

1.浏览器输入url到页面展现经历了什么?
-
在浏览器输入url之后,点击提交按钮时,浏览器背后的机制做了什么,以及其中有什么优化点?
-
为了大概理解这个问题,看了一些网上的博客,推荐两个写的比较清楚的:
1.导航到URL时会发生什么:主要介绍浏览器在接受请求之后发生的事件序列 http://igoro.com/archive/what-really-happens-when-you-navigate-to-a-url/ 2.浏览器的工作原理:主要介绍浏览器的渲染,以及其中优化点。 https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/ 注:仅供了解
2.主要步骤
2.1 浏览器中输入URL
以输入facebook.com为例。
2.2 浏览器查找域名的IP地址:DNS
DNS在域名解析的时候有两种方式: 递归查询和迭代查询
DNS递归查询查找过程:
- 浏览器缓存:浏览器缓存DNS记录一段时间,有过期时间,time to live;
- 操作系统缓存:如果浏览器缓存不包含所需的记录,则浏览器进行系统调用操作系统缓存,本地硬盘的hosts文件。操作系统有自己的缓存。
- 路由器缓存:如果操作系统中无缓存,请求继续到路由器,路由器一般有自己的DNS缓存。
- ISP DNS缓存(本地名称服务器缓存):检查的下一个位置是缓存ISP的DNS服务器。
- 递归搜索:ISP的DNS服务器开始递归搜索,从根名称服务器,通过.com顶级域名服务器,到Facebook的名称服务器。通常,DNS服务器将在缓存中具有.com名称服务器的名称,因此不需要命中根名称服务器。
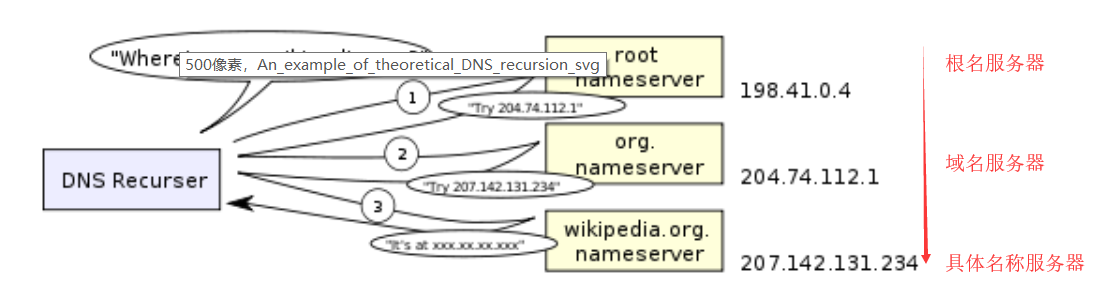
- 循环DNS:DNS查找返回多个IP地址。例:facebook.com实际上映射到四个IP地址。
- 负载均衡:侦听特定IP地址并将请求转发到其他服务器的硬件。主要站点通常使用昂贵的高性能负载平衡器。
- 地理DNS:通过将域名映射到不同的IP地址来提高可扩展性,具体取决于客户端的地理位置。这非常适合托管静态内容,以便不同的服务器不必更新共享状态。
- Anycast:是一种路由技术,其中单个IP地址映射到多个物理服务器。不幸的是,任播不适合TCP,在这种情况下很少使用。
大多数DNS服务器本身使用任播来实现DNS查找的高可用性和低延迟。
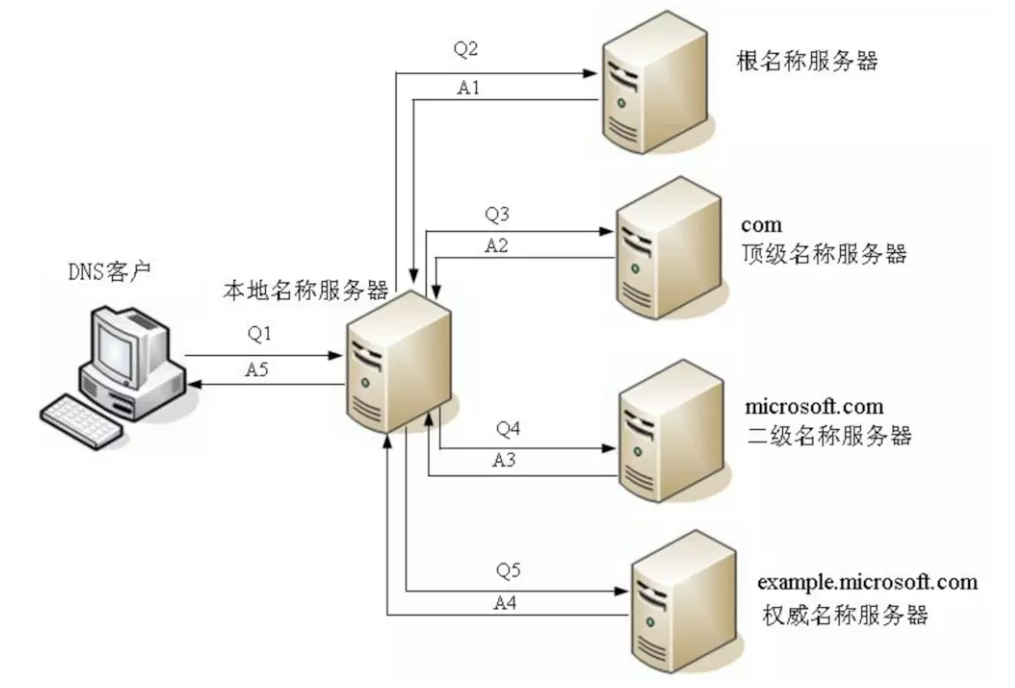
DNS迭代查询过程:
以DNS客户端自己为中心
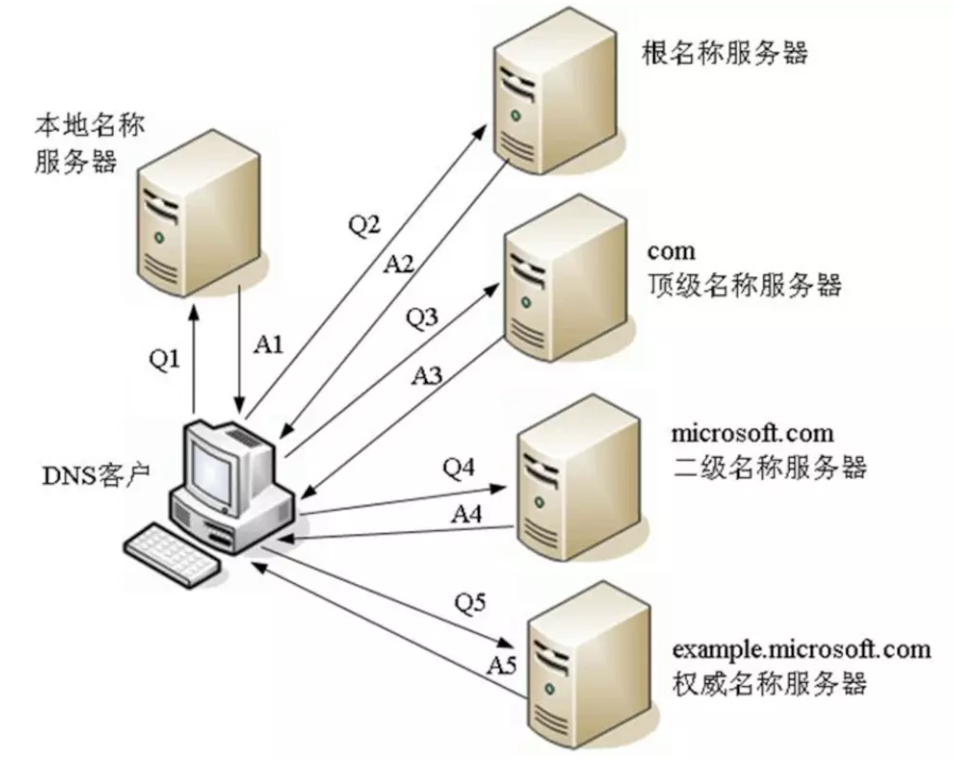
DNS递归查询和迭代查询的区别?
- 递归查询是以本地名称服务器为中心的,是DNS客户端和服务器之间的查询活动,递归查询的过程中“查询的递交者” 一直在更替,其结果是直接告诉DNS客户端需要查询的网站目标IP地址。
- 迭代查询则是DNS客户端自己为中心的,是各个服务器和服务器之间的查询活动,迭代查询的过程中“查询的递交者”一直没变化,其结果是间接告诉DNS客户端另一个DNS服务器的地址。
2.3 浏览器向服务器发送http请求
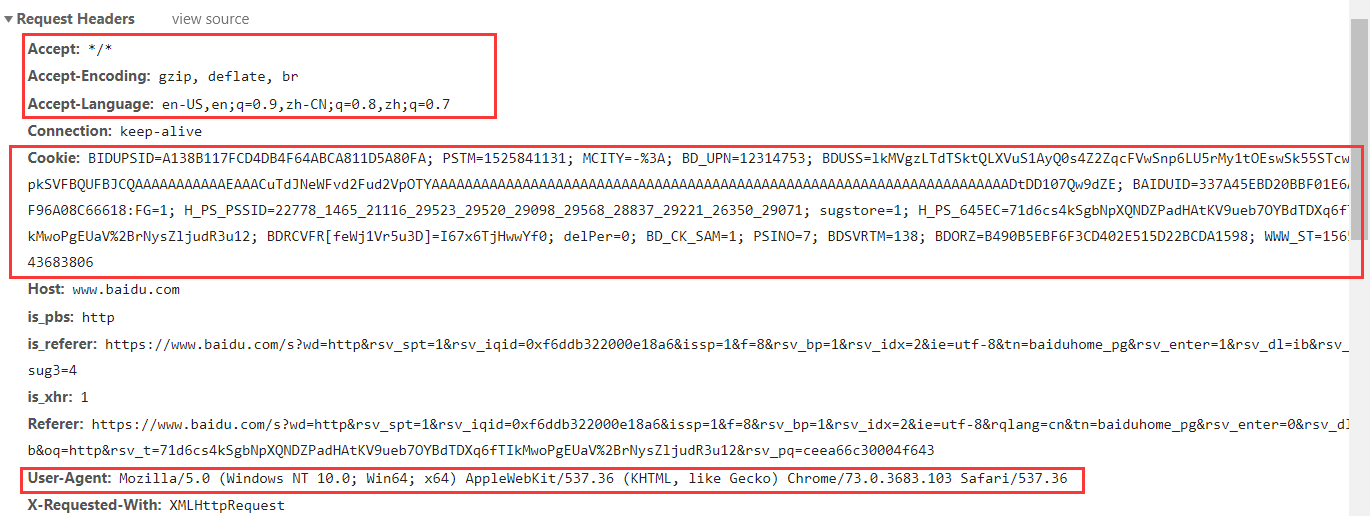
浏览器标识自己user-agent;
接受哪些类型的响应accept和accept-encoding;
浏览器为此域提供的cookie:键值对,用于跟踪不同页面请求之间的网站状态;cookie主要存储登录用户的名称,服务器分配给用户的密码,用户的一些设置等;cookie存储在客户端的文本文件中,并发送到每个请求的服务器。
2.4 传输数据过程
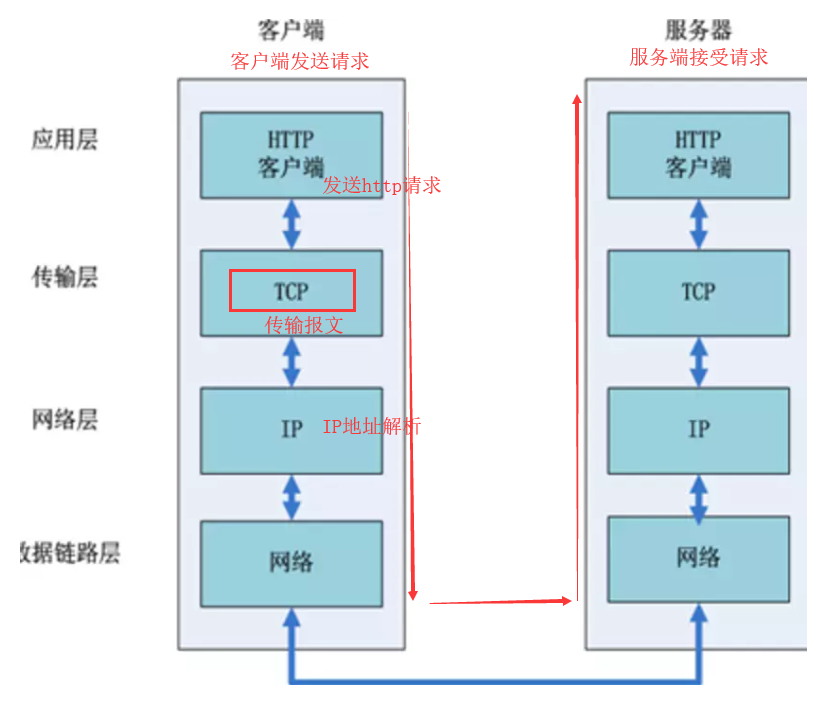
传输层:
- 应用层的http请求准备好之后,浏览器会在传输层发起一条到达服务器的tcp连接;
- 传输层的TCP协议为传输报文提供了可靠的字节流服务;
- 传输层将大块的数据分割成以报文段为单位的数据包进行管理;
- TCP协议通过三次握手的方法保证传输的安全可靠;
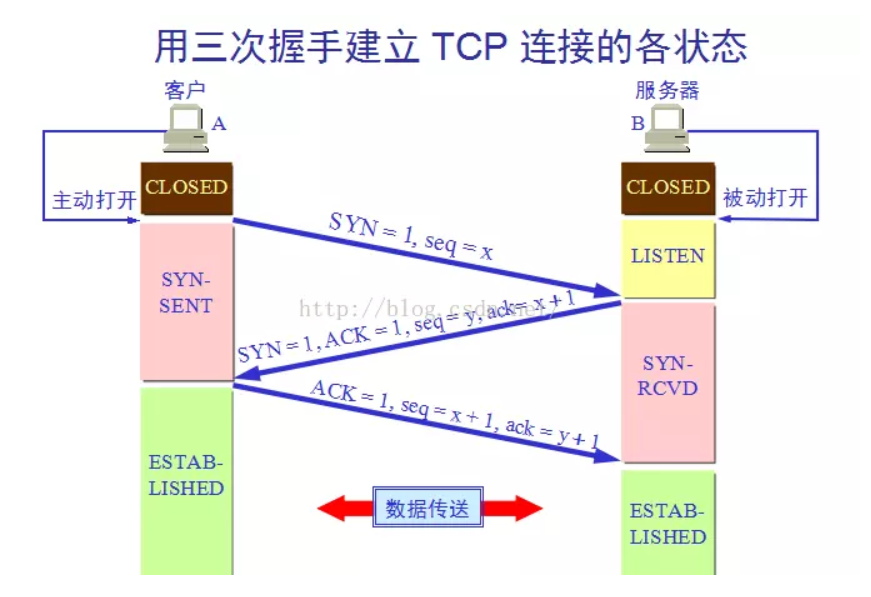
这里需要谈一下 TCP 的 Head-of-line blocking 问题:假设客户端的发送了 3 个 TCP片段(segments),编号分别是 1、2、3。
如果编号为 1 的包传输时丢了,即便编号 2 和 3 已经到达也只能等待,因为 TCP 协议需要保证顺序,这个问题在 HTTP pipelining 下更严重。
因为 HTTP pipelining 可以让多个 HTTP 请求通过一个 TCP发送。
比如发送两张图片,可能第二张图片的数据已经全收到了,但还得等第一张图片的数据传到。
为了解决 TCP 协议的性能问题,Chrome 团队提出了 QUIC 协议,它是基于 UDP 实现的可靠传输。
比起 TCP,它能减少很多来回(round trip)时间,还有前向纠错码(Forward Error Correction)等功能。
目前 Google Plus、 Gmail、Google Search、blogspot、Youtube 等几乎大部分 Google 产品都在使用 QUIC,可以通过chrome://net-internals/#spdy 页面来发现。
另外,浏览器对同一个域名有连接数限制,大部分是6,但并非将这个连接数改大后就会提升性能,Chrome 团队有做过实验,发现从 6 改成 10后性能反而下降了。
造成这个现象的因素有很多,如建立连接的开销、拥塞控制等问题,而像 SPDY、HTTP 2.0 协议尽管只使用一个 TCP 连接来传输数据,但性能反而更好,而且还能实现请求优先级。
网络层:IP协议的作用是把TCP分割好的各种数据报封装到IP包里,传送到接收方。
而要保证确实能传到接收方还需要接收方的MAC地址,也就是物理地址才可以。
IP地址和MAC地址是一一对应的关系,一个网络设备的IP地址可以更换,但是MAC地址一般是固定不变的。ARP协议可以将IP地址解析成对应的MAC地址。当通信的双方不在同一个局域网时,需要多次中转才能到达最终的目标,在中转的过程中需要通过下一个中转站的MAC地址来搜索下一个中转目标。
功能: “路由器”
数据链路层:找到对方的mac地址之后,已经封装好的IP包再被封装到数据链路层的数据帧结构中,把数据发送到数据链路层传输,再通过物理层的比特流发送;
功能: “交换机”;
物理层:比特流;
功能:“光纤接口”等;
此时,客户端发送请求的阶段结束。
2.5 服务器接收数据
数据链路层接受,传输层通过TCP协议将分段的数据包重新组成到原来的HTTP请求;
接下来的渲染部分:
- 服务器处理并响应请求
- 浏览器渲染
- 浏览器发送对HTML中嵌入的对象请求
- 浏览器发送进一步异步(AJAX)请求
3.优化点
主要体现在DNS缓存部分和渲染部分
DNS 查询的过程经历了很多的步骤,如果每次都如此,是不是会耗费太多的时间、资源。所以我们应该尽早的返回真实的 IP 地址,减少查询过程,也就是 DNS 缓存。
浏览器获取到 IP地址后,一般都会加到浏览器的缓存中,本地的 DNS 缓存服务器,也可以去记录。另外,每天几亿网名的访问需求,一秒钟几千万的请求域名服务器如何满足?就是 DNS 负载均衡。
通常我们的网站应用各种云服务,或者各种服务商提供类似的服务,由他们去帮我们处理这些问题。DNS 系统根据每台机器的负载量,地理位置的限制
(长距离的传输效率)等等,去提供高效快速的 DNS 解析服务。
4.总结
1.理解了浏览器发送http请求,到服务器接收到请求,浏览器内部的工作机制;
2.对于计网课本中的tcp/ip网络协议有了应用层面的理解:分层的意义在于分工合作;
-
数据链路层通过 CSMA/CD 协议保证了相邻两台主机之间的数据报文传递;
-
网络层的 IP 数据包通过不同子网之间的路由器的路由算法和路由转发,保证了互联网上两台遥远主机之间的点对点的通讯,不过这种传输是不可靠,于是可靠性就由传输层的 TCP 协议来保证;
-
TCP 通过慢开始,乘法减小等手段来进行流量控制和拥塞避免,同时提供了两台遥远主机上进程到进程的通信;
-
最终保证了 HTTP 的请求头能够被远方的服务器上正在监听的 HTTP 服务器进程收到;
-
终于,数据包在跳与跳之间被拆了又封装,在子网与子网之间被转发了又转发;最后进入了服务器的操作系统的缓冲区;
-
服务器的操作系统由此给正在被阻塞住的 accept 函数一个返回,将他唤醒。 3.三次握手的使用场景更清晰;
最近为了面试,重新复习了计网的网络模型和三次握手协议,但是看完之后,对于网络模型的和握手协议的应用场景很模糊。因为理解不深,所以很容易忘记,碰巧一个师兄问了我浏览器发送请求到接受请求的前后端的过程,才去做了了解,希望这个梳理能为同样对计算机网络不熟悉的你带来帮助。
