

HDFS
HDFS 块大小--128MB,与面向单一磁盘的文件系统不同,HDFS 中小于一个块大小的文件不会占据整个块的空间。
HDFS 块为 128MB,最小化寻址开销,trade off 磁盘传输数据的时间和定位块开始位置的时间。
HDFS 存储大量小文件弊端:
- MapReduce 处理数据最佳速度刚好与数据在集群中传输速度相同,而小文件将增加运行作业寻址次数;
- 浪费 namenode 的内存。
处理方式:
- 使用 sequence file 合并小文件:将文件名作为 key,文件内容作为 value;
- 使用 CombineFileInputFormat。
HDFS 读文件
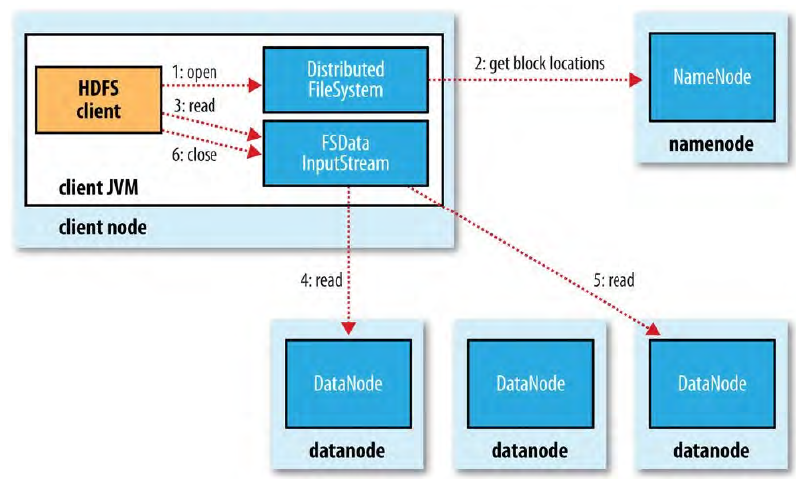
客户端直接连接到 datanode 检索数据
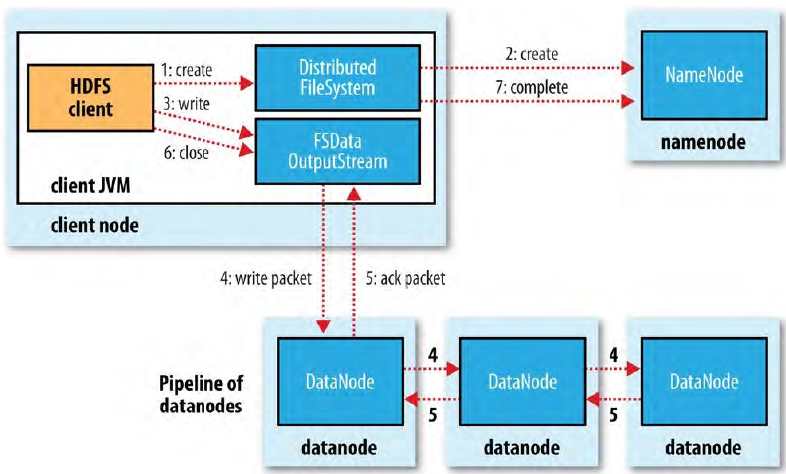
HDFS 写文件
NameNode 目录结构
在格式化时创建:
${dfs.namenode.name.dir}/
├── current
│ ├── VERSION
│ ├── edits_0000000000000000001-0000000000000000019
│ ├── edits_inprogress_0000000000000000020
│ ├── fsimage_0000000000000000000
│ ├── fsimage_0000000000000000000.md5
│ ├── fsimage_0000000000000000019
│ ├── fsimage_0000000000000000019.md5
│ └── seen_txid
└── in_use.lock
edit log 在概念上是一个 entity,但是在磁盘上是多个文件,每个文件称为 segment,同一时间只有一个文件处于打开状态(edits_inprogress_*),先更新日志,然后向 client 返回事务执行成功。
fsimage 文件包含文件系统中所有目录和文件 inode 的序列化信息。每个 inode 是一个文件或目录的元数据的内部描述方式。
fsimage 不记录 DataNode 的 block 存储信息,NameNode 将块信息映射到内存中。DataNode 加入集群后,NameNode 通过向 DataNode 询问 block lists 建立映射关系。
安全模式
NameNode 启动时,首先进入安全模式(首次启动除外),只有访问文件系统元数据的操作能成功执行,文件修改操作(写、删除或重命名)均会失败。如果满足「最小副本条件」,则在 30s 之后退出安全模式。
% hdfs dfsadmin -safemode get
Safe mode is ON
% hdfs dfsadmin -safemode wait
# command to read or write a file
% hdfs dfsadmin -safemode enter
Safe mode is ON
% hdfs dfsadmin -safemode leave
Safe mode is OFF
Secondary namenode
创建 CheckPoint 步骤:
- 请求 NameNode 停止使用 edits 文件,同时 NameNode 更新 seen_txid 文件;
- Secondary namenode 从 NameNode 获取最新的 fsimage 和 edits 文件(HTTP GET);
- Secondary namenode 将 fsimage 载入内存,逐一执行 edits 事务,创建新的 fsimage;
- 将新的 fsimage 发送回 NameNode(HTTP PUT),NameNode 将其保存为临时的 .ckpt 文件;
- NameNode 重新命名临时的 fsimage 以便日后使用。
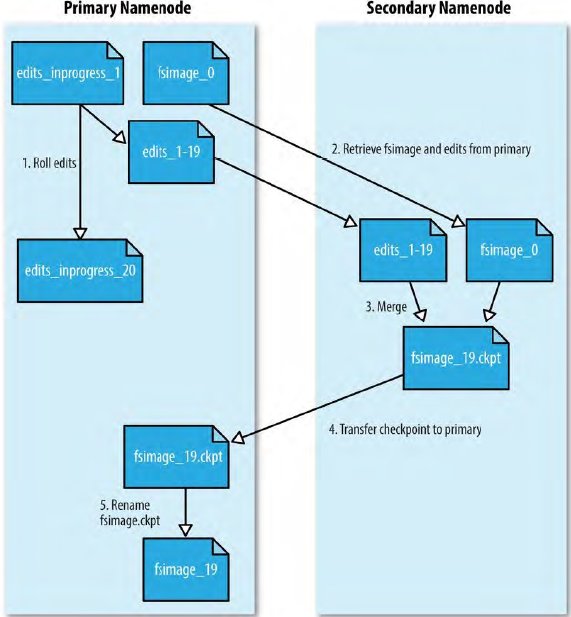
为何 Secondary namenode 和 NameNode 需要相近内存需求?因为 Secondary namenode 也把 fsimage 文件载入内存。
DataNode 目录结构
${dfs.datanode.data.dir}/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073741825
│ │ │ ├── blk_1073741825_1001.meta
│ │ │ ├── blk_1073741826
│ │ │ └── blk_1073741826_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
HDFS Federation
在联邦环境下,每一个 namenode 维护一个命名空间卷(namespace volume),由命名空间元数据和一个数据块池(block pool)组成,每个 namenode 管理文件系统命名空间一部分。
HDFS 高可用性(HA)
Hadoop 2 增加支持,配置一对 active-standby namenode。
- 编辑日志共享;
- datanode 同时向两个 namenode 发送数据块处理报告;
- client 使用特殊机制处理 namenode 失效问题;
- Secondary namenode 被 standby namenode 包含。
-
两种共享存储:NFS 过滤器和群体日志管理器(QJM,quorum journal manager)。
-
故障转移控制器(failover controller),默认使用 ZooKeeper 来确保有且仅有一个 activity namenode,每个 namenode 都运行该控制器,namenode 失效时切换 namenode。
管理员主动发起故障转移,称为 graceful failover。确保先前 namenode 不会影响系统,称为规避(fencing)。
对 QJM 设置 ssh 规避命令杀死 namenode。使用 NFS 过滤器实现共享编辑日志需要更有力规避方法。
Hadoop 文件系统
| Hadoop 文件系统 | URI 方案 | Java 实现 |
|---|---|---|
| Local | file | fs.LocalFileSystem |
| hdfs | hdfs | hdfs.DistributedFileSystem |
| WebHDFS | webhdfs | - |
| Secure WebHDFS | swebhdfs | - |
| HAR | har | fs.HarFileSystem |
| View | viewfs | viewfs.ViewFileSystem |
| FTP | ftp | - |
| Hadoop FS scheme | URI 格式 |
|---|---|
| WebHDFS | webhdfs://<HOST>:<HTTP_PORT>/<PATH> |
| Secure WebHDFS | swebhdfs://<HOST>:<HTTP_PORT>/<PATH> |
| HDFS | hdfs://<HOST>:<RPC_PORT>/<PATH> |
| REST API | http://<HOST>:<HTTP_PORT>/webhdfs/v1/<PATH>?op=... |
通过 FileSystem API 读取数据
- 获取 FS 实例:
public static FileSystem get ( Configuration conf ) throws IOException
public static FileSystem get ( URI uri, Configuration conf ) throws IOException
public static FileSystem get ( URI uri, Configuration conf, String user ) throws IOException
获取本地 FS:
public static LocalFileSystem getLocal ( Configuration conf ) throws IOException
- 调用 open() 函数获取文件输入流:
public FSDataInputStream open ( Path file ) throws IOException
public abstract FSDataInputStream open ( Path file, int buffersize ) throws IOException
FSDataOutputStream 只能在文件末尾写入,刷新方法包含:
- flush():当前正写入的块是不可见的;
- hflush():不能保证写到磁盘中,但写入内存,且可见;
- hsync():写入磁盘
其他方法:
- 创建目录:
public boolean mkdirs ( Path file ) throws IOException
- FileStatus 类封装了文件系统中文件和目录的元数据,FileSystem 类中 getFileStatus() 方法获取 FileStatus 对象;
- 列出文件:FileSystem 中的 listStatus();
- 文件模式,执行通配(globbing):
public FileStatus[] globStatus ( Path pathPattern ) throws IOException
public FileStatus[] globStatus ( Path pathPattern, PathFilter pathFilter ) throws IOException
