

1.项目介绍
1.1 为什么要写这个文档
因为这个项目是一个整体逻辑上比较简单的项目,没有新东西,但仔细想想,在解决不同问题过程中,不要停留于为了解决问题而解决问题。写这个问题是为了能在以后碰到类似的问题,我能有相关的经验;同时能够对所用的知识点都能够串起来。思考是否能用在以后的项目中?
1.2 项目介绍
功能:主要是对两个不同模型的生成数据进行融合后供页面信息展示。同时还包括对整个项目的移植打包。
技术栈:框架用的是Springboot,数据库用的是MongoDB
技术难点(对于我来说):
- 数据库MongoDB:部署,分片,聚合函数等;
- 虚拟机,docker:虚拟机和docker的区别,虚拟机与docker的配置;
- 文件流的操作:如何通过流发送文件?
- .sh文件:执行;权限问题;服务调用问题;
2.小收获
2.1 数据库
1.数据导入导出:除去可视化界面直接操作,用命令导入导出是:
sudo mongoimport --db newdb --collection restaurants --file text.json
sudo mongoexport --db airport -c text --out text.json
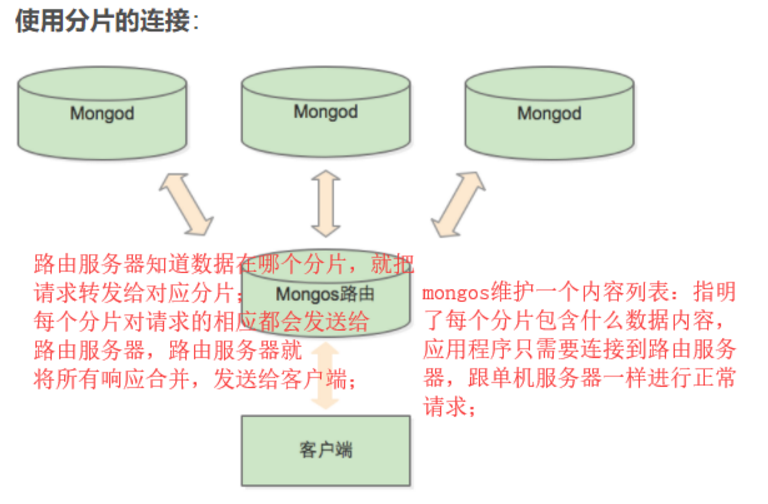
2.分片与复制集:
- 为什么需要用到mongoDB分片集群?
如果用mongoDB存储的话,数据量大,大量读写,吞吐量很大的情况下,单个server很难满足需求,所以需要用到mongoDB分片集群。(与关系型数据库中的分区方案对比???)
- 什么是分片?
分片:sharding 指的是把数据拆分,将其分散存储在不同的机器上;有时也用partitioning表示这个概念;
mongoDB支持自动分片 auto sharding;可以使得数据库架构对应用程序不可见,也可以简化系统管理。mongoDB自动处理数据在分片上的分布,也更容易添加和删除分片。
分片优点:
1.对集群进行抽象,让集群对于用户来说是不可见的
2.保证集群总是可以读写
3.使得集群易于扩展:当系统需要更多空间和资源,mongoDB可以使我们按需方便的扩充系统容量。
-
复制集
复制是让多台服务器都拥有同样的数据副本,每一台服务器都是其它服务器的镜像,而每一个分片和其它分片拥有不同的数据子集。 通过不同的机器保存副本用于保证数据的不会因为单点损失而丢失,主要用于应对数据丢失,机器损坏带来的风险;同时可以提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且不同服务器为不同的用户提供服务,提高整个系统的负载。
主要是防止数据库崩溃带来的损失,保证数据库的高可用。
- 分片、分区、复制(mongoDB mysql)
分区:优化查询,防止一张表中过多的数据导致查询缓慢
MongoDB:无分表的概念,可以用sharding代替分类(sharding有索引的功能)
MySQL:partition
分片:解决物理磁盘空间不足问题(若带索引,还可以优化查询,做到分区的功能)
MongoDB:sharding
Mysql:mysql-cluster
复制:主要是防止数据库崩溃带来的损失,保证数据库的高可用 MongoDB:master 主 slave 从 Mysql:master 主 slave 从
参考原来的博客:juejin.cn/post/684490…
3.聚合函数:js 与 java实现
参考原来的博客:juejin.cn/post/684490…
2.2 虚拟机
1.docker和虚拟机的区别:
2.docker的配置:应用;
3.虚拟机
2.3 Linux中可执行文件.sh编写与调用
- .sh文件:权限和编写
-
创建文件
-
给文件赋权
sudo chmod 777 xxx.sh
- java调用,python调用
- python调用
os.system("bash -C './xxx.sh'");
2.4 流的操作
- 发送和接受
- 例子:常用的类
2.5 端口占用问题
1.linux如何查看?
netstat -anp | grep 端口号
3.总结
在做这个项目的过程中,虽然使用到的技术都不是很新,但是每次新学的都做了一定的总结。
- 首先是数据库,MongoDB,主要是会用mongoDB基本操作,查询语句的编写,以及分片在单机上的伪搭建。
- 虚拟机docker的使用,需要更深入的学习。关于dockerfile的编写。
- 文件流的操作,更多关心如何传送大文件,待考虑?
- java调用Linux shell脚本,python调用Linux shell脚本。
- 前后端分离中,路由分配问题,servlet-path问题。
- Linux中用户权限管理。
