python + Unittest单元测试框架(robot framework rf框架, Java+testng)
HTMLTestRunner是Unittest的扩展,可以生成HTML格式的测试报告,需要下载py文件,进行安装,将import StringIO修改为import io。
- TestCase:测试用例
- TestSuite:测试用例集合
- TestLoader:加载测试用例到集合中
- TestRuneer:执行测试用例
from selenium import webdriver
import HTMLTestRunner
import unittest,time
class BaiduIDETest(unittest.TestCase):
#测试准备工作
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30) #隐形等待,智能等待,确保内容节点完全加载
self.base_url = "https://www.baidu.com"
time.sleep(3)
#测试用例。test开头,测试用例多个的情况下,按照用例名称的ASCII码的顺序执行
def test_baidu_ide(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_id("kw").clear()#清空默认值
driver.find_element_by_id("kw").send_keys("python自动化")#模拟键盘输入
driver.find_element_by_id("su").click()#点击
time.sleep(5)
self.aeesrtEqual("python自动化_百度搜索",driver.title)#查看源码
#测试收尾工作
def tearDown(self):
self.driver.quit() #退出浏览器
#生成测试报告
if__name__=="__main__"
testsuit = unittest.TestSuite()
testsuit.addTest(BaiduIDETest("test_baidu_ide"))#将测试类中的测试用例添加到测试套件中
fp = open('./result.html','wb') #定义测试报告的存放路径
#with open('./result.html','wb') as fp
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title='自动化测试报告',description='用例执行情况')
runner.run(testsuit)#运行
fp.close()#关闭,with可以自动关闭
#断言
assertEqual(a,b) a==b
assertNotEqual a!=b
assertTrue(x) bool(x)is true
assertFalse(x)
assertIsNone(x) x is None
assertIsNotNone()
assertIn(a,b) a in b
assertNotIn(a,b)
隐形等待
显性等待
python +selenium 自动化测试 +Pyquery +Lxml
pip install selenium
pip install Pyquery
pip install Lxml
pip list
适用情况:
1、需求变动不频繁
2、项目周期足够长
3、自动化测试脚本可重复利用
from selenium import webdriver
from lxml import etree
from pyquery import PyQuery as pq
import time
driver = webdriver.Chrome()
driver.maximize_window() #最大化浏览器窗口
driver.get("https://www.toutiao.com")#网站特别之处,ajax,鼠标不断下滑,没有123,异步分页
driver.implicitly_wait(10) #隐形等待,确保异步分页内容完全加载
#time.sleep(2) #显性等待,人可以感受到的
driver.find_element_by_link_text("科技").click()
for i in range(3):
js = "var q = document.documentElement.scrollTop="+str(i*500) #控制滚动条
driver.execute_script(js)#执行js代码
# #100000滚动条最下方,0最上方
#js = "var q = document.documentElement.scrollTop=100000"#滚动条在最下方
page = driver.page_source#获取网页源码
doc = etree.HTML(str(doc))#构造xpath解析对象
#利用xpath定位元素
contents = doc.xpath('//div[@class="wcommonFeed"]/ul/li')#@class唯一定位
# /选取子节点,//选择子孙节点
for x in contents:
title = x.xpath('div/div[1]/div/div[1]/a/text()')
print(title)
#断言----测试报告HTMLTestRunner
driver.quit()
python +requests模拟http请求---接口自动化测试
pip install requests
pip list
import requests
import re.json
def get_html():
#模拟浏览器selenium伪装
user_agent = '' #F12
headers ={'User-Agent':user_agent} #浏览器信息
#requests访问
a = requests.get(url=Url,headers=headers) #构造请求
html = a.text #获取源码
print(html)
return html
#正则匹配需要的内容
def parse_one_page(html):
#主演+时间+名称
pattern = re.compile('<dd>.*?board_index.*?(\d+)</i>.*?data_src="(.*?)".*?name"><a+'.*?'>(.*?)</a>.*?star">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S) #compile编译成对象提高效率
#.*? 懒惰匹配,任意字符
#(.*?)不仅要匹配还要取出来
#re.S 匹配换行符
items = re.findall(pattern.html)
print(items) #list
for item in items:
yield{
'index':item[0]
'image':item[1]
'title':item[2]
'actor':item[3].strip()[3:] #strip()去掉空格
'time':item[4].strip()[5:]
}
#数据存储
def write_file():
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n') #对数据编码
# f.close() with 语句自动调用close方法
def main():
Url = 'https://maoyan.com'
html = get_html(Url)
for item in parse_one_page(html):
print(item)
write_file(item)
if __name__ =='__main__': #判断文件入口
main()
#字符串也可以使用切片
a = '主演:张国荣,梅艳芳,郭富城'
a[3:] 张国荣,梅艳芳,郭富城
a[4:6] 国荣
#文件操作
r只读模式
w写模式
a追加模式
+读写模式
b二进制模式
自动化常用技能之断言assert
# xpath定位
driver.find_element_by_xpath("//*[@id='kw']").send_keys("selenium")
# xpath定位/:从根节点选取
# xpath定位//:从当前节点进行选取
# xpath *:匹配任何元素节点
# xpath @:选取属性
driver.find_element_by_xpath("//*[@id='su']").click()
# 1、isdisplayed测试通过,会继续执行,否则报错
print (driver.find_element_by_xpath("//div/h3/a[text()='web Browser Automation']/../a/em[text()='Selenium']").is_displayed())
print("测试成功,结果跟预期匹配")
# 2、相等字符==判断字符完全相同
ele_string = driver.find_element_by_xpath("//div/h3/a[text()='Web Browser Automation']/../a").text
if(ele_string == u"Selenium-Web Browser Automation")
print("测试成功")
3、unittest框架的testcase类提供的
#assertEqual(a,b) a==b
#assertNotEqual a!=b
#assertTrue(x) bool(x)is true
#assertFalse(x)
#assertIsNone(x) x is None
#assertIsNotNone()
#assertIn(a,b) a in b
#assertNotIn(a,b)
4、selenium工具专门为web应用程序编写的一个验收测试工具,三种模式的断言:assert/verify/waitfor,验证和断言的区别,验证失败后不影响脚本的继续执行,断言失败后将停止脚本的执行
try:
a = driver.find_element_by_xpath("//div/h3").text
assert (a=="Selenium-Web Browser Automation")
print("测试成功")
except AssertionError:
print("测试失败")
driver.quit()
测试框架
from selenium import webdriver
import unittest,time
import HTMLTestRunner#自动测试报告
class BaiduIdeTest(unittest.TestCase):
#资源准备工作
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicutky_wait(10)
self.base_url = "https://www.baidu.com"
#测试用例
def test_baidu_ide(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_xpath("//*[@id='kw']").send_keys("selenium")
driver.find_element_by_xpath("//*[@id='su']").click()
time.sleep(2)
ele_string = driver.find_element_by_xpath("//div/h3/a[text()='Web Browser Automation']/../a").text
self.assertEqual(ele_string,"Selenium-Web Browser Automation","测试失败")
#资源清退工作
def tearDown(self):
self.driver.quit()
if __name__=="__main__":
testsuite = unittest.TestSuite()#构造测试套件
testsuite.addTest(BaiduIdeTest("test_baidu_ide"))
with open('./result.html','wb')#定义存放路径
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title='自动化测试报告',description='用例执行情况')#定义测试报告内容
runner.run(testsuite)
selenium断言
assertLocation #判断当前是在正确的页面
assertTitle #检查当前页面的title是否正确
assertValue #检查input的值,checkbox或radio,有值为‘on’,无值为‘off’
assertSelected #检查select的下拉菜单中选中是否正确
assertSelectedOptions #检查下拉菜单中的选项是否正确
assertText #检查指定元素的文本
assertTextPresent #检查在当前给用户显示的页面上是否有出现指定的文本
assertTextNotPresent #检查在当前给用户显示的页面上是否没有出现指定的文本
assertAttribute #检查当前指定元素的属性的值
assertTable #检查table里的某个cell种的值
assertEditable #检查指定的input是否可以编辑
assertNotEditable #检查指定的input是否不可以编辑
assertAlert #检查是否有产生带指定的message的alert对话框
verifyTitle #检查预期的页面标题
verifyTextPresent #验证预期的文本是否在页面上的某个位置
verifyElementPresent #验证预期的UI元素,它的html标签的定义,是否在当前网页上
verifyText #核实预期的文本和相应的html标签是否都存在与页面上
verifyTable #验证表的预期内容
waitForPageToLoad #暂停执行,直到预期的新的页面加载
waitForElementPresent #等待检验某元素的存在,为真时则执行
高效率接口测试--自动化测试

接口自动化测试提速
- 伪静态dns,压缩解析域名的时间
- 关闭Gzip
- mock复杂服务
- 缓存相同请求
- 异步(在一件事情开始之前,另一个就已经开始了)
import time
from pprint import pprint
import requests
from concurrent.futures import ThreadPoolExecutor #异步
url = "https://music.163.com"
headers={}
body = ""
def fetch(url)
pass
start = time.time()
for i in range(100):
fetch(url)
pprint(f"耗时{time.time()-start:.2f}秒")
#异步
with ThreadPoolExecutor() as pool: #异步
pool.map(fetch,[url for i in range(100)]) #重复100次
高并发bug测试
录制


#10次 for
for i in range(10): #无并发,同步(一个执行完成后,接着第二个)执行
response = requents.post("http://",headers=headers,cookies=cookies,data=data)
#函数灵活调用
def f():
response = requents.post("http://",headers=headers,cookies=cookies,data=data)
#多线程并发测试
with ThreadPoolExecutor() as pool:
pool.map(f,range(10)) #加入购物车10次,通过并发的方式
测试体系
作为测试,在执行测试活动之前,必须先弄清楚被测对象是什么,被测队形有哪些属性,特别要注意的是隐藏属性。 纸(卫生纸、餐巾纸、白纸) 水杯(纸杯、玻璃杯、陶瓷杯、保温杯等) 电梯(箱式、扶梯等)
1、通过严谨的需求分析及需求评审,做出合理的测试计划和测试方案
2、设计测试用例:
- 单一功能
- 业务流程
- UI测试用例
- 性能测试用例
- 安全测试用例
- 重点:秒杀活动,显示抢购等大型电商活动可能产生的性能问题,以及是否有对应的容灾方案。
3、多轮测试,直到满足上线条件。 迭代测试(敏捷测试)
4、测试文档归档,测试报告提交
测试思维的建立
原则:用怀疑的目光看待任何事情
善于观察,善于思考,善于总结,建立一个比较完整的知识体系
中级: 主流工具 自动化脚本编写 测试技巧 搭建环境 清楚架构
高级: 项目的部署架构 性能的评审 精通编程语言 自动化 安全测试

Restful API接口测试
1、什么是API:程序之间约定的通信方法
2、API类型:rpc-远程过程调用的架构;soap-面向服务的架构;rest-表征状态转移的架构。
3、restful API特点:符合rest风格的API;使用URL表示某一资源,使用http请求方法表示对资源的操作,使用http状态码表示操作结果。
测试工具
soap UI ,postman,python+requests
性能测试工具jmeter
jmeter3.1对持续集成来说非常稳定
badboy2.2版本
Blazemeter录制
优点:支持Chrome浏览器录制
缺点:网络问题,翻墙,对于部分数据的解析还存在问题
http代理服务器录制:
1、添加线程组aa
2、添加cookie管理器
3、添加->非测试元件->http代理服务器,对“目标控制前”设置线程组aa,(注意端口是否被占用)点击启动。
4、打开IE浏览器,Internet选项->连接->局域网设置->勾选代理服务器->地址为本地IP,端口与jmeter一致,点击确定。
5、打开测试地址进行操作,完成后,停止代理录制,关闭IE的代理。
6、线程组aa下出现很多脚本,其中jpg、png、js、css等属于静态资源,可以通过代理服务器下的request filtering下进行排除过滤。正则格式:.*\.js.*|.*\.css.*|.*\.jpg.*|.*\.png.*|.*\.gif.*|.*\.bmp.*利用|隔开。
7、手动更改脚本名称。
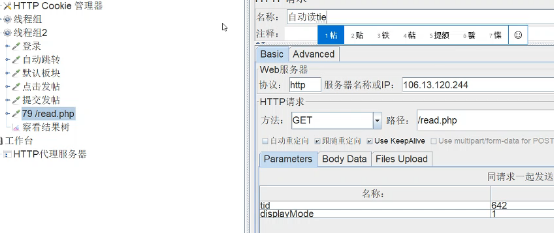
8、脚本调试。
9、参数化,添加配置元件->CSV Data Set Config。
10、关联:在需要管理的脚本后,添加后置处理器-正则表达式提取器(可以复制的多一些),将要处理的进行(.*?),在需要关联的地方(可能不止一处),将值替换为变量${verify}
#请求之间的依赖,如果请求B中所使用的某些数据,是来源于请求A的响应的数据,则说明请求B依赖于请求A。
#对于请求B中所使用的数据,表现形式很多,可能是cookie、sessionID、token等待。
关联的数据一定是来自于服务器的响应
关联的数据一定要在后续的请求中被用到
关联的数据是动态变化的
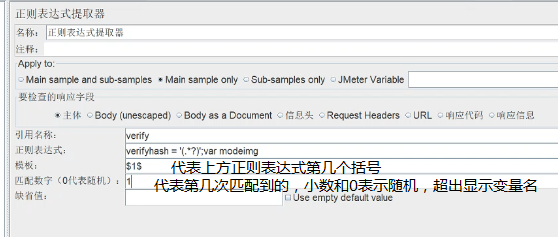

多线程时,可以对匹配数字进行参数化,${__threadNum}线程编号
11、多线程,关闭查看结果树,占用系统资源,使用聚合报告。
12、移动设备:要求和启动jmeter的代理的机器处在同一个局域网,直接通过修改手机wlan选项来实现。(手机设置一个代理,设置成jmeter机器的IP地址)
13、录制完脚本,还原所有设置。
录制优缺点:
优点:录制可控
缺点:过滤器,否则可读性差,仅仅可以录制http、https的协议,其他协议不支持。
万能工具jmeter的使用技巧
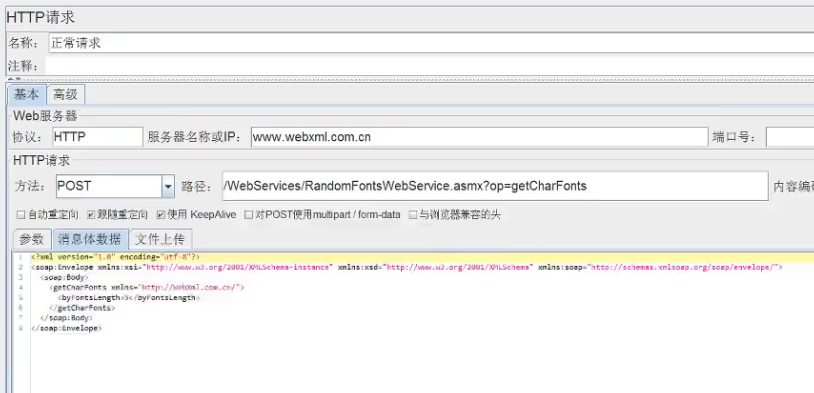
接口测试----消息体数据
性能测试
选项--jmeter plugins manager(jar包需要下载后放入lib/ext路径下,退出重启jmeter)选择插件进行场景
选项--jmeter plugins manager,选择selenium/webdriver support(需要下载jar包)。
jmeter做UI自动化测试,面向过程的编程--jmeter3.3版本,JavaScript
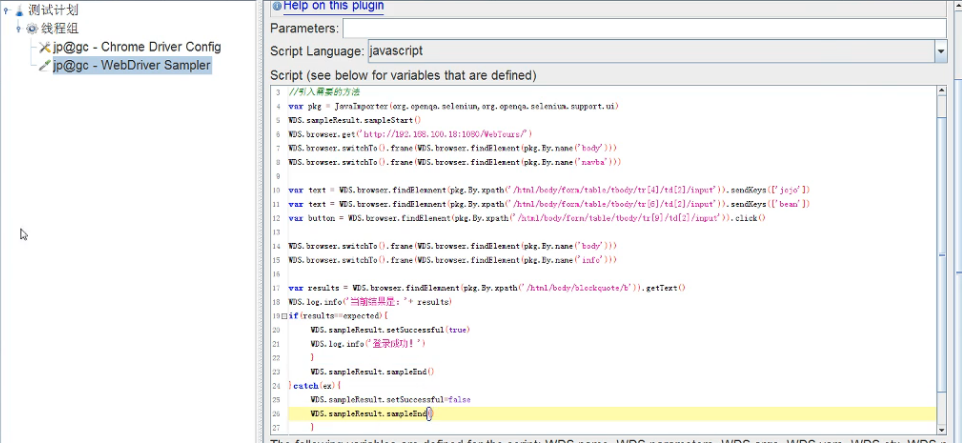
jmeter进阶
jmeter非GUI运行
图形化界面消耗更多资源,如CPU和内存,容易使压力机达到瓶颈,从而影响测试结果
图形化界面不支持大型的负载测试和性能测试,并发较大时jmeter会崩溃
只用命令行方式才可以实现持续集成,做成自动化测试。
jmeter -n -t test.jmx -r 192.168.1.1 -l testresult.jtl -H 192.168.20.2 -P 8080
-n #非图形化模式
-t #要执行的jmeter脚本路径
-l #执行完成后的结果记录路径
-r #负载,需在properties文件remote进行修改。
-H #代理主机->设置jmeter使用的代理主机
-P #代理端口->设置jmeter使用的代理主机的端口号
jmeter自动化平台的搭建j meter + ant +jenkins
JDK + Ant +Tomcat + Jenkins + Jmeter
vim /etc/profile
#环境变量
JAVA_HOME=/
JRE_HOME=
ANT_HOME=
JMETER_HOME=
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$ANT_HOME/bin:$JMETER_HOME/bin
CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME ANT_HOME JMETER_HOME PATH CLASSPATH
source /etc/profile
#检查是否成功
jmeter -v
ant -version
jmeter 与ant 集成
1、将ant—jmeter-1.1.1.jar从jmeter/extras中复制到ant/lib目录下
2、在jmeter中新建一个testcases文件夹,里面再创建一个report文件夹(非必须,用来存放测试jmx,和生成的报告)
3、准备一个build.xml文件,并上传到服务器(用来给ant去调用,执行自动化操作)
跳转到testcase目录下(build.xml+XX.jmx+report文件夹),执行ant命令successful,即可执行生成报告。
jenkins的安装配置
1、虚拟机关闭防火墙 systemctl stop firewalld,正式环境开放端口即可。
禁止开机启动 systemctl disable firewalld
查看防火墙状态 systemctl status firewalld
将Jenkins.war包放到tomcat/webapps目录下。
进入tomcat/bin目录启动 nohup ./catalina.sh start
初次启动,输入安全码,使用推荐的插件。
2、配置全局变量
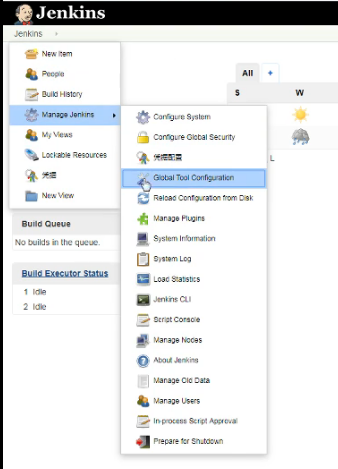
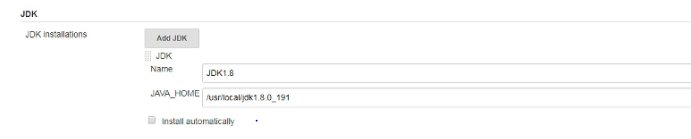
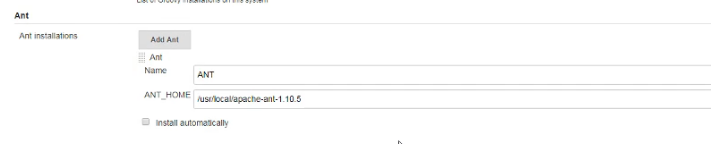
3、插件管理安装
Grooyy
Grooyy Postbuild
HTML Publisher plugin
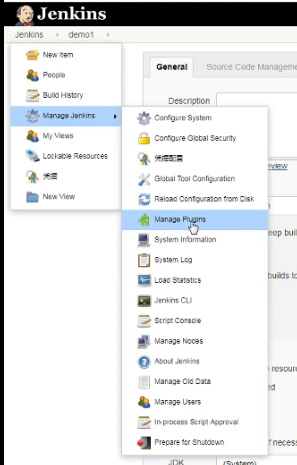
首页
接口测试的配置
1-1、New Item,新建一个Freestyle project的项目,输入项目名称,点击ok,进入配置页面。
1-2、Build-->Invoke Ant,选择,点击高级,Build File,输入testcase下build.xml的路径地址。
压力测试的配置
2-1、New Item,新建一个Freestyle project的项目,输入项目名称,点击ok,进入配置页面。
2-2、Build-->execute shell。
rm -rf /usr/local/apache-jmeter3.3/testcase/testResult
rm -rf /usr/local/apache-jmeter3.3/testcase/*.jtl
rm -rf /usr/local/apache-jmeter3.3/testcase/*.log
jmeter -n -t /url/local/apache-jmeter3.3/testcase/fatoc.jmx -lfatie.jtl -e -o /usr/local/apache-jmeter3.3/testcase/testResult
3、post-build actions 设置都一样
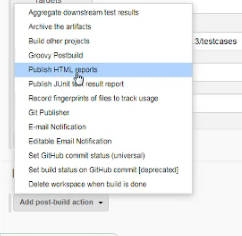
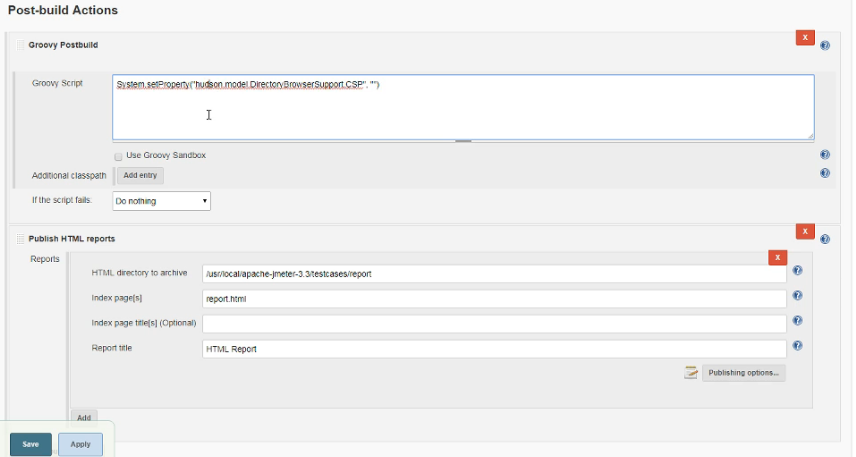
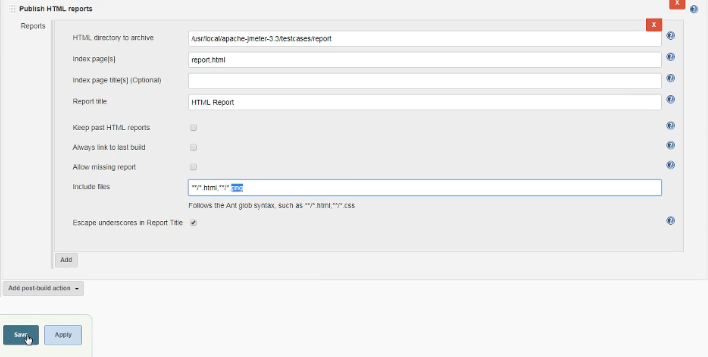
4、所有设置完成即可进行构建 Build Now。
5、还可以配置,发送邮件(通过插件)。
小技巧之利用cookies绕过网站登录
验证码的处理方式
验证码技术可以有效防止用户对网络的滥用,比如防止某个黑客对一个特定的注册用户用特定程序暴力破解方式进行不断地密码尝试,验证码有如下几种:计算验证码、滑块验证码、识图验证码、语言验证码、电话验证码。
测试如何处理验证码:
1、可以让开发帮你把验证码去掉
2、或开发给你开条后路,万能的通关密码
3、识别技术: opencv图像处理,pil图像处理,ocr文字识别,tesseract-ocr是谷歌ocr识别引擎。
4、记录cookies,跳过登录。
如何获取cookies
无状态--无登录状态,A与B之间的每一次交易完全没有关联。思考:如何喝上一次的饮品呢?
有状态:会员卡记录消费信息。
from selenium import webdriver
import time
driver = webdriver.Chrome() #测试重新打开一个浏览器窗口
driver.get("https://www.baidu.com") #
cookie_1 = {"name":"","value":""} #不止一个cookie,网站系统决定
cookie_2 = {"name":"","value":""} #直接F12复制即可
time.sleep(5) #爬虫时速度过快容易被封。
driver.add_cookie(cookie_1)
driver.add_cookie(cookie_2)
driver.get("https://www.baidu.com")
# cookies
数据保存在客户端,保存数据有限,最大不能超过3k
cookie不允许跨域访问
#session
数据保存在服务端,占用服务器性能
#token
token安全性比session好
token 用户认证,授权app
token支持跨越访问(不同的域),传输的用户认证信息通过http头传输
token的状态存储在客户端
LoadRunner复杂脚本的开发
Java Vuser简介及适用范围
Java Vuser,自定义虚拟用户脚本,可以使用标准的Java语言,这种虚拟用户不可以录制,仅仅能采用纯手工编写,其使用范围和C Vuser一样广泛。
RMI Java Vuser(远程方法调用)适用于测试RMI Java应用程序或小程序,选择RMI-Java用户进行录制后,VuGen可以创建对应的Java脚本,完成录制后,可以使用JDK或者自定义类,通过标准的Java代码来增强或者修改脚本,还可以通过特定于LoadRunner的Java方法来增强该脚本。
Corba Java Vuser该类型的虚拟用户主要用来测试试用Java编写,并使用Corba的应用程序或小程序的性能,用户可以运行VuGen录制的脚本,然后试用标准的Java库函数以及LoadRunner特有的Java方法来增强该脚本。
EJB Vuser该虚拟用户专门用于测试Enterprise Java beans对象,采用EJB协议,VuGen会自动创建脚本以测试EJB功能,无需录制或编程。
C语言脚本的局限性
开发成本高,测试人员的开发基础不太好
JavaVuser的适用范围
不太适合录制的业务功能点的性能测试:例如网页上http文件的下载过程,视频播放等
基于Java语言开发的应用系统的性能测试。


Java Vuser环境配置

Java Vuser项目实战


IO流
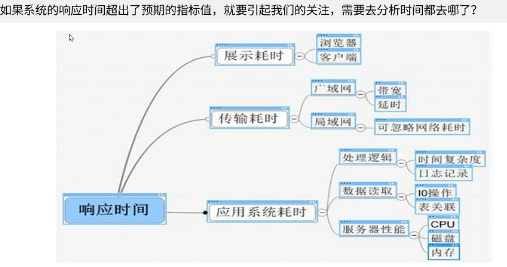
性能测试过程中的各种时间
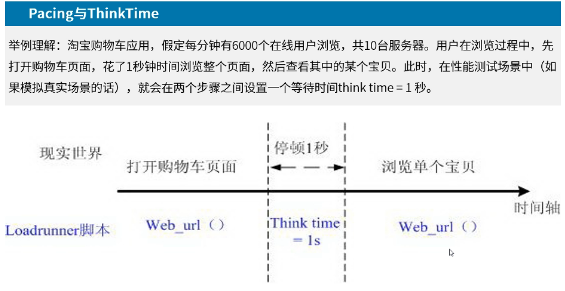
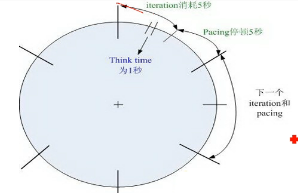
响应时间是衡量系统性能好坏的一个重要维度
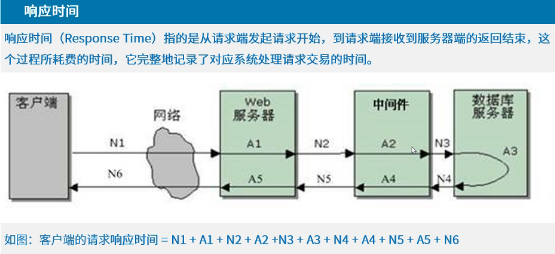
258与135原则

思考时间是用来模拟用户操作的等待(停顿)时间
控制测试代码的业务执行速度,完美的执行出预计的场景;模拟实际用户执行的等待时间。
pacing 步长