

#Elasticsearch分布式的操作
路由文档到分片
我们知道在创建索引的时候我们时可以决定创建多少个主分片(只能创建的时候指定,以后不可修改)和多少个复制分片(副分片,创建的时候可以改变,之后也可以改变)。Elasticsearch有这个规定实际上是为了剪碎文档,它检索文档是基于一个简单的算法来决定的
shard=hash(routing)%number_of_primary_shards
这里的routing是一个任意的字符串,默认是_id,它是可以自定义的。这个routing字符串通过哈希函数生产一个数字,然后初一主分片的数量得到一个余数(remainder),余数的范围永远是0到number_of)shards-1,这个数字就是特定文档的所在的分片(也就是解释了为什么主分片在创建之后不能该的原因)
主分片和复制分片的交互
我们的请求到节点的任意一个接待你,每个节点都有能力来处理请求。每个节点都知道任意文档所在的节点,索引也可以将请求转发到需要的节点,这个节点也称为请求节点。
文档的创建,索引和删除
文档的创建,索引和删除请求都是写操作,它们都必须在主分片上完成功能才能复制到相关和的复制分片上。
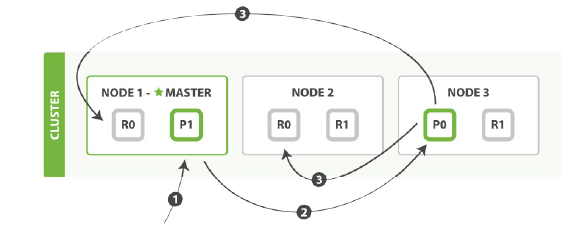
它的步骤如下:
1.客户端给Node1发送创建,索引或者删除请求。
2.节点使用文档的_id确定文档属于分片0,它转发请求到Node3,分片位于该节点上。
3.Node3在主分片上执行请求,如果成功,它转发请求到相应的位于Node1和Node2的复制节点上。如果Node3报告成功到请求的节点,请求节点在报告给客户端。
客户端在收到请求的响应的时候就已经修改成功,主分片和复制分片都已经被应用了。
replication
复制默认的值是sync。这将导致主分片得到的复制分的成功响应才返回。如果将复制节点设置成async,请求在主分片上执行后就会返回客户端。请求依旧转发到复制节点,但是复制节点成功与否我们不得而知。
consistency
默认主分片在写入时需要规定数量(quorum)或者过半的分片(可以使主节点或者复制分片)可用。这是防止数据被写入到错的网络分区
int((primary+number_of_replicas)/2)+1
| consistency值 | 意义 |
|---|---|
| one | 只有一个主分片 |
| all | 所有主分片和复制分片 |
| quorum | 规定数量 |
例子:
如果只有两个节点,给索引定义了三个复制节点,那么我们规定的数据量就是int((primary+3replicas)/2)+1=3,如果活动分片不够没那么就不能够索引或者删除任何文档。
timeout
当分片副本不足时会怎么样?Elasticsearch会等待更多的分片出现,默认是1分钟,如果需要,你可以设置timeout参数种植的更早,例如100表示100毫秒,100s表示100秒。
注意:新索引默认只有一个复制分片,但是这样无法满足quorum的要求需要两个而获得的分片。当然,这个默认设置将组织我们在单一节点集群中进行操作。Wie了避开这个问题,规定只有数量在number_of_replicas大于1时才生效。
检索文档
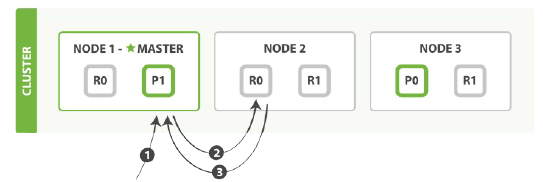
主分片和复制分片上检索一个文档必要的顺序步骤:
1.客户端给节点1发送请求(get) 2.节点使用文档的_id确定文档属于分片0.分片0对应的复制负片分别在三个节点上。此时就会妆发请求给节点2. 3.节点2返回文档给节点1然后返回给客户端。
##局部更新文档
局部修改文档一般需要主节点来完成,然后同步数据到其他的复制节点。
如下例子所示:
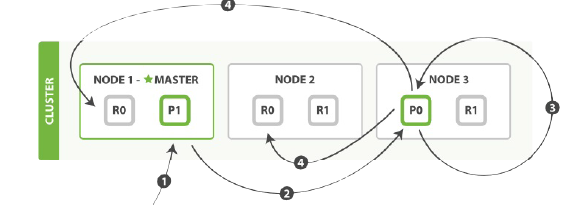
1.客户端给Node1发送修改请求
2.转发请求到主分片所在node3
3.node3从主分片检索出文档,修改_source字段的JSON,然后在主分片上重建索引。如果有其他的进程修改了文档,它以retry_on_conflict设置的次数重复步骤3,都为成功则放弃。
4.如果node3成功则文档更新成功,它同时转发文档的新版本到node1和node2上的复制分片重建索引。当复制节点报告成功,Node3就返回成功给请求节点,然后返回给客户端。
多文档模式
mget和bulk API与单独的文档也是类似的,差别的地方是在于,它把多文档七八个球拆成每个分片的对文档氢气与,然后转发请求。一旦接受每个节点对应的答应,然后整理这些响应组合为一个单独的响应返回给客户端。
mget请求的步骤
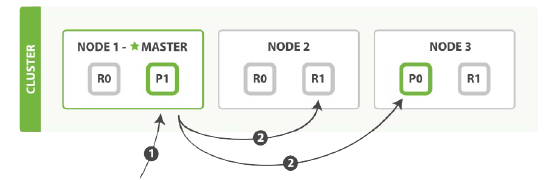
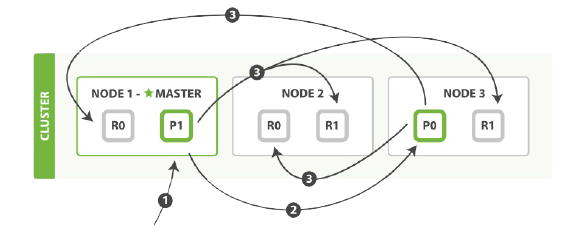
bulk操作的步骤 1.客户端向Node1发送bulk请求 2.Node1为每个分片构建批量请求,然后转发到这些请求所需要的主分片上。 3.住分片一个接一个的按顺序执行操作。当一个操作执行完,住分片转发新文档(或者删除部分)给对应的复制节点,然后执行下一个操作。一旦所有的复制节点报告所有的操作成功完成,节点就报告success给请求接待你,后者(请求节点)整理响应并返回给客户端。
bulk操作的奇怪格式

bulk操作不同于其他操作,不能直接使用JSON作为请求体,因为批量操作每个引用属于不同的主分片,每个分片可能被分布于集群中的某个节点上。这意味这批量操作都要被妆发到对应的分片和节点上。如果单独的请求被包装到JSON数组中,那一位着我们需要:
1.解析JSON为数组(包括文档数组,可能非常大)
2.检查每个请求决定应该到哪个分片上
3.为每个分片创建一个请求的数组
4.序列化这些数组为内部传输格式
5.发送请求到每个分片
这可行,但需要大量的RAM来承载本质上相同的数据,还要创建更多的数据结构使得JVM花更多的时间执行垃圾回收。取而代之的,Elasticsearch则是从网络缓冲区中一行一行的直接读取数据。它使用换行符识别和解析action/metadata行,以决定哪些分片来处理这个请求。这些行请求直接转发到对应的分片上。这些没有冗余复制,没有多余的数据结构。整个请求过程使用最小的内存在进行。
分页
和SQL一样使用LIMIT分页,Elasticsearch接受from和size参数作为分页的关键字: size:结果数,默认是10, from:跳过开始的结果数,默认是0.
注意:
应该注意分页太深或者一次请求太多的结果。结果在返回之前会被排序。但是记住一个请求请求常常涉及很多分片。每个分片生产自己排好序的结果,他们接着需要集中起来拍寻以确保整体排序正确。(例如:如果我们有5个分片,每个分片返回10条结果,5个分片就会返回50条结果,然后在获取整体的10条结果,这就也就是为什么深度分页需要花费更多计算和内存)
简易搜索
Elasticsearch有两种表单:
1.一种是"简易版"的查询字符串(query string) 将所有参数通过查询字符串定义。
GET /test/_doc/_search?q=field1:value3
2.使用JSON完整的表示请求体,这种富搜索语言叫做结构化查询语句(DSL)
GET /test/_doc/_search
{
"query":{
"match":{
"field1":"value3"
}
}
}
