

为了更好的理解公司内部的分布式搜索系统设计原理,读了一遍大名鼎鼎的分布式存储系统论文"The Google File System"。这里主要记录自己对这篇文章的理解(翻译)。
背景
The Google File System(GFS)是google为自己的内部应用开发的一个分布式文件系统,虽然这篇文章是2003年发布已经过去了16年,但是还是非常值得我这样的分布式新手学习的。
设计假设
因为是一个google自用的分布式文件系统,因此系统在设计之初就是尽量考虑google内部的需求而非一个通用的文件系统,在设计上会有一些特殊的地方,并没有完全支持POSIX风格的接口。下面介绍一下其设计理念:
- 系统由众多的普通机器组成: 这是为了方便横向扩展,增加系统的负载只需要通过简单的增加机器即可。但是随着集群的增加,机器故障,网络故障的可能性也逐渐增加,这使得系统在设计时认为机器是不可靠的,系统中的机器随时可能出错,因此容错是非常重要的一个设计目标;
- 写入系统的文件多数为大文件: 这一点是基于google内部的需求考量的,比如爬虫存储,机器学习数据存储,日志存储等。这一假设也很重要,因为这一点决定了系统可以将文件分为更大的存储块,而不是常见的文件系统的4KB的块大小,后面会讲到这样做的好处;
- 文件的写入操作多为尾插: 这一假设也是基于google的内部需求,因为google内部任务很少有随机写入,这一点可以很好的帮助简化系统,因为不需要为随机写入进行独特的优化;
- 同一个文件可能会有大量的并发写入: 这一点需求需要保证系统在设计保证并发写入不会出错且需要有足够的并发效率,因为并发的向分布式系统内写入文件是非常耗时的操作,GFS为了提高并发效率进行了非常优秀的设计,这个后面会提到;
- 高带宽比低延时要更重要: 这也有一点基于内部需求的意思,因为google认为对于GFS的读写很少有人直接参与而是大量的计算,这些操作不需要低延时而是需要足够的带宽以方便计算时尽快拿到足够多的数据,或者在写入时系统能够承受更大的负载。
系统架构
上面讲完了系统设计时的一些基础的假设,来看看GFS的基础架构。GFS是一个分布式的系统,系统中的机器被分为两种其一称为master用于管理整个集群,另一个则是大量的承载数据的机器称为chunk server,下面这幅图展示的是GFS的基础架构以及客户端从系统中读取文件的过程。
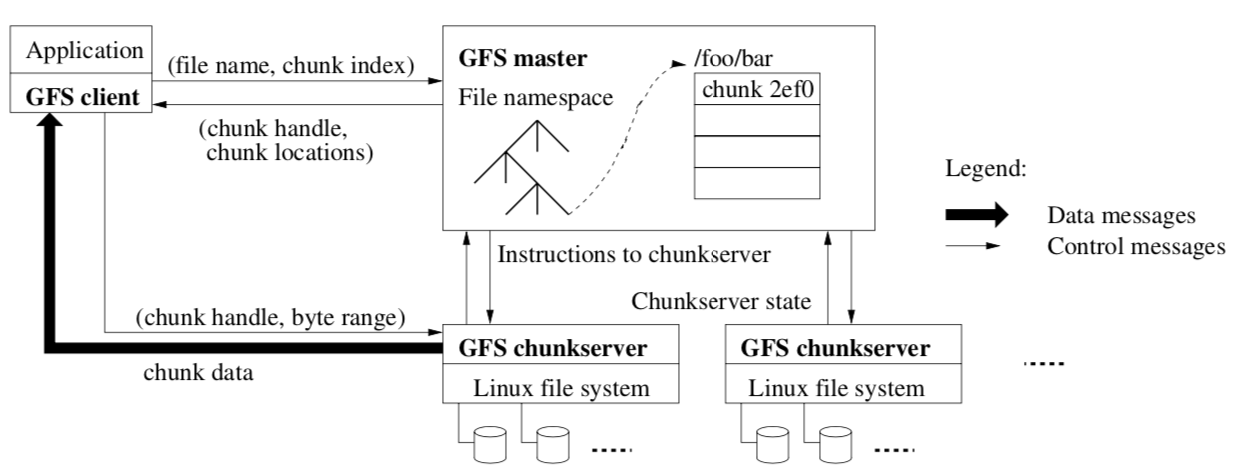
chunk
文件被分成的一个个小块,大小固定为64MB,GFS这样选择这个大小的理由可能有下面几点:1. GFS存储的多为几个GB大小的大文件,分割成较大的块也不会有数据未写完的块儿产生磁盘损耗,事实上因为GFS采用的是惰性分配的策略未写完的块也不会浪费存储空间;2.较大的块可以减少客户端与master的通信次数因为一次较大的块允许客户端在这个块做更多的读写操作;3. 较大的块可以减少master存储的信息。
文件块chunk在创建时即被分配全局唯一的标识符64bit,这可以保证每个chunk的全局唯一性。一个chunk可以有多个副本,存储在不同的机器上,因为如前所述的假设GFS认为机器故障数据丢失是非常常见的而非罕见的异常情况,因此需要为每个chunk创建多个副本以保证即使在机器故障时系统依旧不会丢失数据。
master
未完待续...
