

ES是从厨房里走出来的,原型是Shay Banon给妻子做的食谱搜索引擎,一开始便充满了爱的味道。
儿女情长什么的,最影响程序员发挥了!
最终,ElasticSearch斩断情愫,成为一个基于Lucene的分布式存储。安装后访问其页面,会显示:”You Know, for Search“,这句平凡的语句无意中透露的自信,深于一切怀疑和平淡。
几点说明

基础概念
ES是典型的分布式系统。包含一到多个内存型节点。有分片,也有副本,可靠性高,自适应能力强。ES采用多机并行能力来进行扩展,是建立在一系列层级数据结构上的。这些抽象作为一个全局的路由表,存在于每个运行的实例上,给了ES强大的功能和扩展能力。
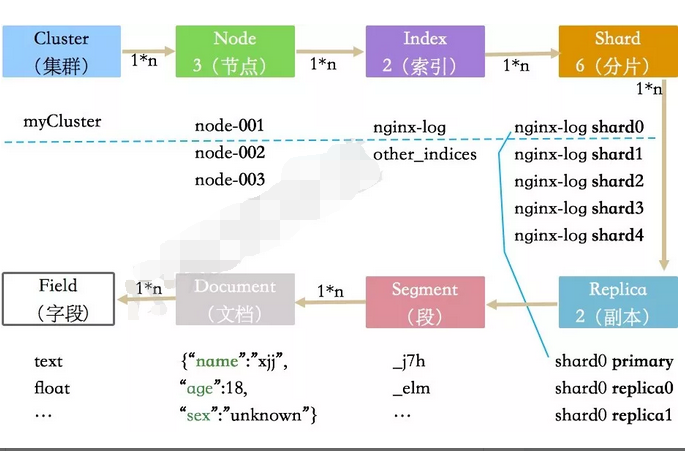

索引类型
倒排索引
很多同学有一个误解,以为ES是一个全文搜索引擎,那么就只有倒排索引这一种索引类型,那是错的。数据在写入es时,会产生多份数据用于不同查询方式,使用的索引结构也不相同。
ES默认是对所有字段进行索引的(也就是倒排索引),如果不需要,可以在mapping中将index属性设置为no;如果字段需要精确查找,则设置为not_analyzed。
为了增加倒排索引的Term查找速度,ES还专门做了Term index,它的本质是一棵Trie(前缀)树(使用FST技术压缩)。
_all是一个特殊的字段,可以根据某个关键词,搜索整个文档内容(而不是某个字段),这个默认是关闭的。
列式存储
按照以上的倒排索引结构,查找包含某个term的文档是非常迅捷的。如果要对这个字段进行排序的话,倒排索引就捉襟见肘了,需要使用其他的存储结构进行索引。
ES使用冗余的方式进行解决这个问题,它存储了另一份数据,也就是Doc Values。可以说Doc Values是一个列式存储结构,适合排序、聚合操作等。放在内存中的fielddata功能和它类似,但没有内存容量的限制,大数据量优先使用。
到此为止,ES已经默认按照不同的结构存储了两份数据了。但如果你不需要,还是可以禁用的。同样是在mapping映射中,给字段赋予属性doc_values:false即可。
假如你用的是ELKB系列,倒排索引根本就没用到。
行式存储
而作为行存的_source字段,以json方式存储了原始文档。一般是不需要关闭的。但如果你的文档字段比较多,根据搜索后查出列表,再根据列表的数据到其他存储获取,那么就可以将_source关掉。类似的,设置_source{enabled:false}即可。
如果只想要几个字段被存储,可以使用include。
_source:{
includes:[field1,field2]
}
ES有太多的这种细化的自定义,不再详叙。
写入过程
找到分片
某个分片具体在哪个节点上,由ES自行决定。每个节点都缓存了这些路由信息,所以,你的请求发送到任何一个ES节点上,都可以执行。
ES选择的分片路由算法是Hash,这决定了它的分片数一旦确定,不可更改。因为一旦变了,路由的数据就完全不正确了。
如果Request中指定了路由条件,则直接使用Request中的Routing,否则使用Mapping中配置的,如果Mapping中无配置,则使用默认的_id字段值。
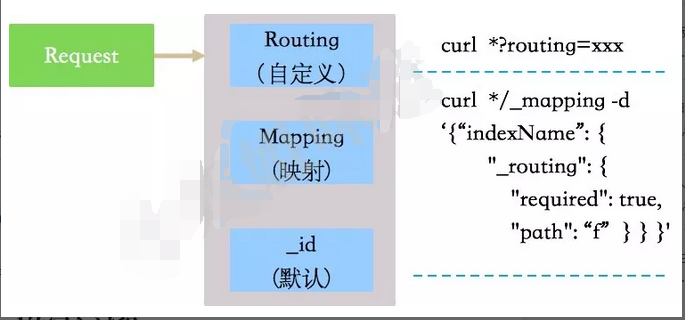
默认参与Hash计算的字段是_id,使用ES自带的生成器能较好的平均数据,使用自定义的id可能会产生数据倾斜。
shard = hash(routing) % number_of_primary_shards
剩下的,就是单机索引的事了。
单机Shard的写入过程
ES的写入性能可以很高(尤其是批量写入),取决于你的配置。一个文档要写入索引,直到读可见,要经过一系列的缓冲和合并。我们拿ES官方博客的一张图来说明。
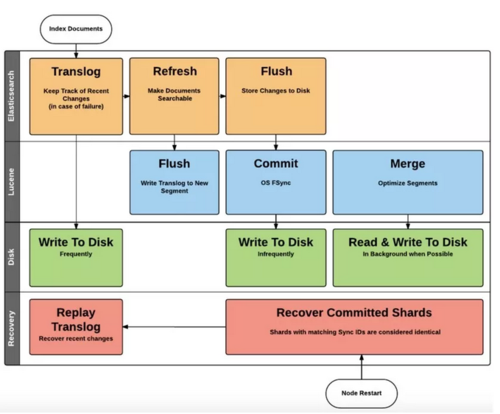
ES的底层存储是Lucene,包含一系列的反向索引。这样的一批索引的信息就是上面提到的段(segment)。但记录不会直接写入段,而是先写入一个缓冲区。
当缓冲区满了,或者在缓冲区呆的够久,达到了刷新时间(划重点),会一次性将缓冲区的内容写进段中。这也是为什么refresh_interval属性的配置会严重的影响性能。如果你不要很高的实时性,不妨将其配置的大一点。
缓冲区默认使用堆空间的10%,最小值为48mb(针对于分片的)。如果你的索引多且写入重,这部分内存的占用是可观的,可以适当加大。
问题是Segment是不可变的,删除、更新操作,并不能在原来的段上进行。ES对待所有的操作都是相似的,并不区别对待,删除和更新,有着和写入一样的mege过程。这会生成大量的段,每个段会占用一个文件句柄,会浪费大量资源。ES有专门的进程负责段的自动合并,我们不需要手动干涉。
段的合并会浪费大量的I/O和CPU资源,有tiered(默认)、log_byte_size、
log_doc三种合并策略,每种策略都有各自的配置参数。可惜的是,索引一旦确定,策略就不能更改了。调整这些参数,大多情况下效果显著。
常用的配置参数是执行归并的线程数,max_bytes_per_sec已经不再使用了。
index.merge.scheduler.max_thread_count
如果你的I/O过重,可以适量减少此值的大小。
即然是先写到缓冲区,就有丢的可能,比如突然断电。为了解决此问题,ES在写Buffer的同时,也将数据写入一个叫做translog的文件。这个文件是顺序写,所以速度比较快。translog是故障恢复时,回放故障发生前夕数据的唯一途径。这些数据,没有机会能够写入到Lucene中。
将translog的写入周期改成async的,而不是基于请求的,会显著减少I/O占用。
操作系统在将磁盘写入文件时,也会有相应的buffer cache,这与其他DB如MySQL、PG的工作方式是一样的,使用fsync保证文件能够刷到磁盘上,不多描述。
节点类型
ES按照不同的用途和场景,划分了不同的节点类型。
Master Node 有资格被选择为主节点,然后控制整个集群
Data Node 该节点能够保存数据和执行操作
Tribe Node 部落节点,可以连接多个集群,对外提供统一的入口
Ingest Node 定义一个pipeline来处理数据,可以替代logstash中的某些功能
客户端节点 不保存数据也不协调集群,仅响应用户请求,将其发送到其他节点
End
ES通过冗余多份数据达到不同的用途,开箱即用。开箱即用的意思也就是认识成本低,学习成本大,先把你吸引进门再说。
ES不是一匹好驯服的野马。通常,它并不像官方和其他PPT宣传的那样无所不能,你可能经常在OOM和分片移动中度日。
希望在使用ES之前,能够了解它的一些底层设计结构。这样,在遇到一些瓶颈的限制以后,能够了解到它为什么有这样或者那样的反应;另外在做一些解决方案的时候,能够多给自己一点底气。
不过话说回来,上得了厅房,下得了厨房的女人,大家还是都喜欢~
