

- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
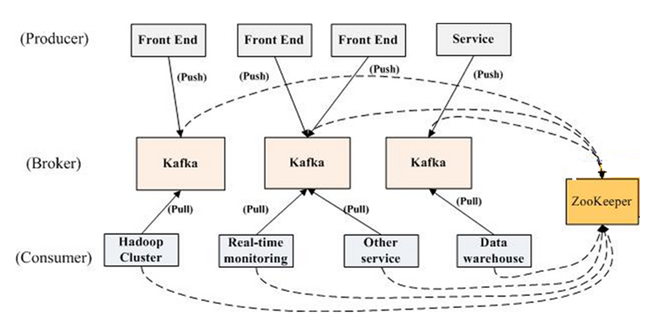
- Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
- Segment:partition物理上由多个segment组成,每个Segment存着message信息
- Producer : 生产message发送到topic
- Consumer : 订阅topic消费message, consumer作为一个线程来消费
- Consumer Group:一个Consumer Group包含多个consumer, 这个是预先在配置文件中配置好的。各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group ) 中的一个consumer(consumer 线程 )消费,如果一个message可以被多个consumer(consumer 线程 ) 消费的话,那么这些consumer必须在不同的组。它不能像AMQ那样可以多个BET作为consumer去处理message,这是因为多个BET去消费一个Queue中的数据的时候,由于要保证不能多个线程拿同一条message,所以就需要行级别悲观锁(for update),这就导致了consume的性能下降,吞吐量不够。而kafka为了保证吞吐量,只允许一个consumer线程去访问一个partition。如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。
1.4 Kakfa的设计思想
Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。
例如:一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
这里曾经还有一个bug,TalkingData使用Kafka0.8.1的时候,当ack=0的时候,表示producer发送出去message,只要对应的kafka broker topic partition leader接收到的这条message,producer就返回成功,不管partition leader 是否真的成功把message真正存到kafka。当ack=1的时候,表示producer发送出去message,同步的把message存到对应topic的partition的leader上,然后producer就返回成功,partition leader异步的把message同步到其他partition replica上。当ack=all或-1,表示producer发送出去message,同步的把message存到对应topic的partition的leader和对应的replica上之后,才返回成功。但是如果某个kafka controller 切换的时候,会导致partition leader的切换(老的 kafka controller上面的partition leader会选举到其他的kafka broker上),但是这样就会导致丢数据。
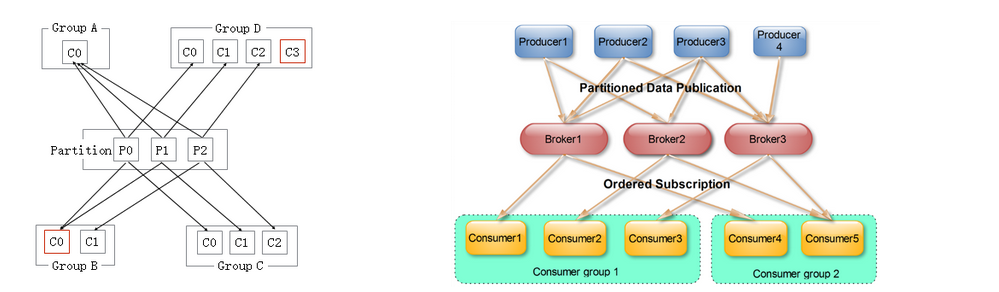
一个consumer group下,无论有多少个consumer,这个consumer group一定回去把这个topic下所有的partition都消费了。当consumer group里面的consumer数量小于这个topic下的partition数量的时候,如下图groupA,groupB,就会出现一个conusmer thread消费多个partition的情况,总之是这个topic下的partition都会被消费。如果consumer group里面的consumer数量等于这个topic下的partition数量的时候,如下图groupC,此时效率是最高的,每个partition都有一个consumer thread去消费。当consumer group里面的consumer数量大于这个topic下的partition数量的时候,如下图GroupD,就会有一个consumer thread空闲。因此,我们在设定consumer group的时候,只需要指明里面有几个consumer数量即可,无需指定对应的消费partition序号,consumer会自动进行rebalance。
Consumer Rebalance的触发条件:
- Consumer增加或删除会触发 Consumer Group的Rebalance
- Broker的增加或者减少都会触发 Consumer Rebalance
Kafka producer 发送message不用维护message的offset信息,因为这个时候,offset就相当于一个自增id,producer就尽管发送message就好了。而且Kafka与AMQ不同,AMQ大都用在处理业务逻辑上,而Kafka大都是日志,所以Kafka的producer一般都是大批量的batch发送message,向这个topic一次性发送一大批message,load balance到一个partition上,一起插进去,offset作为自增id自己增加就好。但是Consumer端是需要维护这个partition当前消费到哪个message的offset信息的,这个offset信息,high level api是维护在Zookeeper上,low level api是自己的程序维护。(Kafka管理界面上只能显示high level api的consumer部分,因为low level api的partition offset信息是程序自己维护,kafka是不知道的,无法在管理界面上展示 )当使用high level api的时候,先拿message处理,再定时自动commit offset+1(也可以改成手动), 并且kakfa处理message是没有锁操作的。因此如果处理message失败,此时还没有commit offset+1,当consumer thread重启后会重复消费这个message。但是作为高吞吐量高并发的实时处理系统,at least once的情况下,至少一次会被处理到,是可以容忍的。如果无法容忍,就得使用low level api来自己程序维护这个offset信息,那么想什么时候commit offset+1就自己搞定了。
Topic相当于传统消息系统MQ中的一个队列queue,producer端发送的message必须指定是发送到哪个topic,但是不需要指定topic下的哪个partition,因为kafka会把收到的message进行load balance,均匀的分布在这个topic下的不同的partition上( hash(message) % [broker数量] )。物理上存储上,这个topic会分成一个或多个partition,每个partiton相当于是一个子queue。在物理结构上,每个partition对应一个物理的目录(文件夹),文件夹命名是[topicname]_[partition]_[序号],一个topic可以有无数多的partition,根据业务需求和数据量来设置。在kafka配置文件中可随时更高num.partitions参数来配置更改topic的partition数量,在创建Topic时通过参数指定parittion数量。Topic创建之后通过Kafka提供的工具也可以修改partiton数量。
当add a new partition的时候,partition里面的message不会重新进行分配,原来的partition里面的message数据不会变,新加的这个partition刚开始是空的,随后进入这个topic的message就会重新参与所有partition的load balance
(1)怎样传送消息:producer先把message发送到partition leader,再由leader发送给其他partition follower。(如果让producer发送给每个replica那就太慢了)
(3)怎样处理某个Replica不工作的情况:如果这个不工作的partition replica不在ISR列表中,就是producer在发送消息到partition leader上,partition leader向partition follower发送message没有响应而已,这个不会影响整个系统,也不会有什么问题。如果这个不工作的partition replica在ISR列表中的话,producer发送的message的时候会等待这个不工作的partition replca写message成功,但是会等到time out,然后返回失败因为某个ISR列表中的partition replica没有响应,此时kafka会自动的把这个不工作的partition replica从ISR列表中移除,以后的producer发送message的时候就不会有这个ISR列表下的这个不工作的partition replica了。
Partition leader与follower:
partition也有leader和follower之分。leader是主partition,producer写kafka的时候先写partition leader,再由partition leader push给其他的partition follower。partition leader与follower的信息受Zookeeper控制,一旦partition leader所在的broker节点宕机,zookeeper会从其他的broker的partition follower上选择follower变为parition leader。
(1)将Broker(size=n)和待分配的Partition排序。
(2)将第i个Partition分配到第(i%n)个Broker上。
(3)将第i个Partition的第j个Replica分配到第((i + j) % n)个Broker上
- 第一种是啥都不管,发送出去就当作成功,这种情况当然不能保证消息成功投递到broker;
- 第二种是Master-Slave模型,只有当Master和所有Slave都接收到消息时,才算投递成功,这种模型提供了最高的投递可靠性,但是损伤了性能;
- 第三种模型,即只要Master确认收到消息就算投递成功;实际使用时,根据应用特性选择,绝大多数情况下都会中和可靠性和性能选择第三种模型
消息消费的可靠性,Kafka提供的是“At least once”模型,因为消息的读取进度由offset提供,offset可以由消费者自己维护也可以维护在zookeeper里,但是当消息消费后consumer挂掉,offset没有即时写回,就有可能发生重复读的情况,这种情况同样可以通过调整commit offset周期、阈值缓解,甚至消费者自己把消费和commit offset做成一个事务解决,但是如果你的应用不在乎重复消费,那就干脆不要解决,以换取最大的性能。
这个ack配置的是返回成功的服务器个数
当ack=1,表示producer写partition leader成功后,broker就返回成功,无论其他的partition follower是否写成功。这是默认配置
当ack=2,表示producer写partition leader和其他一个follower成功的时候,broker就返回成功,无论其他的partition follower是否写成功。
当ack=all /-1 的时候,表示只有producer全部写成功的时候,才算成功,kafka broker才返回成功信息。这里需要注意的是,如果ack=1的时候,一旦有个broker宕机导致partition的follower和leader切换,会导致丢数据。


在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
Kafka中会把消息持久化到本地文件系统中,并且保持o(1)极高的效率。我们众所周知IO读取是非常耗资源的性能也是最慢的,这就是为了数据库的瓶颈经常在IO上,需要换SSD硬盘的原因。但是Kafka作为吞吐量极高的MQ,却可以非常高效的message持久化到文件。这是因为Kafka是顺序写入o(1)的时间复杂度,速度非常快。也是高吞吐量的原因。由于message的写入持久化是顺序写入的,因此message在被消费的时候也是按顺序被消费的,保证partition的message是顺序消费的。一般的机器,单机每秒100k条数据。
Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
Producer向Topic发送message,不需要指定partition,直接发送就好了。kafka通过partition ack来控制是否发送成功并把信息返回给producer,producer可以有任意多的thread,这些kafka服务器端是不care的。Producer端的delivery guarantee默认是At least once的。也可以设置Producer异步发送实现At most once。Producer可以用主键幂等性实现Exactly once
Kafka的高吞吐量体现在读写上,分布式并发的读和写都非常快,写的性能体现在以o(1)的时间复杂度进行顺序写入。读的性能体现在以o(1)的时间复杂度进行顺序读取, 对topic进行partition分区,consume group中的consume线程可以以很高能性能进行顺序读。
Kafka支持以消息集合为单位进行批量发送,以提高push效率。
Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
Kafka提供了一个 metadata API来管理broker之间的负载(对Kafka0.8.x而言,对于0.7.x主要靠zookeeper来实现负载均衡)。
Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。
Kafka由于对可拓展的数据持久化的支持,它也非常适合向Hadoop或者数据仓库中进行数据装载。
kafka既支持离线数据也支持实时数据,因为kafka的message持久化到文件,并可以设置有效期,因此可以把kafka作为一个高效的存储来使用,可以作为离线数据供后面的分析。当然作为分布式实时消息系统,大多数情况下还是用于实时的数据处理的,但是当cosumer消费能力下降的时候可以通过message的持久化在淤积数据在kafka。
现在不少活跃的社区已经开发出不少插件来拓展Kafka的功能,如用来配合Storm、Hadoop、flume相关的插件。
可恢复性: 系统的一部分组件失效时,由于有partition的replica副本,不会影响到整个系统。
2.Kafka文件存储机制
- 2.2 kafka一些原理概念
其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略;压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑.可以将任何在网络上传输的消息都经过压缩.kafka支持gzip/snappy等多种压缩方式
什么szero-copy(零拷贝)
一个典型的web服务器传送静态文件(如CSS,JS,图片等)的过程如下:
write(socket, tmp_buf, len);
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
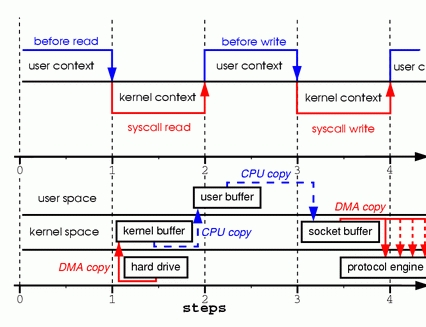
1。当调用read系统调用时,通过DMA(Direct Memory Access)将数据copy到内核模式
2。然后由CPU控制将内核模式数据copy到用户模式下的 buffer中
3。read调用完成后,write调用首先将用户模式下 buffer中的数据copy到内核模式下的socket buffer中
4。最后通过DMA copy将内核模式下的socket buffer中的数据copy到网卡设备中传送。
从上面的过程可以看出,数据白白从内核模式到用户模式走了一 圈,浪费了两次copy,而这两次copy都是CPU copy,即占用CPU资源。
Zero-Copy&Sendfile()
Linux 2.1版本内核引入了sendfile函数,用于将文件通过socket传送。
该函数通过一次系统调用完成了文件的传送,减少了原来 read/write方式的模式切换。此外更是减少了数据的copy,sendfile的详细过程图2所示:
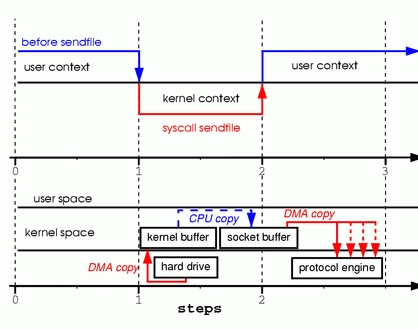
通过sendfile传送文件只需要一次系统调用,当调用 sendfile时:
1。首先通过DMA copy将数据从磁盘读取到kernel buffer中
2。然后通过CPU copy将数据从kernel buffer copy到sokcet buffer中
3。最终通过DMA copy将socket buffer中数据copy到网卡buffer中发送
sendfile与read/write方式相比,少了 一次模式切换一次CPU copy。但是从上述过程中也可以发现从kernel buffer中将数据copy到socket buffer是没必要的。
为此,Linux2.4内核对sendfile做了改进,如图3所示
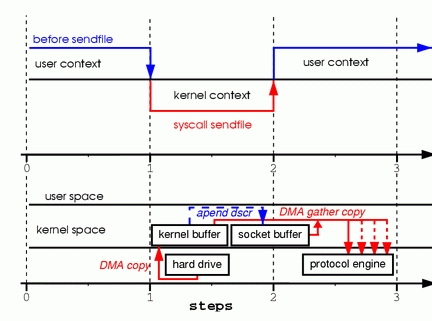
图3
改进后的处理过程如下:
1。DMA copy将磁盘数据copy到kernel buffer中
2。向socket buffer中追加当前要发送的数据在kernel buffer中的位置和偏移量
3。DMA gather copy根据socket buffer中的位置和偏移量直接将kernel buffer中的数据copy到网卡上。
经过上述过程,数据只经过了2次copy就从磁盘传送出去了。
(可能有人要纠结“不是说Zero-Copy么?怎么还有两次copy啊”,事实上这个Zero copy是针对内核来讲的,数据在内核模式下是Zero-copy的。话说回来,文件本身在磁盘上要真是完全Zero-copy就能传送,那才见鬼了呢)。
当前许多高性能 http server都引入了sendfile机制,如nginx,lighttpd等。
Java NIO中的transferTo()
Java NIO中
方法将当前通道中的数据传送到目标通道target中,在支持Zero-Copy的linux系统中,transferTo()的实现依赖于sendfile()调用。
kafka中consumer负责维护消息的消费记录,而broker则不关心这些,这种设计不仅提高了consumer端的灵活性,也适度的减轻了broker端设计的复杂度;这是和众多JMS prodiver的区别.此外,kafka中消息ACK的设计也和JMS有很大不同,kafka中的消息是批量(通常以消息的条数或者chunk的尺寸为单位)发送给consumer,当消息消费成功后,向zookeeper提交消息的offset,而不会向broker交付ACK.或许你已经意识到,这种"宽松"的设计,将会有"丢失"消息/"消息重发"的危险.
- at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中consumer进程失效(crash),导致部分消息未能继续处理.那么此后可能其他consumer会接管,但是因为offset已经提前保存,那么新的consumer将不能fetch到offset之前的消息(尽管它们尚没有被处理),这就是"at most once".
- at least once: 消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常或者consumer失效,导致保存offset操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once".
- "Kafka Cluster"到消费者的场景中可以采取以下方案来得到“恰好1次”的一致性语义:最少1次+消费者的输出中额外增加已处理消息最大编号:由于已处理消息最大编号的存在,不会出现重复处理消息的情况。
当consumer启动时,所触发的操作:
Kafka动态维护了一个同步状态的副本的集合(a set of in-sync replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息必须被这个集合中的每个节点读取并追加到日志中了,才回通知外部这个消息已经被提交了。因此这个集合中的任何一个节点随时都可以被选为leader.ISR在ZooKeeper中维护。ISR中有f+1个节点,就可以允许在f个节点down掉的情况下不会丢失消息并正常提供服务。ISR的成员是动态的,如果一个节点被淘汰了,当它重新达到“同步中”的状态时,他可以重新加入ISR.这种leader的选择方式是非常快速的,适合kafka的应用场景。
实际应用中,当所有的副本都down掉时,必须及时作出反应。可以有以下两种选择:
分析过程分为以下4个步骤:
- topic中partition存储分布
- partiton中文件存储方式 (partition在linux服务器上就是一个目录(文件夹))
- partiton中segment文件存储结构
- 在partition中如何通过offset查找message
通过上述4过程详细分析,我们就可以清楚认识到kafka文件存储机制的奥秘。
假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中server.properties文件配置(参数log.dirs=xxx/message-folder),例如创建2个topic名 称分别为report_push、launch_info, partitions数量都为partitions=4
存储路径和目录规则为:
xxx/message-folder
|--report_push-1
|--report_push-2
|--report_push-3
|--launch_info-0
|--launch_info-1
|--launch_info-2
|--launch_info-3
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
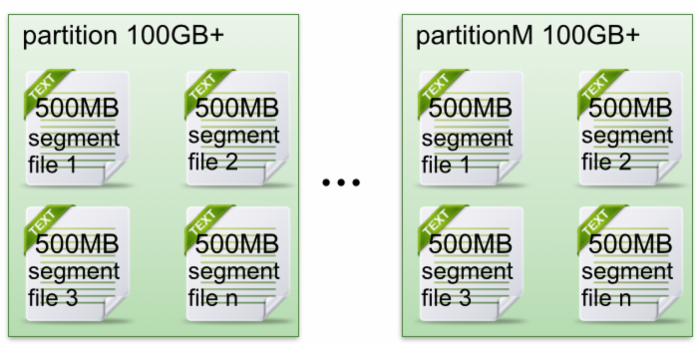
- segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀".index"和“.log”分别表示为segment索引文件、数据文件.
- segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局partion的最大offset(偏移message数)。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
下面文件列表是笔者在Kafka broker上做的一个实验,创建一个topicXXX包含1 partition,设置每个segment大小为500MB,并启动producer向Kafka broker写入大量数据,如下图2所示segment文件列表形象说明了上述2个规则:

以上述图2中一对segment file文件为例,说明segment中index<—->data file对应关系物理结构如下:

其中 .index索引文件是稀松索引,它 比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。N,posotion,N是相对于.log文件的消息偏移量,position是.log文件的物理地址.比如 其中以索引文件中 元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第3个也就是368769+3=368772个message)、以及该消息的物理偏移 地址为497。
从上述图3了解到segment data file由许多message组成,下面详细说明message物理结构如下:

参数说明:
| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic" | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes" | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
2.6 在partition中如何通过offset查找message
例如读取offset=368776的message,需要通过下面2个步骤查找。
第一步查找segment file
上述图2为例,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件 00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset **二分查找**文件列表,就可以快速定位到具体文件。
当offset=368776时定位到00000000000000368769.index|log
第二步通过segment file查找message通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和 00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到 offset=368776为止。
Kafka高效文件存储设计特点
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
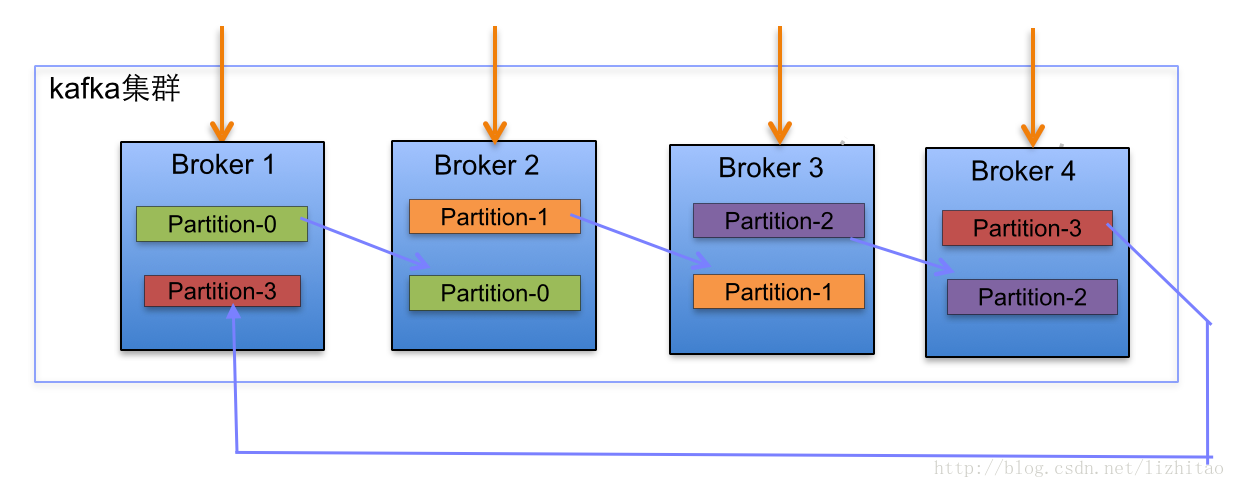
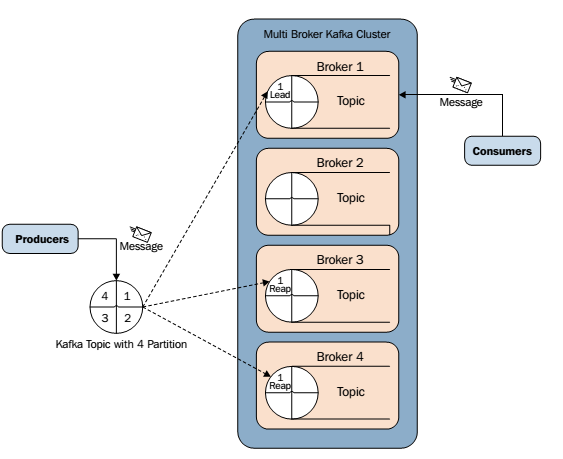
1. Kafka集群partition replication默认自动分配分析
下面以一个Kafka集群中4个Broker举例,创建1个topic包含4个Partition,2 Replication;数据Producer流动如图所示:
(1)
(2)当集群中新增2节点,Partition增加到6个时分布情况如下:
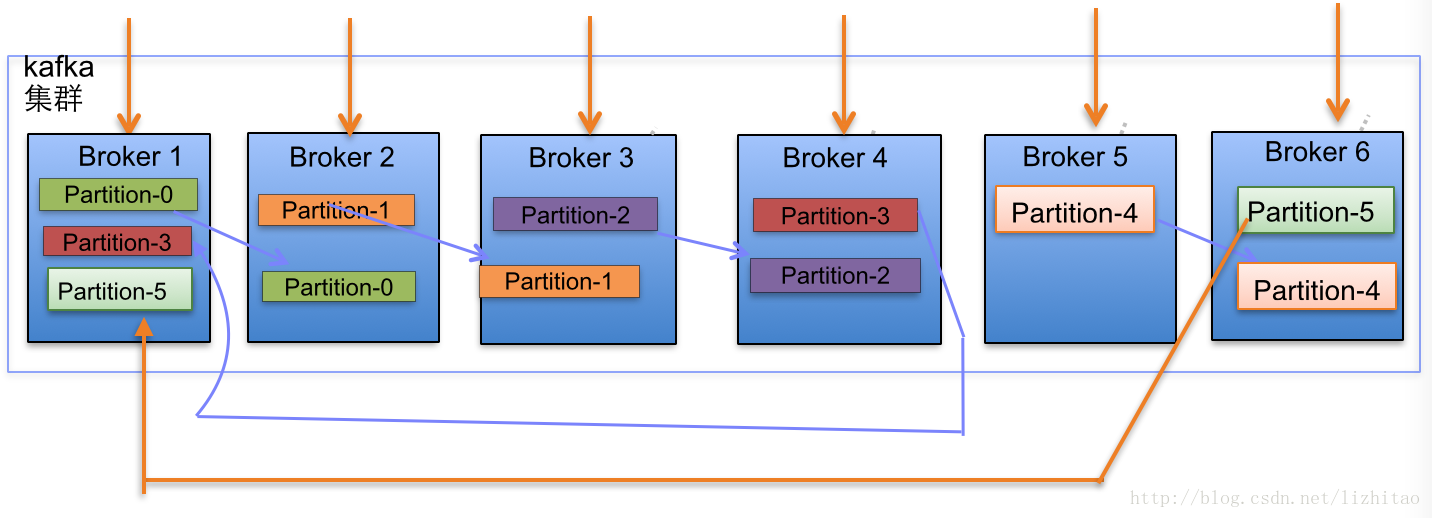
副本分配逻辑规则如下:
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
生产者客户端应用程序产生消息:
- 客户端连接对象将消息包装到请求中发送到服务端
- 服务端的入口也有一个连接对象负责接收请求,并将消息以文件的形式存储起来
- 服务端返回响应结果给生产者客户端
消费者客户端应用程序消费消息:
- 客户端连接对象将消费信息也包装到请求中发送给服务端
- 服务端从文件存储系统中取出消息
- 服务端返回响应结果给消费者客户端
- 客户端将响应结果还原成消息并开始处理消息
2. 不创建单独的cache,使用系统的page cache。发布者顺序发布,订阅者通常比发布者滞后一点点,直接使用Linux的page cache效果也比较后,同时减少了cache管理及垃圾收集的开销。
3. 维护消费关系及每个partition的消费信息。
kafka在zookeeper中存储结构
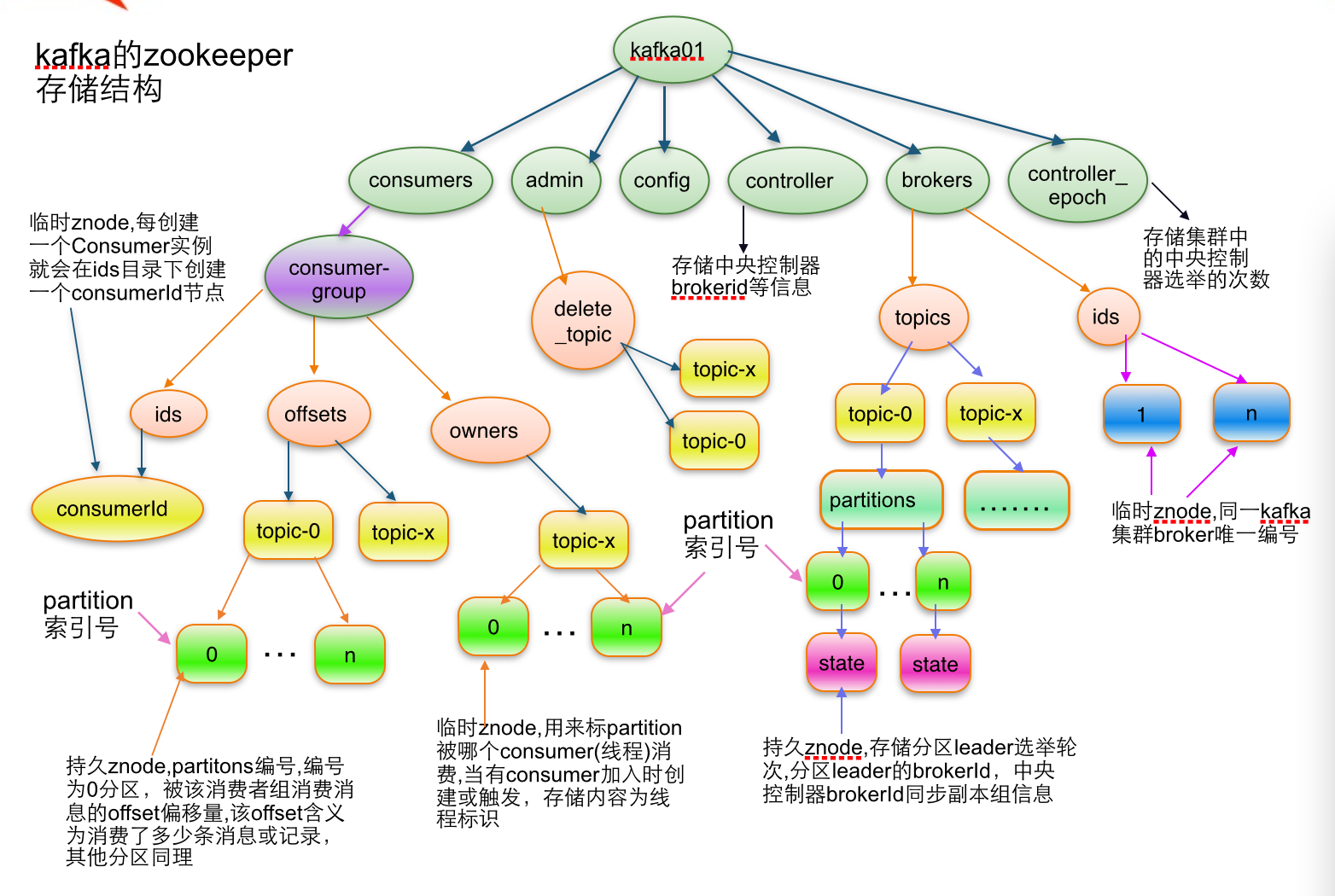
1.topic注册信息
/brokers/topics/[topic] :
存储某个topic的partitions所有分配信息
Schema:{
"version": "版本编号目前固定为数字1",
"partitions": {
"partitionId编号": [
同步副本组brokerId列表
],
"partitionId编号": [
同步副本组brokerId列表
],
.......
}
}
Example:{
"version": 1,
"partitions": {
"0": [1, 2],
"1": [2, 1],
"2": [1, 2],
}
}
说明:紫红色为patitions编号,蓝色为同步副本组brokerId列表2.partition状态信息
/brokers/topics/[topic]/partitions/[0...N] 其中[0..N]表示partition索引号
/brokers/topics/[topic]/partitions/[partitionId]/state
Schema:{
"controller_epoch": 表示kafka集群中的中央控制器选举次数,
"leader": 表示该partition选举leader的brokerId,
"version": 版本编号默认为1,
"leader_epoch": 该partition leader选举次数,
"isr": [同步副本组brokerId列表]
}
Example:{
"controller_epoch": 1,
"leader": 2,
"version": 1,
"leader_epoch": 0,
"isr": [2, 1]
}
3. Broker注册信息
/brokers/ids/[0...N]
每个broker的配置文件中都需要指定一个数字类型的id(全局不可重复),此节点为临时znode(EPHEMERAL)
Schema:{
"jmx_port": jmx端口号,
"timestamp": kafka broker初始启动时的时间戳,
"host": 主机名或ip地址,
"version": 版本编号默认为1,
"port": kafka broker的服务端端口号,由server.properties中参数port确定
}
Example:{
"jmx_port": 6061,"timestamp":"1403061899859"
"version": 1,
"host": "192.168.1.148",
"port": 9092
}4. Controller epoch:
/controller_epoch -> int (epoch)
此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller中央控制器所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1;
5. Controller注册信息:
/controller -> int (broker id of the controller) 存储center controller中央控制器所在kafka broker的信息
Schema:{
"version": 版本编号默认为1,
"brokerid": kafka集群中broker唯一编号,
"timestamp": kafka broker中央控制器变更时的时间戳
}
Example:{
"version": 1,
"brokerid": 3,
"timestamp": "1403061802981"
}
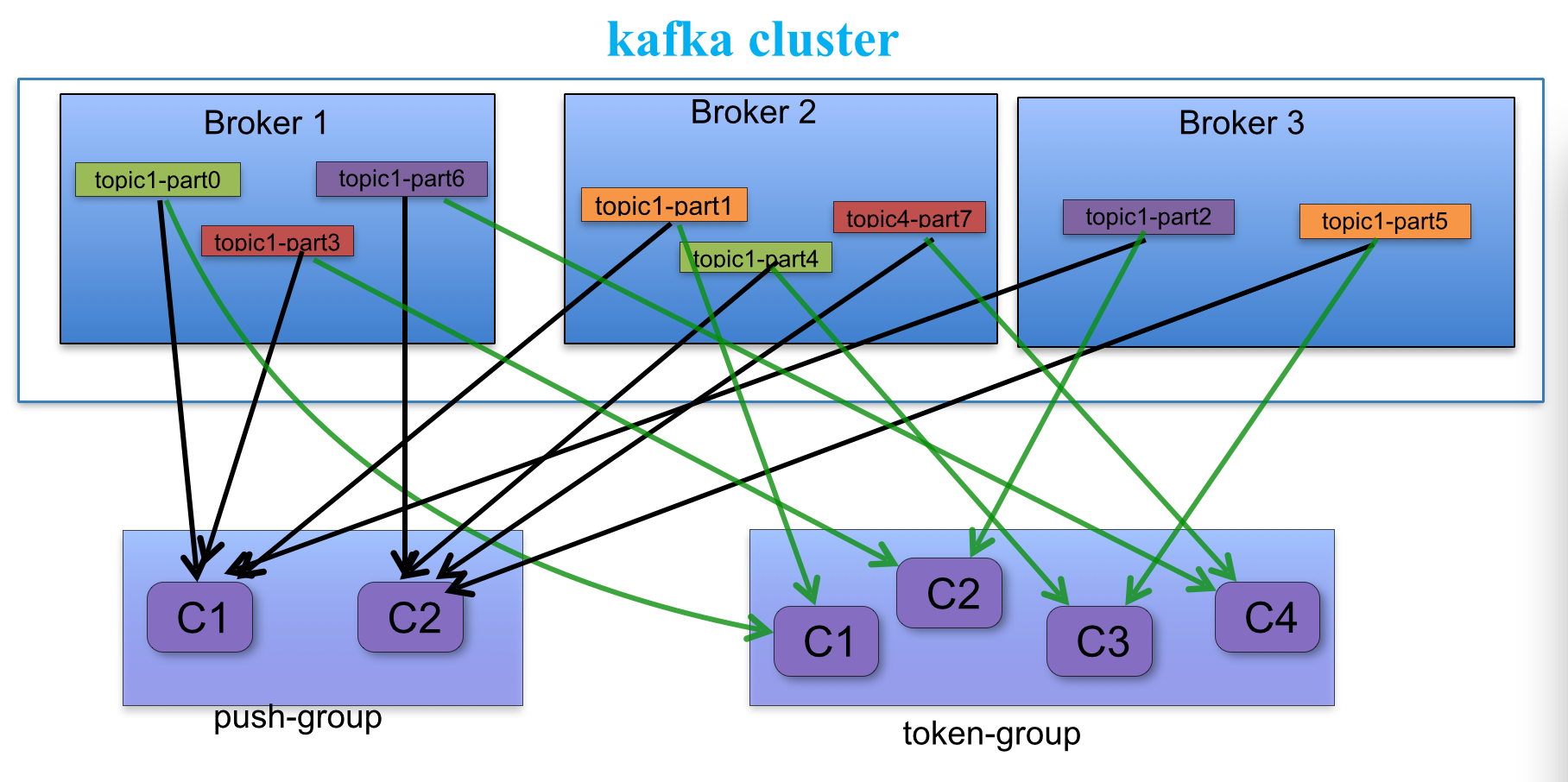
a.每个consumer客户端被创建时,会向zookeeper注册自己的信息;
b.此作用主要是为了"负载均衡".
c.同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer。
d.Consumer Group中的每个Consumer读取Topic的一个或多个Partitions,并且是唯一的Consumer;
e.一个Consumer group的多个consumer的所有线程依次有序地消费一个topic的所有partitions,如果Consumer group中所有consumer总线程大于partitions数量,则会出现空闲情况;
举例说明:
kafka集群中创建一个topic为report-log 4 partitions 索引编号为0,1,2,3
假如有目前有三个消费者node:注意-->一个consumer中一个消费线程可以消费一个或多个partition.
如果每个consumer创建一个consumer thread线程,各个node消费情况如下,node1消费索引编号为0,1分区,node2费索引编号为2,node3费索引编号为3
如果每个consumer创建2个consumer thread线程,各个node消费情况如下(是从consumer node先后启动状态来确定的),node1消费索引编号为0,1分区;node2费索引编号为2,3;node3为空闲状态
总结:
从以上可知,Consumer Group中各个consumer是根据先后启动的顺序有序消费一个topic的所有partitions的。
Consumer均衡算法
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力.
1) 假如topic1,具有如下partitions: P0,P1,P2,P3
2) 加入group中,有如下consumer: C0,C1
3) 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4) 根据(consumer.id + '-'+ thread序号)排序: C0,C1
5) 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6) 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
6. Consumer注册信息:
每个consumer都有一个唯一的ID(consumerId可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息.
/consumers/[groupId]/ids/[consumerIdString]
是一个临时的znode,此节点的值为请看consumerIdString产生规则,即表示此consumer目前所消费的topic + partitions列表.
consumerId产生规则:
StringconsumerUuid = null;
if(config.consumerId!=null && config.consumerId)
consumerUuid = consumerId;
else {
String uuid = UUID.randomUUID()
consumerUuid = "%s-%d-%s".format(
InetAddress.getLocalHost.getHostName, System.currentTimeMillis,
uuid.getMostSignificantBits().toHexString.substring(0,8)); }
String consumerIdString = config.groupId + "_" + consumerUuid;Schema:{
"version": 版本编号默认为1,
"subscription": { //订阅topic列表
"topic名称": consumer中topic消费者线程数
},
"pattern": "static",
"timestamp": "consumer启动时的时间戳"
}
Example:{
"version": 1,
"subscription": {
"open_platform_opt_push_plus1": 5
},
"pattern": "static",
"timestamp": "1411294187842"
}7. Consumer owner:
/consumers/[groupId]/owners/[topic]/[partitionId] -> consumerIdString + threadId索引编号
当consumer启动时,所触发的操作:
a) 首先进行"Consumer Id注册";
b) 然后在"Consumer id 注册"节点下注册一个watch用来监听当前group中其他consumer的"退出"和"加入";只要此znode path下节点列表变更,都会触发此group下consumer的负载均衡.(比如一个consumer失效,那么其他consumer接管partitions).
c) 在"Broker id 注册"节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance.
8. Consumer offset:
/consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset)
用来跟踪每个consumer目前所消费的partition中最大的offset
此znode为持久节点,可以看出offset跟group_id有关,以表明当消费者组(consumer group)中一个消费者失效,
重新触发balance,其他consumer可以继续消费.
9. Re-assign partitions
/admin/reassign_partitions
{
"fields": [{
"name": "version",
"type": "int",
"doc": "version id"
}, {
"name": "partitions",
"type": {
"type": "array",
"items": {
"fields": [{
"name": "topic",
"type": "string",
"doc": "topic of the partition to be reassigned"
}, {
"name": "partition",
"type": "int",
"doc": "the partition to be reassigned"
}, {
"name": "replicas",
"type": "array",
"items": "int",
"doc": "a list of replica ids"
}],
}
"doc": "an array of partitions to be reassigned to new replicas"
}
}]
}
Example: {
"version": 1,
"partitions": [{
"topic": "Foo",
"partition": 1,
"replicas": [0, 1, 3]
}]
}10. Preferred replication election
/admin/preferred_replica_election
{
"fields": [
{
"name": "version",
"type": "int",
"doc": "version id"
},
{
"name": "partitions",
"type": {
"type": "array",
"items": {
"fields": [{
"name": "topic",
"type": "string",
"doc": "topic of the partition for which preferred replica election should be triggered"
}, {
"name": "partition",
"type": "int",
"doc": "the partition for which preferred replica election should be triggered"
}],
}
"doc": "an array of partitions for which preferred replica election should be triggered"
}
}]
}
例子: {
"version": 1,
"partitions": [{
"topic": "Foo",
"partition": 1
}, {
"topic": "Bar",
"partition": 0
}]
}11. 删除topics
/admin/delete_topics
Schema: {
"fields": [{
"name": "version",
"type": "int",
"doc": "version id"
}, {
"name": "topics",
"type": {
"type": "array",
"items": "string",
"doc": "an array of topics to be deleted"
}
}]
}
例子: {
"version": 1,
"topics": ["foo", "bar"]
}Topic配置
/config/topics/[topic_name]
例子
{
"version": 1,
"config": {
"config.a": "x",
"config.b": "y",
...
}
}