

1、引入依赖
项目pom.xml文件中,引入sharding-jdbc的依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2、增加读写分离的配置
项目bootstrap.yml增加读写分离的配置,以下是dev环境的配置:
spring:
shardingsphere:
datasource:
names: master, slave
master:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/testdb
username: ''
password: ''
slave:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/testdb1
username: ''
password: ''
masterslave:
name: ms
master-data-source-name: master
slave-data-source-names: slave
3、演示效果
3.1、新建测试表
dev环境实际关闭了主从同步,通过手动修改从库的数据来演示效果
CREATE TABLE `t1` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT 'testname',
`age` int(10) unsigned NOT NULL DEFAULT '30',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 主库插入的数据
INSERT INTO `testdb`.`t1`(`id`, `name`, `age`) VALUES (1, 'wangao', 10);
-- 从库插入的数据
INSERT INTO `testdb1`.`t1`(`id`, `name`, `age`) VALUES (1, 'wangao', 20);
3.2、编写数据库访问接口
@Entity
@Table(name = "t1")
@Data
public class User {
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "name")
private String name;
@Column(name = "age")
private Integer age;
}
public interface UserDao extends JpaRepository<User, Integer> {
}
3.3、保存数据
@Test
public void base() {
User user = new User();
user.setName("wangao");
user.setAge(10);
user = userDao.save(user);
System.out.println(user);
}
save方法可以正常返回带自增id的对象:

主库中有新插入的数据:
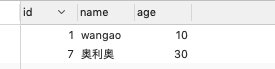
从库中没有数据(主从同步关闭):

3.4、读取数据
读取id为1的数据,注意此时是从从库中获取,年龄为20
@Test
public void readSlave() {
User user = userDao.findById(1).get();
System.out.println(user);
}

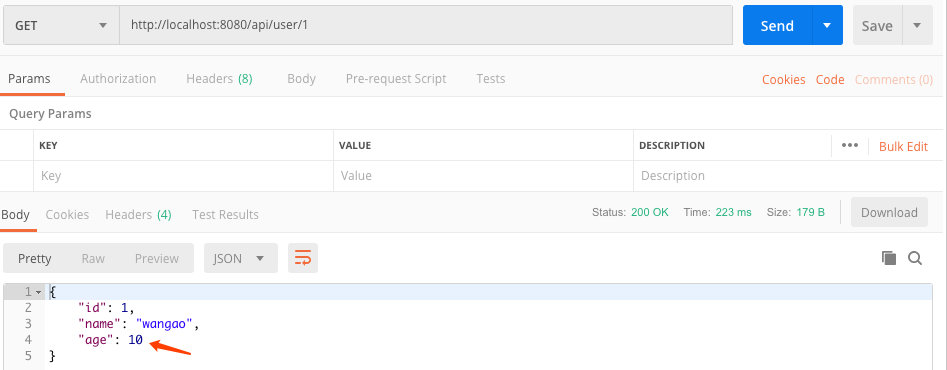
3.5、强制从主库读取
部分情况需要强制从主库进行读取。依旧读取id为1的数据,注意此时是从主库中获取,年龄为10:
@Test
public void readMaster() {
HintManager manager = HintManager.getInstance();
manager.setMasterRouteOnly();
User user = userDao.findById(1).get();
System.out.println(user);
//一定记得最后close
manager.close();
}

3.6、特别注意
官方文档关于读写分离有这样一段话:

这里需要注意的是,默认配置spring.jpa.open-in-view=true,此时一个Restful请求对数据库的连接是同一个,如果存在写入操作,则后续读操作均从主库读取
@RestController
public class UserController {
private final UserDao userDao;
public UserController(UserDao userDao) {
this.userDao = userDao;
}
@GetMapping("api/user/{id}")
public User get(@PathVariable int id) {
//进行写入操作
User user = new User();
user.setName("奥利奥");
user.setAge(30);
user = userDao.save(user);
System.out.println(user);
//进行读取操作
return userDao.findById(id).orElse(null);
}
}
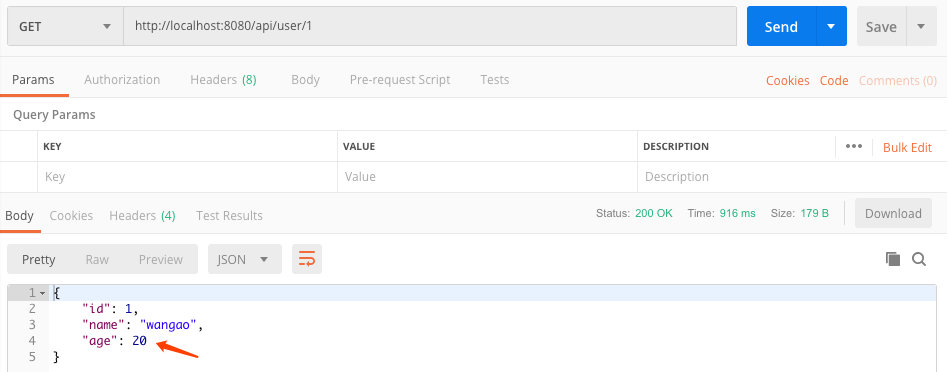
如果将配置改成spring.jpa.open-in-view=false,此时每个操作数据库的连接都会从连接池中获取,这样读取的操作会从从库读取:
4、参考
更多细节可以参考sharding-jdbc的官方网站获取信息:
