

这里说的仅仅只是关于编码问题的一些小思考,简单过一下。
关于编码
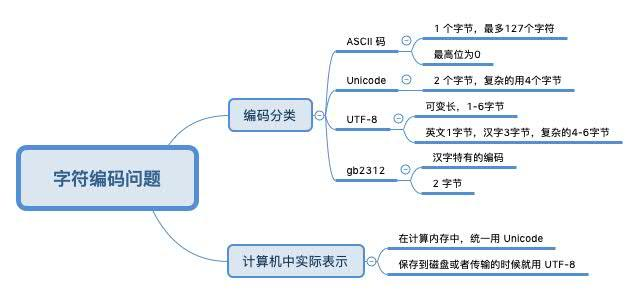
验证
以往我们可能了解的都是一些理论知道,下面我们来通过 Python3 来验证一下。分别来看看英文字符 ‘A’ 和 ‘中’ 分别在不同编码下的实际情况。
A 的 ASCII 、UTF-8、GB2312 编码
>>> 'A'.encode('ascii')
b'A'
>>> 'A'.encode('utf-8')
b'A'
>>> 'A'.encode('gb2312')
b'A'
中的 ASCII 、UTF-8、GB2312 编码
>>> '中'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\\u4e2d' in position 0: ordinal not in range(128)
>>> '中'.encode('utf-8')
b'\\xe4\\xb8\\xad'
>>> '中'.encode('gb2312')
b'\\xd6\\xd0'
可以看到中文是不能进行 ASCII 编码的
本次的分享也是简单跟大家说了一下关于ASCII、Unicode、UTF-8编码问题的小思考,相信大家也已经都明白了,更多的Python相关知识技巧也会继续为大家分享!
