

http1.0、http1.1到http2的一些发展
http1.0定义了最初的http规范,包括body、header的格式等,不支持持久连接,每发送一次请求都会建立一次tcp链接,效率比较低。如下图所示:


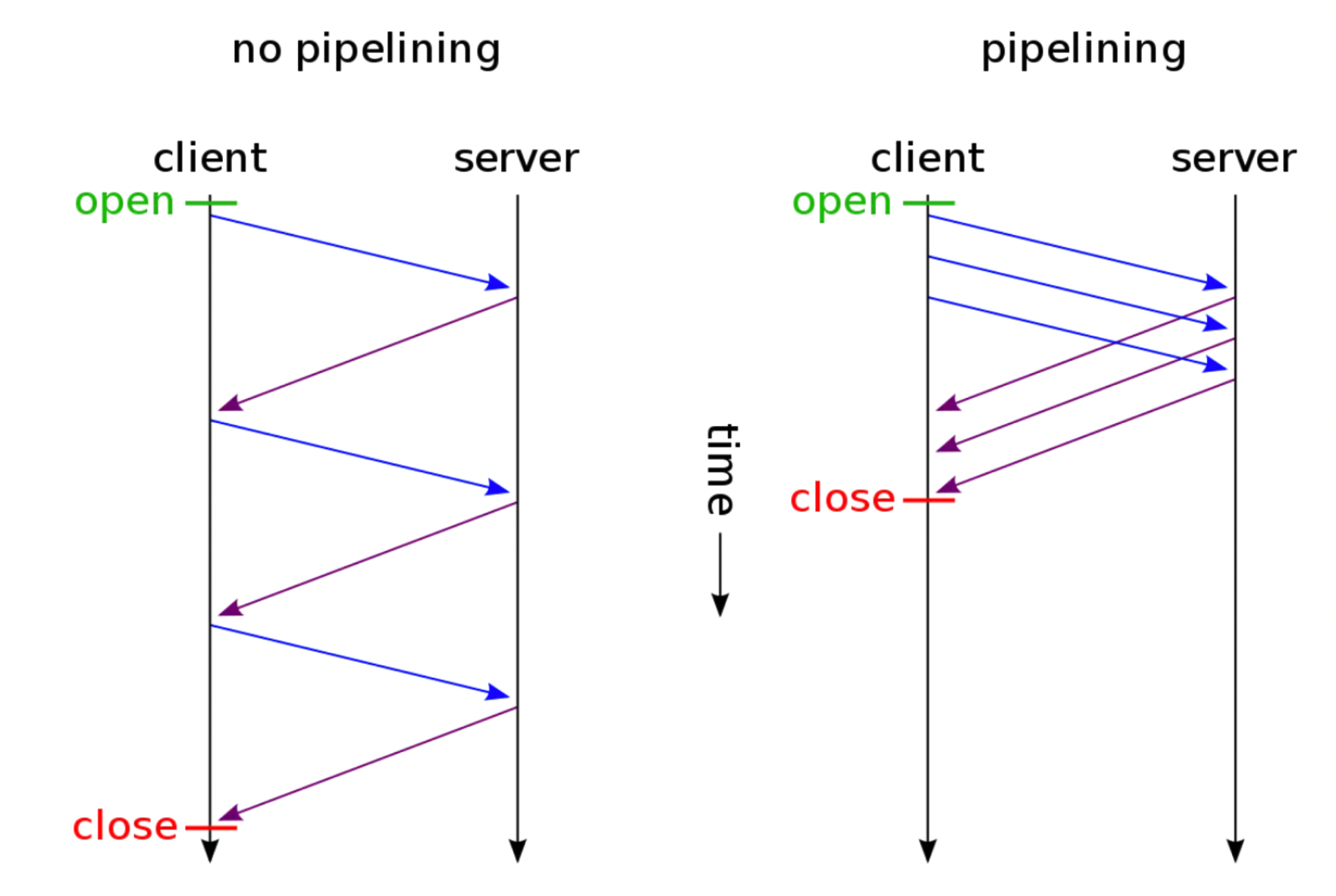
后来http2实现了多路复用,解决了http1.1队头阻塞的问题,大幅的提升了web的性能。
HTTP/2: the Future of the Internet 。这个例子是Akama公司提供的一个官方演示,同时请求379张图片,从load time上就可以看出http2在速度上的优势。
除此之外http2还增加了流优先级、头部压缩、服务端推送等主要内容。在与1.1保持语义兼容的基础上,进一步减少了网络延迟。现在绝大部分的浏览器都已经实现了对http2的支持,下面是2015年http2刚提出的时候浏览器的支持情况,现在http2的支持情况:
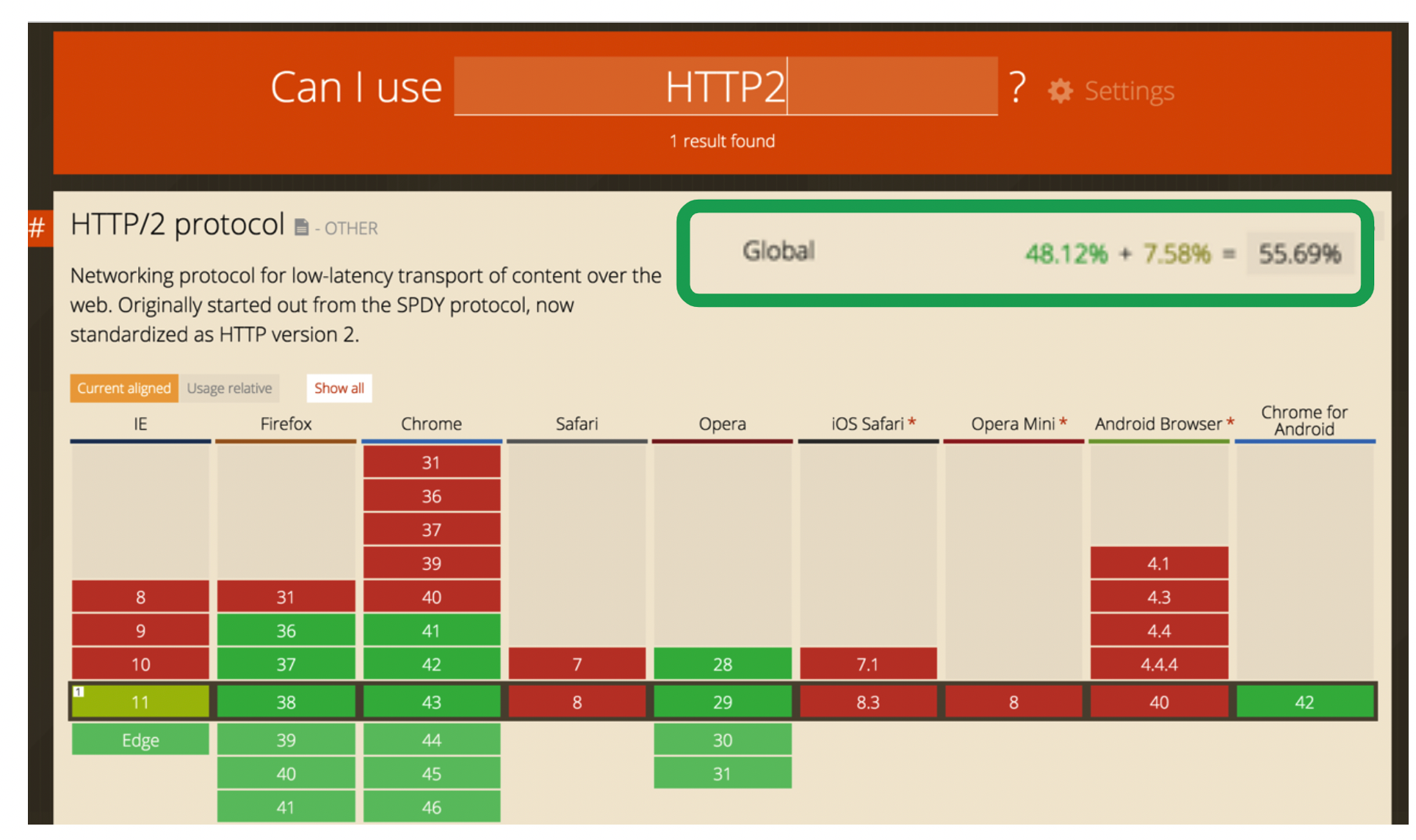
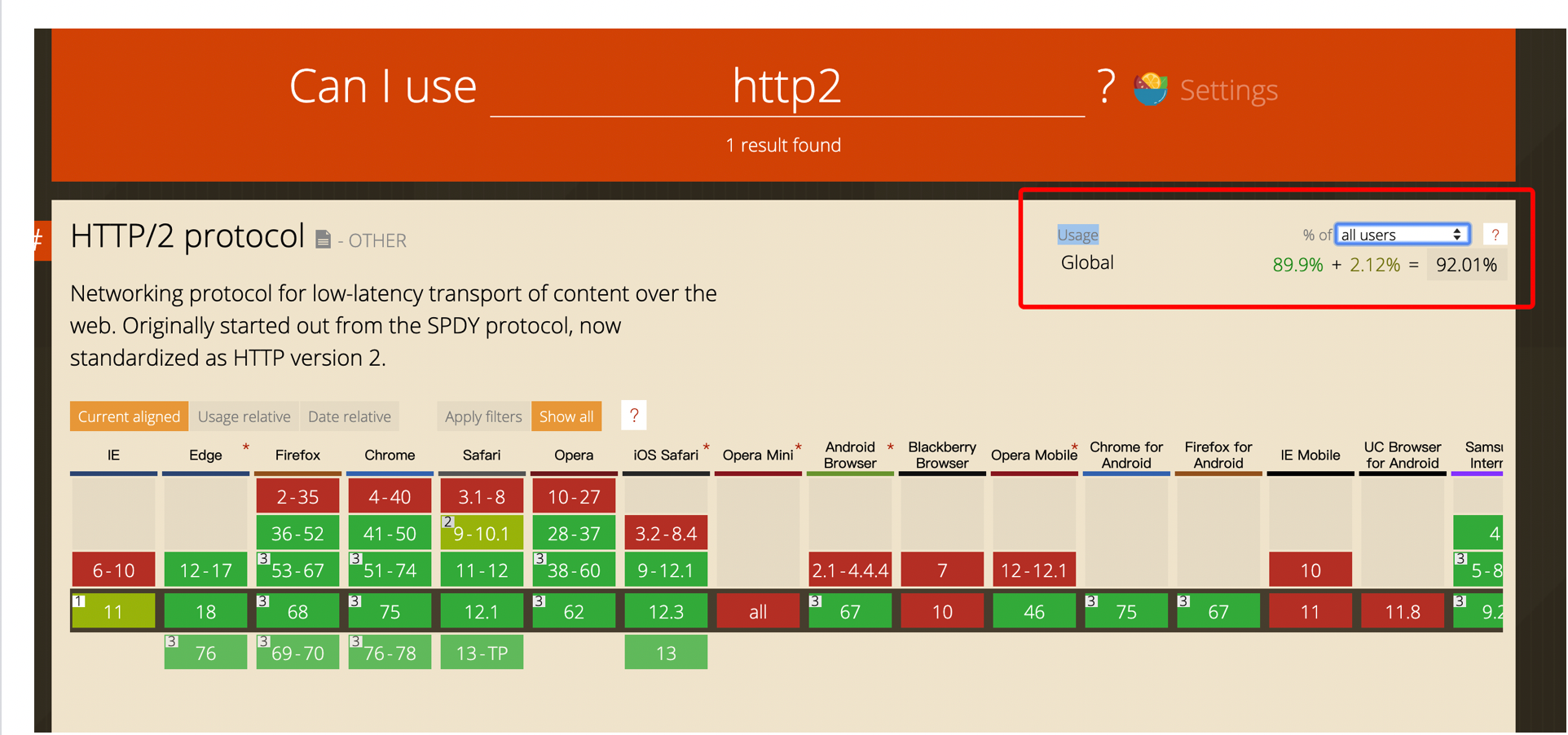
可以看到浏览器对http2的支持情况还是很良好的。
多路复用
多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。
二进制分帧层
http2.0中引入了帧和流的概念,首先来看看什么是帧和流。
帧
http2.0中最小的通信单元。每个帧都以固定的9字节首部开始,里面会至少标明其所属的流。
在来自不同流的帧可以被交织,然后通过每帧的头部中的嵌入流标识符重新组装。但是对每一个流本身而言,流中所属帧的发送顺序
是不能随意交织的,因为接收者以它们收到帧的顺序处理。
流
已建立连接内的双向字节流。每个帧都有自己所属的流,通过所属的流识别当前帧是哪一个请求响应。一条tcp连接可以承载任意数量的双向流。
二进制分帧则是把原来http所传输的信息划分为多个粒度更小的帧,并对其进行二进制编码,然后将其映射到属于特定流的消息。二进制分帧层指示如何在客户端和服务器之间封装和传输http消息。
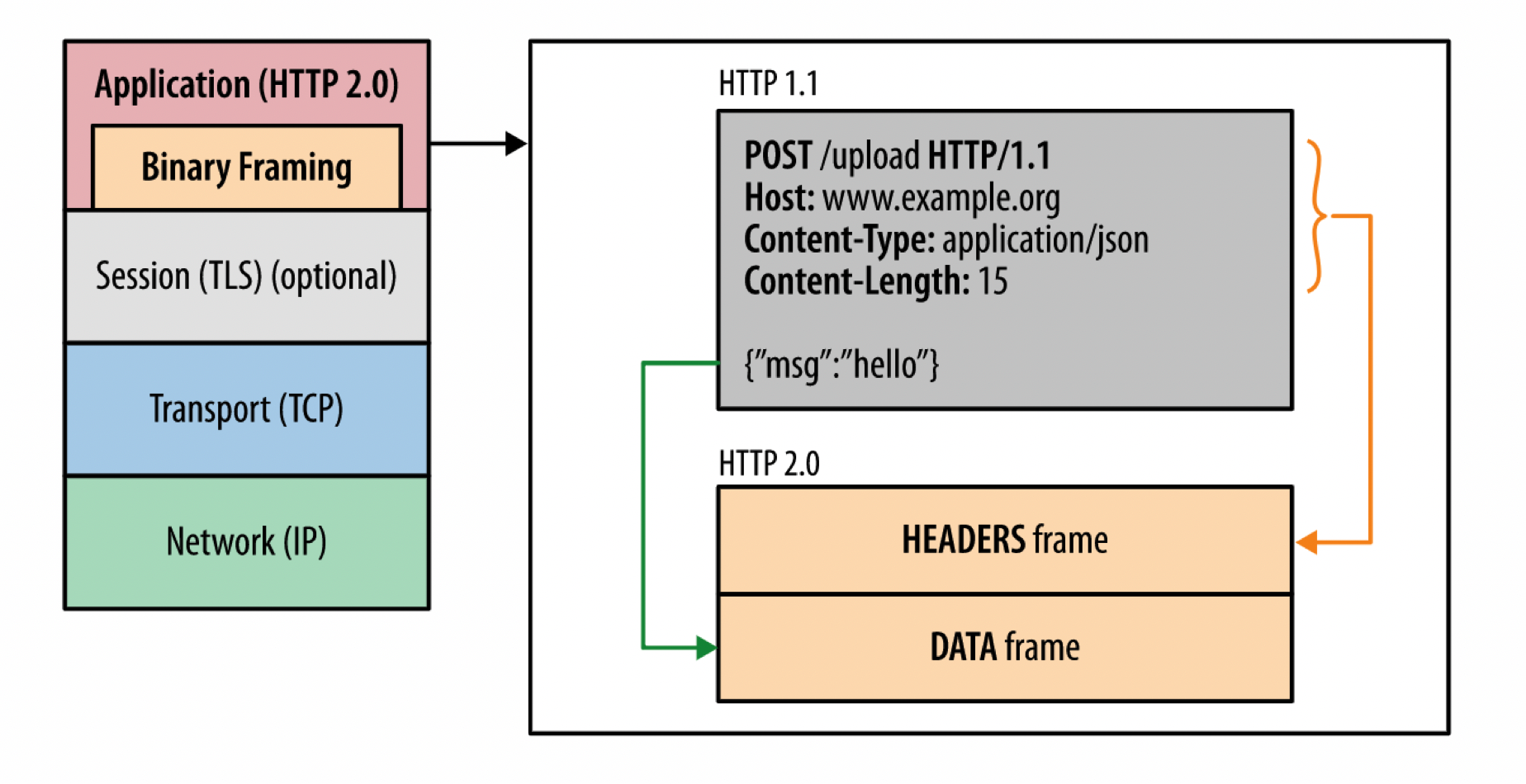
为什么要二进制编码?
在http1.x中都是直接传输的纯文本,二进制与之相比解析起来更高效,错误更少。因为它们对如空白字符的处理、大小写、行尾、空链接等的处理很有帮助.
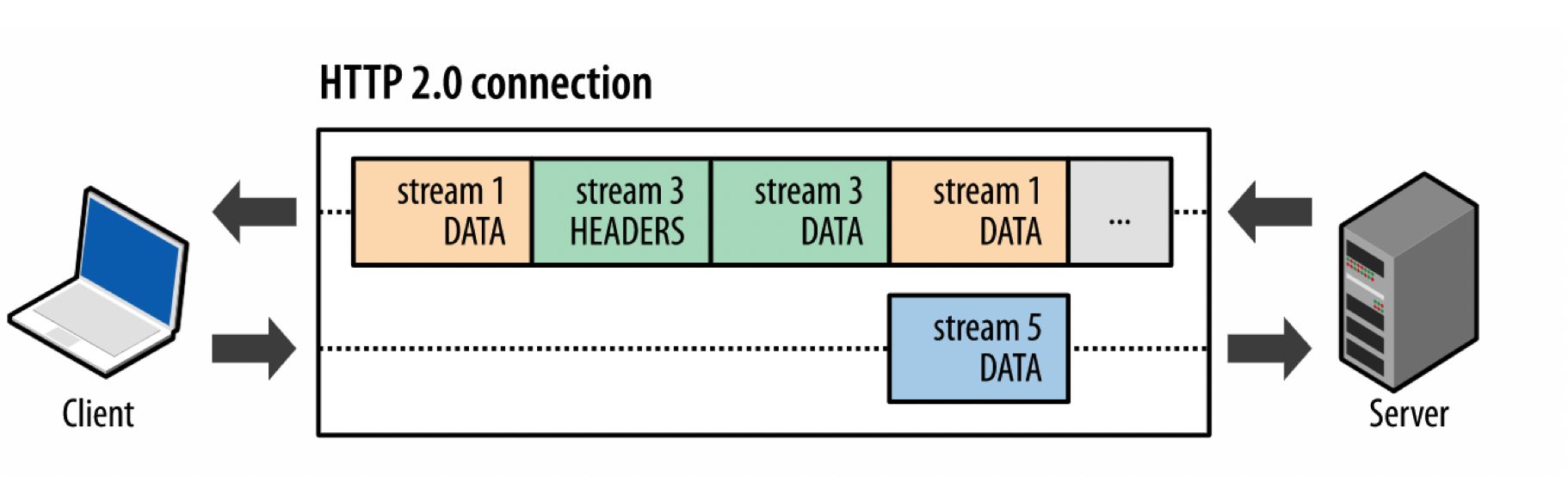
在http2.0中,多路复用可以很好的解决这些问题,因为引入了新的二进制分帧层,一条tcp连接可以承载任意数量的双向流,所以当发起多个并发请求时,这些请求-响应流就可以共用一个tcp连接,不同流的帧可以交织,通过流标识符识别帧,再通过每个流中帧到达的顺序进行组装帧,而不用等待第一个请求的响应发送完,再发送下一个请求,很好的解决了http队头阻塞的问题。如下图所示:
多路复用带来的一些变化
-
由于tcp连接数的减少,使网络拥塞状况得到改善,并且减少了tcp握手、慢启动带来的时延。
-
单连接多资源的方式,减少服务端连接压力(连接会消耗服务端的cpu和内存),内存占用更少,连接吞吐量更大。
-
因为一个连接可以承载任意数量个数据流,所以在http1.x时代的一些优化方案在2.0时代中并不适用。比如:合并请求、雪碧图、域名分区(域名分区数量过多的话会导致频繁的dns查询,同样的存在慢启动的问题,可能还会造成网络拥塞)
流优先级
因为一个连接里面承载了多个流,并且不同流的帧可以交错发送,所以客户端和服务器交付不同流的帧的顺序成为了关键的性能考虑因素。为了实现这一点,http2 允许每个流具有流依赖关系以及相关的权重:
权重:可以为每个流分配1到256之间的整数权重
流依赖关系:每个流可以明确依赖一个流
客户端使用权重和流依赖罐子的组合信息,向服务端构造和传递“优先级树”,该树表明其希望如何接收响应,即我们期望优先级越高的请求越快得到响应,服务端使用此信息确定流处理的优先级,控制cpu、内存和其他资源的分配。一旦响应数据可用,就分配带宽以确保向客户端最佳的传递高优先级响应。
流优先级的计算
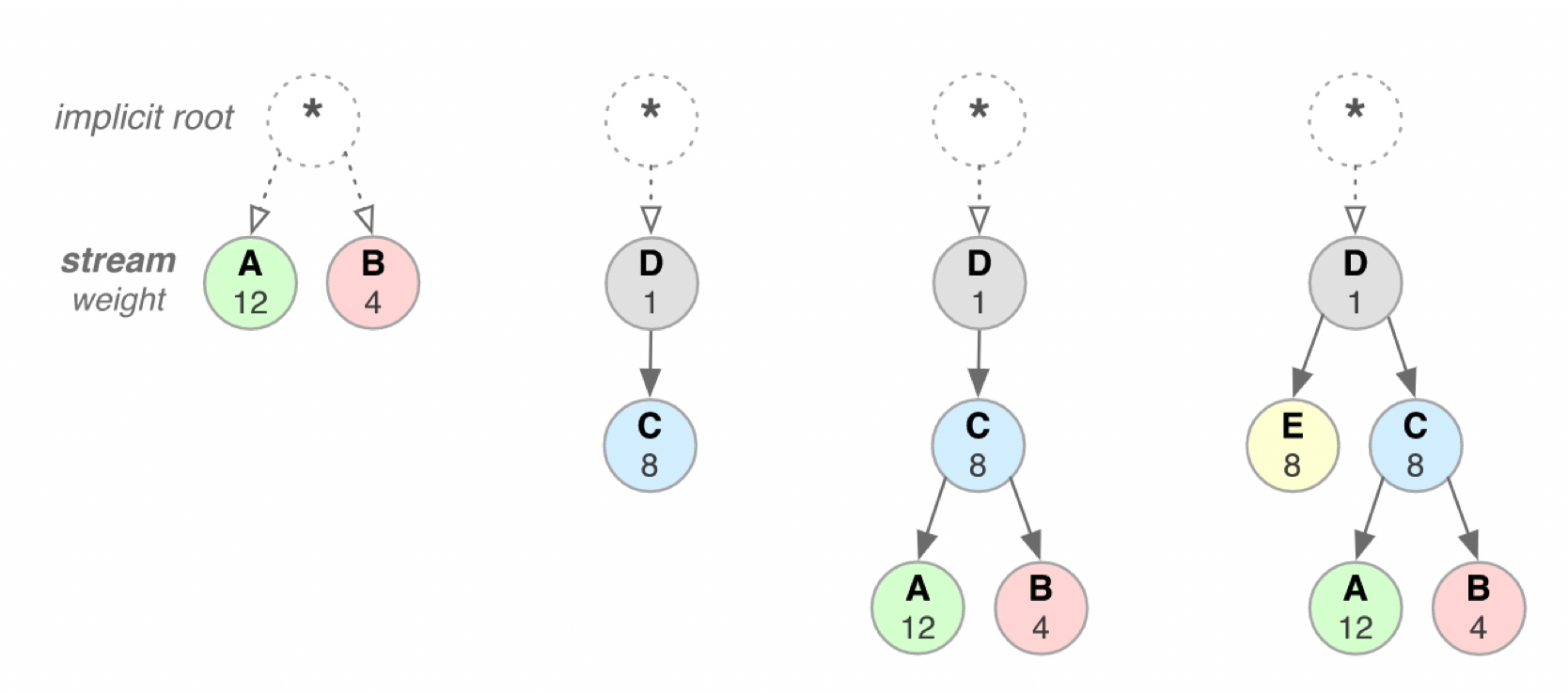
通过引用另一个流的唯一标识符作为其父级来声明HTTP / 2中的流依赖性; 如果省略,则称该流依赖于“根流”。流依赖性表明,如果可能,则希望在处理它之前先为父流分配资源。例如:C依赖于D,则表明请在响应C之前先处理并响应D。
共享相同父级的流应该按其权重比例分配资源。例如对于上图流A和流B,他们都是根流,A的权重为12,B的权重为4,则A应该接收到资源的比例为12/16=3/4。B接收到资源的比例为1/4。
不过,值得注意的是,流优先级只是表达了一种传输偏好,不表示绝对的要求,因此不保证特定的处理或传输顺序。虽然看上去觉得违反直觉,毕竟设置优先级就是希望资源按照我设定的顺序返回,可是确又并不能保证绝对的顺序。但其实这是合理的行为:当高优先级的资源阻塞的时候,低优先级的资源不会被阻塞。
流优先级的设置
流优先级是由客户端设置,发给服务端的。浏览器中有一个默认的优先级。浏览器基于自身对资源重要性的判读,为不同的资源分配相应的优先级。 例如,页面中的head、 script标签将以High优先级(比优先级为 Highest 的 CSS 低)在 Chrome 中加载;但是,如果该标签具有异步属性(也就是说它能以异步方式加载和运行),其优先级将更改为 Low。
头部压缩
http1.x中,只有针对body的压缩,而http头部都是直接以纯文本的形式传输的,当请求很多的时候,未经压缩的头部会造成对网络资源的浪费,头部经过压缩后,可以极大的减少体积,以下是打开淘宝首页抓包的一个结果:
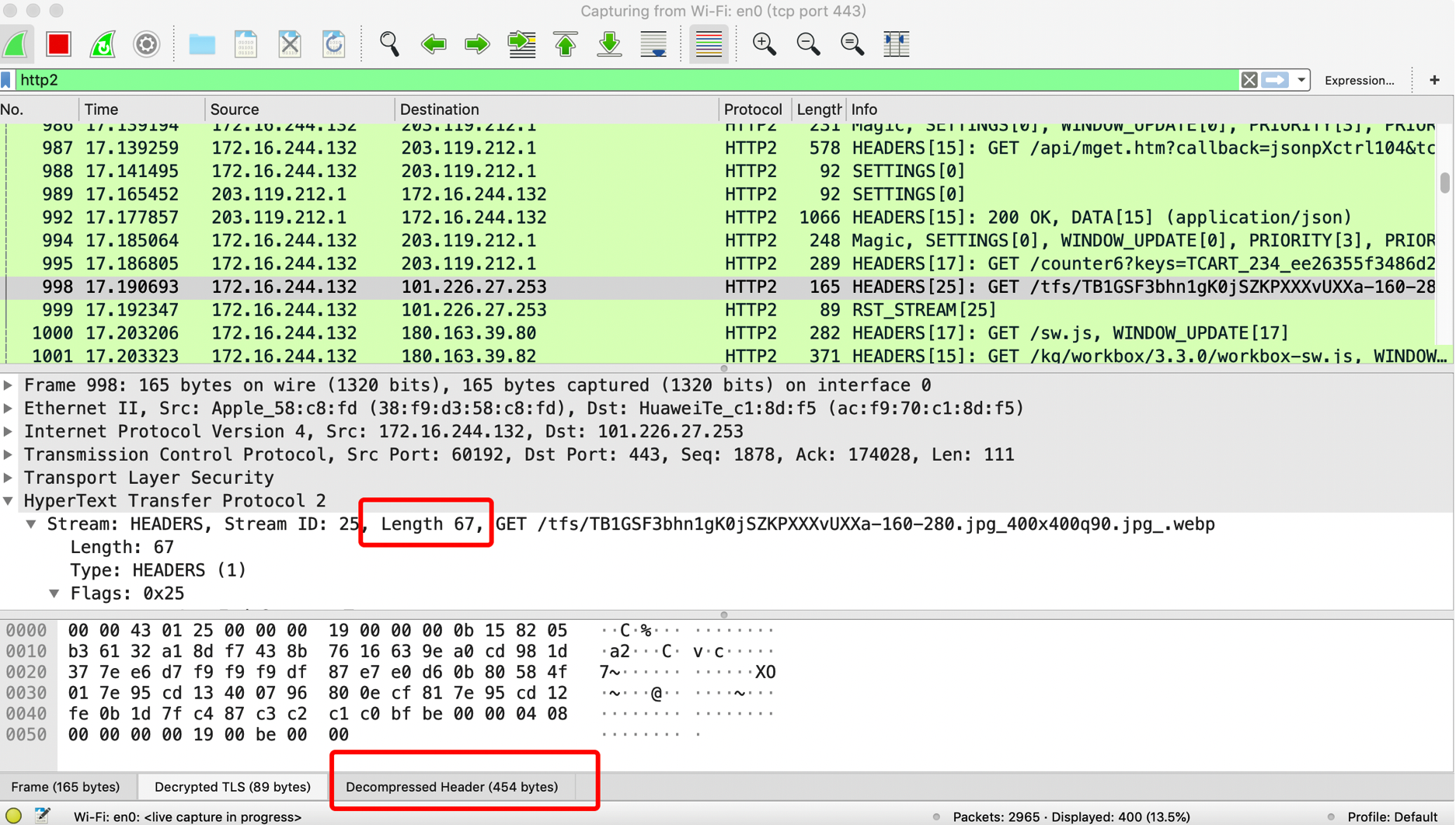
可以看到经过压缩后的头部长度只要67个字节,而解压后的头部却有454个字节。
头部压缩需要在客户端和服务器之间:
-
维护一份静态表,在规范中定义并提供所有连接可能使用的公共HTTP头字段的列表(例如,有效的头名称);
-
维护一份动态表,最初为空,可以动态地添加内容
-
支持基于静态哈夫曼表的哈夫曼编码
简要过程:通过对先前未见过的值使用静态哈夫曼编码,并把这个头部插入动态表中。而如果是已经存在于每一侧的静态表或动态的值进行索引的替换。
服务端推送
一个典型的web程序由很多资源组成,但所有这些资源都是客户端通过检查服务端所提供的文档发现的。而服务端推送可以让服务器除了响应原始请求以外,还可以把其他资源推送到服务端,客户端不必请求每个资源,减少了浏览器接收响应并解析html的时间。推送的资源必须遵循同源策略。如下图所示:
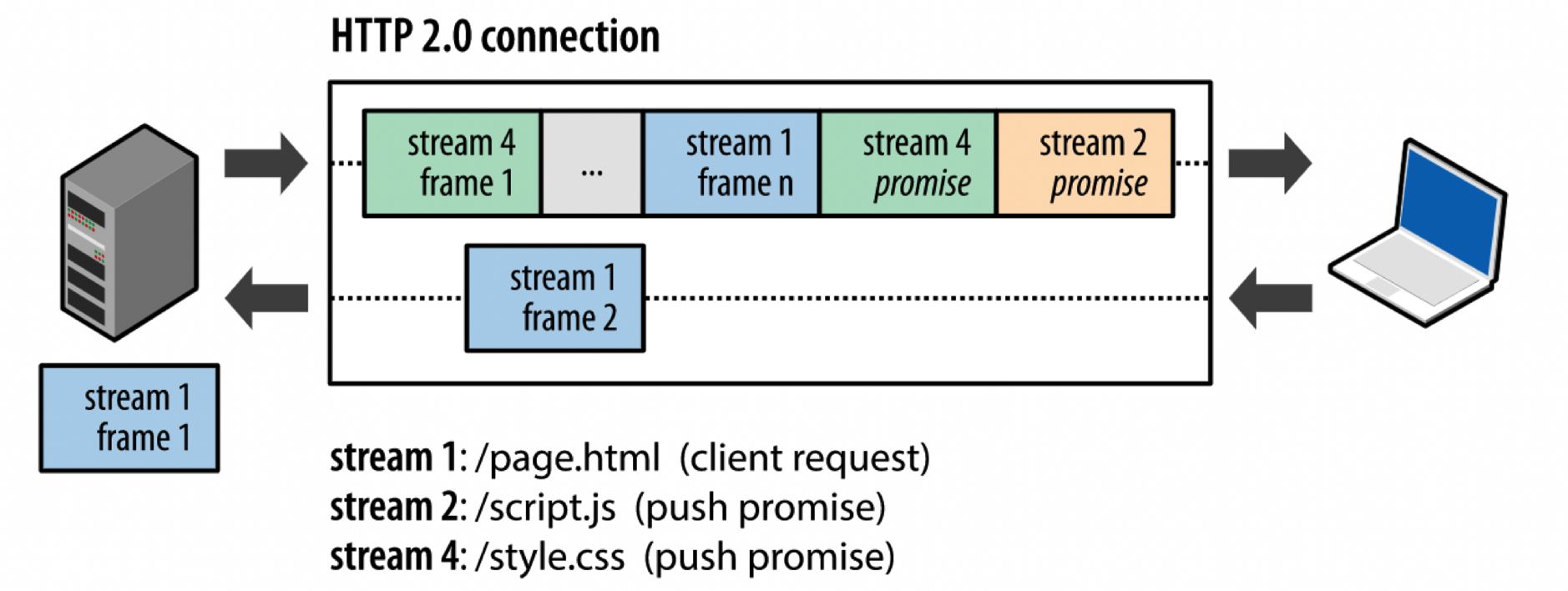
内联css、javascript或其他资源,其实也相当于是将该资源推送到客户端(但客户端不能拒绝,也没有缓存),而无需等待客户端请求。但使用http2的服务端推送,可以使得客户端缓存这些推送的资源,可以在不同的页面上重用,客户端也可以拒绝推送资源(比如,该资源已经在缓存中时)。一旦客户端收到PUSH_PROMISE帧,它就可以选择拒绝流(通过RST_STREAM帧)(如果它想要的话)(例如,资源已经在缓存中),这是对HTTP / 1.x的重要改进。相比之下,资源内联的使用,这是HTTP / 1.x的流行“优化”,相当于“强制推送”:客户端不能单独选择退出,取消它或处理内联资源。
