

1. 前提
每次鼓起勇气说要掌握正则表达式,但是每次都是学不完就放弃了,而直到做项目时有一些奇奇怪怪的校验规则需要用到正则时,又是一通查找。干脆,找个周末,从头到尾梳理一遍,好好总结。这一篇文章主要还是以入门学习为主,把大概的知识点的囊括一遍,后续再深入
2. 创建正则表达式
有两种方法创建正则表达式:
// 使用一个正则表达式字面量,其由包含在斜杠之间的模式组成
var re = /ab+c/;
// 调用RegExp对象的构造函数
var re = new RegExp("ab+c");
3. 正则表达式的一些方法
我们后面再讲正则的字符,先把正则常用的几个方法过一遍,免得待会举例子会觉得懵逼,所以暂时知道大概怎么用就行
| 方法 | 描述 |
|---|---|
| exec | 一个在字符串中执行查找匹配的RegExp方法,返回一个数组(未匹配到则返回 null) |
| test | 一个在字符串中测试是否匹配的RegExp方法,返回 true 或 false |
| match | 一个在字符串中执行查找匹配的String方法,返回一个数组,在未匹配到时会返回 null |
| search | 一个在字符串中测试匹配的String方法,返回匹配到的位置索引,或者在失败时返回-1 |
| replace | 一个在字符串中执行查找匹配的String方法,并且使用替换字符串替换掉匹配到的子字符串 |
| split | 一个使用正则表达式或者一个固定字符串分隔一个字符串,并将分隔后的子字符串存储到数组中的 String 方法 |
以上只是列举常用的方法并简单描述,更详细的在这
----------------------- 以下才是正文-----------------------
4. 正则表达式规则
我们知道,正则表达式是通过各种各样的字符进行匹配,简单分类如下:
4.1 普通字符
字母、数字、汉字、下划线、以及没有特殊定义的标点符号,都是"普通字符",表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符
/c/ 匹配 abc123 时,匹配到的就是 c
/abc/ 匹配 abc123 时,匹配到的就是abc
4.2 简单的转义字符
一些不便书写的字符,采用在前面加 "" 的方法
| 表达式 | 可匹配 |
|---|---|
| \r, \n | 代表回车和换行符 |
| \t | 制表符 |
| \\ | 代表 "\" 本身 |
| \^ | 匹配^ |
| $ | 匹配$ |
| \. | 匹配小数点(.) |
这些转义字符的匹配方法与 "普通字符" 是类似的。也是匹配与之相同的一个字符
4.3 能够与 '多种字符' 匹配的表达式
大写字母表示相反的意义
| 表达式 | 可匹配 |
|---|---|
| \d | 任意一个数字,0~9 中的任意一个 |
| \D | 匹配所有的非数字字符 |
| \w | 任意一个字母或数字或下划线,也就是 A~Z,a~z,0~9,_ 中任意一个 |
| \W | 匹配所有的字母、数字、下划线以外的字符 |
| \s | 包括空格、制表符、换页符等空白字符的其中任意一个 |
| \S | 匹配所有非空白字符 |
| . | 小数点可以匹配除了换行符(\n)以外的任意一个字符 |
虽然可以匹配其中任意字符,但是只能是一个,不是多个
/\d\d/ 匹配 'abc123', 匹配内容是 12
/\d\d/ 匹配 'ab12c133t67s', 匹配内容是 12,13,67
/a.\d/ 匹配 'aaa1000', 匹配内容是 aa1 ,即字母a+任意字符+数字三个连续字符
4.4 自定义能够匹配 '多种字符' 的表达式
- 使用方括号 [ ] 包含一系列字符,能够匹配其中任意一个字符
- 用 [^ ] 包含一系列字符,则能够匹配其中字符之外的任意一个字符
- 同样的道理,虽然可以匹配其中任意一个,但是只能是一个,不是多个
- [] 括号中的特殊符号不需要转义,就表示其本身
| 表达式 | 可匹配 |
|---|---|
| [ab5@] | 匹配 "a" 或 "b" 或 "5" 或 "@" |
| [^abc] | 匹配 "a","b","c" 之外的任意一个字符 |
| [f-k] | 匹配 "f"~"k" 之间的任意一个字母 |
| [^A-F0-3] | 匹配 "A"~"F","0"~"3" 之外的任意一个字符 |
/[abc][bcd]/ 匹配 abcwefcl, 结果是bc (即匹配连续的两个字符ab,ac,ad,bb,bc,bd,cb,cc,cd)
4.5 修饰匹配次数的特殊符号
如果使用表达式再加上修饰匹配次数的特殊符号,那么不用重复书写表达式就可以重复匹配
使用方法是:"次数修饰"放在"被修饰的表达式"后边。比如:"[bcd][bcd]" 可以写成 "[bcd]{2}"
| 表达式 | 可匹配 |
|---|---|
| {n} | 表达式重复n次 |
| {m,n} | 表达式至少重复m次,最多重复n次 |
| {m,} | 表达式至少重复m次 |
| ? | 匹配表达式0次或者1次,相当于 {0,1} |
| + | 表达式至少出现1次,相当于 {1,} |
| * | 表达式不出现或出现任意次,相当于 {0,} |
/\d+\.?\d*/ 匹配 'afv234oa agva 1243.34,awre2.4sd,3.3422'字符串里所有数字(即小数点出现0次或一次,小数点左边数字出现一次或多次,小数点右边数字出现零次或多次)
4.6 其他一些代表抽象意义的特殊符号
| 表达式 | 可匹配 |
|---|---|
| ^ | 与字符串开始的地方匹配,不匹配任何字符 |
| $ | 与字符串结束的地方匹配,不匹配任何字符 |
| \b | 匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符 |
| | | 左右两边表达式之间 "或" 关系,匹配左边或者右边 |
| () | (1). 在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰(2). 取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到 |
注: ^在[]里表示非..,除此之外才表示开头
表达式 /\bend\b/ 在匹配 "weekend,endfor,end" 时,匹配到的内容是:"end",即最后一个
/Tom|Jack/ 匹配 "I'm Tom, he is Jack" 时,匹配结果第一个是 'Tom',第二个是'Jack'
¥(\d+\.?\d*) 匹配 '$10.9,¥20.5'时,匹配结果是 '¥20.5'
4.7 捕获组
表达式在匹配时,表达式引擎会将小括号 "( )" 包含的表达式所匹配到的字符串记录下来。在获取匹配结果的时候,小括号包含的表达式所匹配到的字符串可以单独获取
举个例子:
111-222-1234
可用 \d{3}-\d{3}-\d{4}来匹配
若给表达式加上括号,如\d{3}-(\d{3})-(\d{4})(结果还是同上),则
222 为 Group1
1234 为 Group2
通过使用$来进行选择分组
// 一组姓名,姓和名互换位置
shiffina, Daniel
reg: (\w+),\s(\w+)
// 捕获到的分组: shiffina 为group1,Daniel为group2
// 用$1,$2分别获取shiffina 和 Daniel
再通过replace方法对调: $2 $1
4.8 反向引用
通过括号捕获的分组还能使用\来进行对正则表达式本身进行引用,即反向引用
小括号包含的表达式所匹配到的字符串不仅是在匹配结束后才可以使用,在匹配过程中也可以使用。表达式后边的部分,可以引用前面 "括号内的子匹配已经匹配到的字符串"。引用方法是 \ 加上一个数字。\1 引用第1对括号内匹配到的字符串,\2 引用第2对括号内匹配到的字符串
例子:
This is is a a dog , I think think this is is really
a a good good dog. Dont you you thinks so so ?
reg: /(\w+)\s\1/g
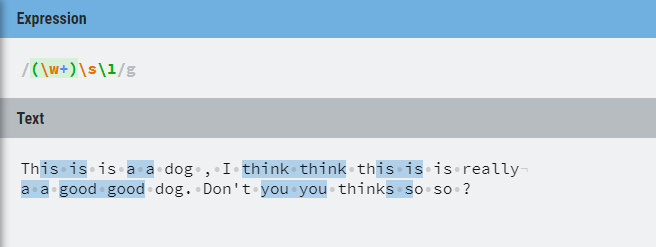
(\w+)匹配到字母一个或多个,\s匹配空格,\1相当于(\w+),只是这里需要跟前面匹配到的内容相同,如图所示
例子2:
aa bbbb abcdefg ccccc 111121111 999999999
reg: /(\w)\1{4,}/g
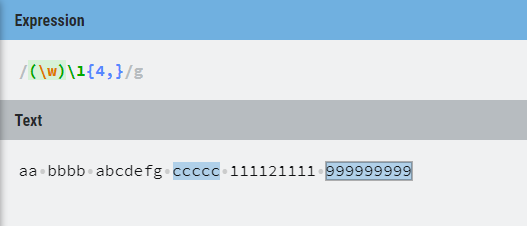
(\w)匹配一个字母,\1匹配跟(\w)一样的内容,后面的{4,}表示\1最少匹配四次,所以aa不符合,bbbb只能匹配三次\1也不符合,后面同理
4.9 贪婪与非贪婪
贪婪模式
在使用修饰匹配次数的特殊符号时,有几种表示方法可以使同一个表达式能够匹配不同的次数,比如:"{m,n}", "{m,}", "?", "*", "+",具体匹配的次数随被匹配的字符串而定。这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配
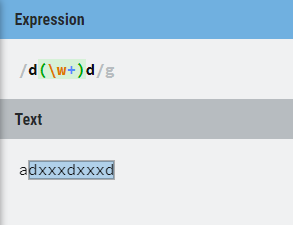
同理,带 "*" 和 "{m,n}" 的表达式都是尽可能地多匹配,带 "?" 的表达式在可匹配可不匹配的时候,也是尽可能的 "要匹配"。这 种匹配原则就叫作 "贪婪" 模式
非贪婪模式
在修饰匹配次数的特殊符号后再加上一个 "?" 号,则可以使匹配次数不定的表达式尽可能少的匹配
例子1:
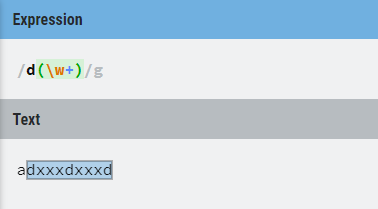

例子2:与上面/d(\w+)d/g相比,此处只匹配到第一个d就停止了

