

FROM:残差网络(Residual Networks, ResNets)
残差
假设我们想要找一个 x,使得 f(x)=b,给定一个 x 的估计值 x0
- 残差(residual):b−f(x0)
- 误差: x−x0
残差网络(Residual Networks,ResNets)
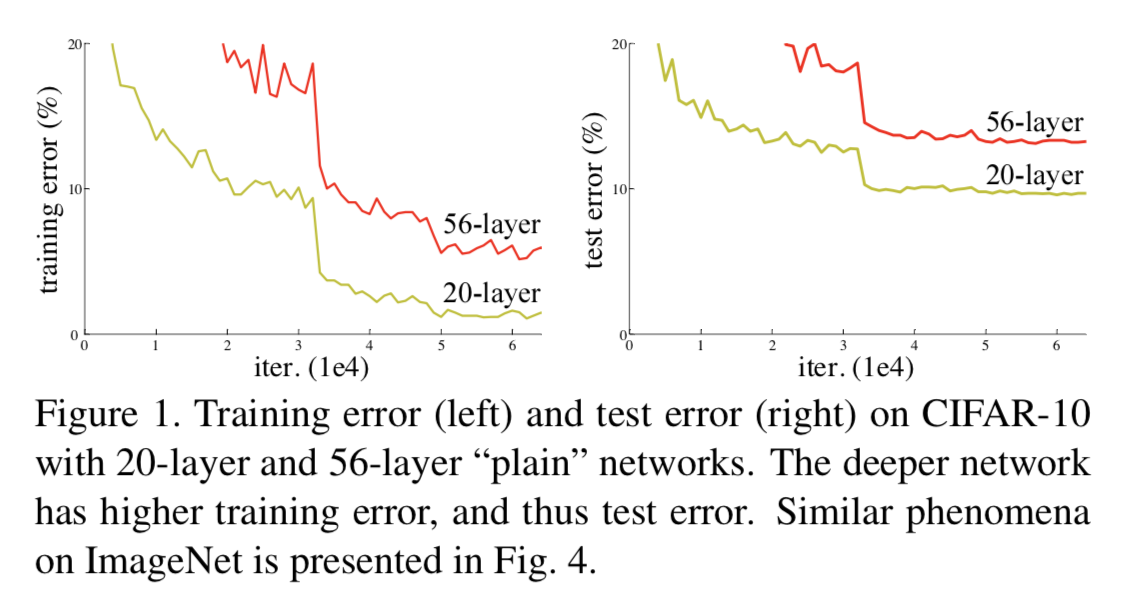
越深(deeper)的网络不会比浅层的网络效果差。由于退化问题,网络的优化变难,效果反而不如较浅(shallower)网络。
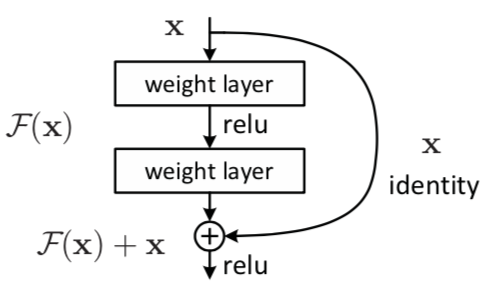
残差块(residual block)
原因
如果在该 2层网络中,最优的输出就是输入 x,那么对于没有 shortcut connection 的网络,就需要将其优化成 H(x)=x;对于有 shortcut connection 的网络,即残差块,最优输出是 x,则只需要将 F(x)=H(x)−x 优化为 0 即可。后者的优化会比前者简单。
我们给一个网络不论在中间还是末尾加上一个残差块,并给残差块中的 weights 加上 L2 regularization(weight decay),这样图 1 中 F(x)=0 是很容易的。这种情况下加上一个残差块和不加之前的效果会是一样,所以加上残差块不会使得效果变得差。如果残差块中的隐藏单元学到了一些有用信息,那么它可能比 identity mapping(即 F(x)=0)表现的更好。
举例
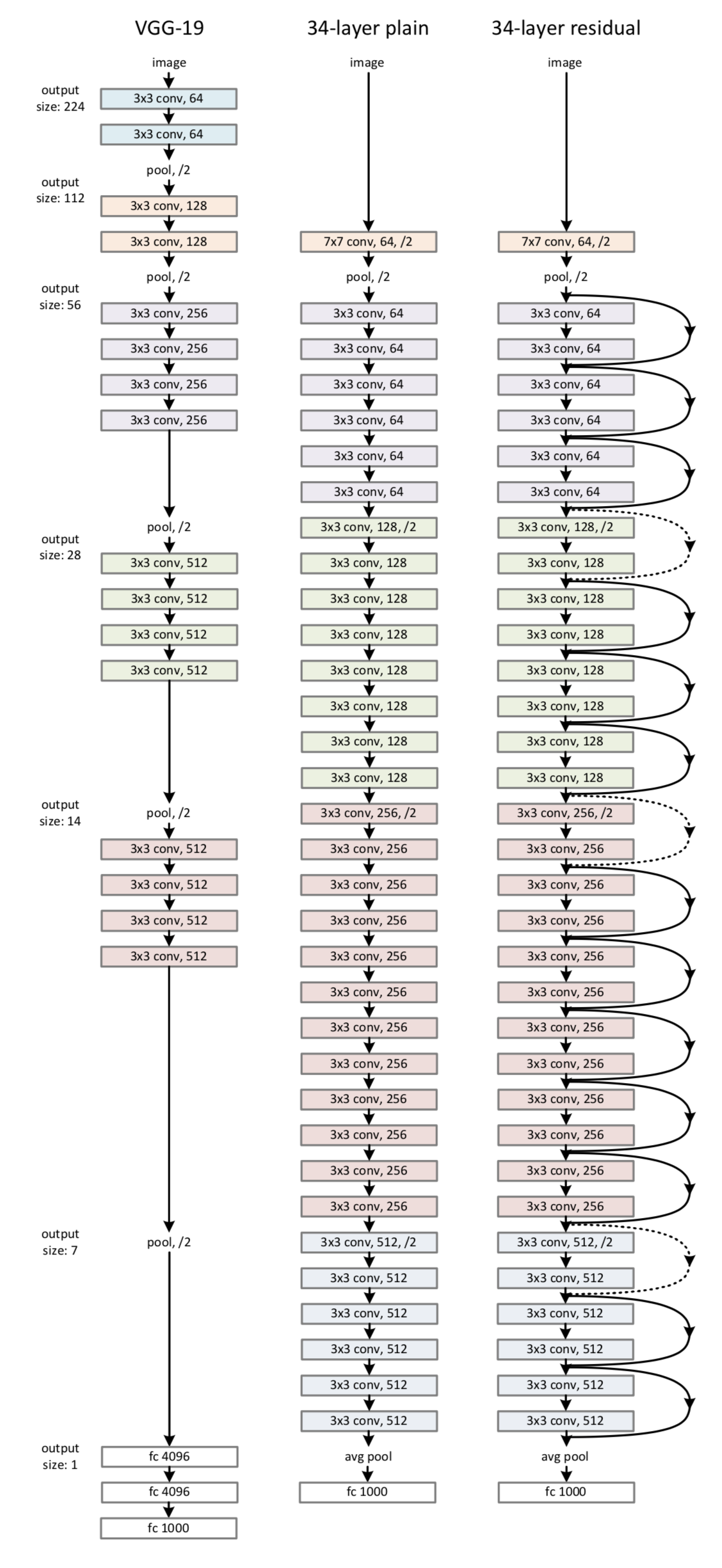
feature map 减半时,filter 的个数翻倍,这样保证了每一层的计算复杂度一致。
ResNet 因为使用 identity mapping,在 shortcut connections 上没有参数,所以 plain network 和 residual network的计算复杂度都是一样的,都是 3.6 billion FLOPs.
