{{id}}">{{title}}</a><br/>
Published: {{published}}
</p>
{{/each}}
模板文件about.html。
<!-- views/about.html文件 -->
<h1>自我介绍</h1>
<p>正文</p>
模板文件article.html。
<!-- views/article.html文件 -->
<h1>{{blog.title}}</h1>
Published: {{blog.published}}
<p/>
{{blog.body}}
可以看到,上面三个模板文件都只有网页主体。因为网页布局是共享的,所以布局的部分可以单独新建一个文件的layout.html。
<!-- views/layout.html文件 -->
<html>
<head>
<title>{{title}}</title>
</head>
<body>
{{{body}}}
<footer>
<p>
<a href="/">首页</a> - <a href="/about">自我介绍</a>
</p>
</footer>
</body>
</html>
渲染模板
// app.js文件
var express = require('express');
var app = express();
var hbs = require('hbs');
// 加载数据模块
var blogEngine = require('./blog');
app.set('view engine', 'html');
app.engine('html', hbs.__express);
app.use(express.bodyParser());
app.get('/', function(req, res) {
res.render('index',{title:"最近文章", entries:blogEngine.getBlogEntries()});
});
app.get('/about', function(req, res) {
res.render('about', {title:"自我介绍"});
});
app.get('/article/:id', function(req, res) {
var entry = blogEngine.getBlogEntry(req.params.id);
res.render('article',{title:entry.title, blog:entry});
});
app.listen(3000);
