

添加索引
- 索引(index)是存储数据的地方,实际上索引是一个指向一个或者多个分片的"逻辑命名空间"。
- 一个分片(shard)是一个最小级别的"工作单元",它只是存储了索引中索引数据的一部分,除此之外一个shard就是一个Lucenes实例。分片在集群内是很重要的,在集群扩大或者缩小的时候,Elasticsearch将会自动爱你的节点间迁移分片,以便保持集群的平衡。
- 复制分片只是主分片的一个副本,它可以防止硬件的故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的分片取回文档。主分片是在索引创建的时候就已经确定的,复制分片完全可以在后期调整。
现在我们可以创建一个名为blog的索引,给该索引分配3个主分片和一个副分片(每个主分片一个副分片)
PUT /blog
{
"settings":{
"number_of_shards": 3,
"number_of_replicas": 1
}
}
此时我们在调用 GET /_cluster/health 可以得到如下的结果
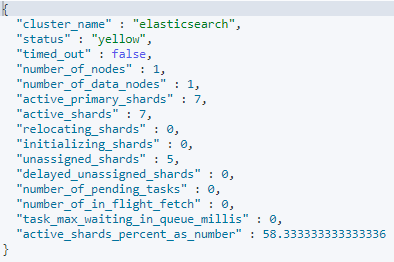
根据结果可以得知集群的状态是yellow,就是主分片都是可以使用的,但是副分片不都可以使用。unassigned_shards的结果是5,表示有5个分片是没有被分配的,因为这些副分片没有被分配,就是无法使用备份主分片的数据,如果出现节点的故障就无法实现故障转移,所以这个集群的状态是yellow的。
故障转移
在单一节点上运行会存在单点故障,为了防止单点故障我们需要做的就是启动更多的节点,如果我们在集群里面拓展了节点,那么从节点就会分配在其他节点上。
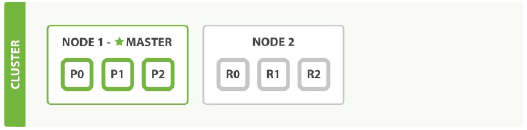
这个集群最大可以拓展到六个节点。
文档
程序中大多数的实体或对象能够被序列化为包含键值对的JSON对象,键是自带你或者属性的名字,值可以是字符出阿伯,数字,不二类型,另外一个对象,值数组或者其他特殊类型。实际上,我们可以认为对象(object)和文档(document)是等价的。但是它们之间是有差别:对象是一个JSON结构体----类似与哈希,hashmao,字典或者关联数组,对象中可以包含其他对象。在ES中,翁当这个是有特殊含义的,它只要代表了顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID表示并存储Elasticsearch中)
文档字定义ID和自增id
字定义ID
PUT /{index}/{type}/{id} { "field":"value" ... }
自增ID
POST /{index}/{type} { "field":"value" ... }
##索引文档
GET /website/blog/123/_source
返回结果:
{
"title" : "My first blog entry",
"text" : "Just trying this out...",
"date" : "2014/01/01"
}
删除索引
DELETE /website/blog/125
返回结果:
{
"_index" : "website",
"_type" : "blog",
"_id" : "125",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 11,
"_primary_term" : 1
}
在上面的结果可以返现_version增加了1,这个是ES内部记录的一部分,确保多节点间不同操作可以有正确的顺序。
冲突处理
为了处理并发出现的冲突问题可以使用一下两种方式
1.悲观并发控制 这个方式在关系型数据库中内广泛的使用,这种方式假设冲突会发生,为了解决冲突,就在读一行数据前锁定这行,然后确保值枷锁的那个线程可以修改这行数据
2.乐观并发控制
被Elasticsearch使用,这种方式假设冲突不发生,不需要区块访问,如果在读写过程发生变化,更新操作就会失败,此时我们可以在程序中决定在失败后如何解决冲突,实际上我们可以尝试更新,刷新数据或者直接反馈给用户.
文档局部更新
文档是不可变的,它们是不可以被更改的,只能被替换。update API必须遵循相同的规则。表面上看来,我们似乎是局部更新了文档的某个地方,内部却是检索-修改-重建索引的流程,这样减少了其他进程可能导致冲突的修改。
POST /website/blog/124/_update
{
"doc":{
"title":"this is test demo"
}
}
更新和冲突
在更新的时候可能有其他人在索引和修改,导致冲突,但是出现冲突不要紧,我们需要做的就是在出现冲突的时候重试,这样我们就可以结局冲突带来的问题。
POST /website/blog/124/_update?retry_on_conflict=2
{
#这里使用的是脚本修改
"script":{
"lang":"painless",
"inline":"ctx._source.title=params.title",
"params":{
"title":"Stander title"
}
}
}
更新不存在的文档
在更新文档的时候,我们如果更新了一个不存在的文档,那么我们就会更新失败,但是我们可以做到如果没有就插入一条记录,有就更新,如下面的例子
POST /website/blog/1/_update
{
"script" : "ctx._source.views+=1",
"upsert": {
"views": 1
}
}
批量查询
GET /website/blog/_mget
{
"docs":[
{"_id":"1"},
{"_id":"123"}
]
}
返回结果
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" : "1",
"_version" : 2,
"_seq_no" : 19,
"_primary_term" : 1,
"found" : true,
"_source" : {
"views" : 2
}
},
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3,
"_seq_no" : 6,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "My first blog entry",
"text" : "I am starting to get the hang of this....",
"date" : "2019/07/31"
}
}
]
}
更新是的批量操作
bulk API允许我们使用单一请求来实现多个文档的create,index,update或者delete.这个对索引列斯日志活动这样的数据六非常由于,他可以成败上千的数据作为一个批次按顺序进行索引。
bulk请求体如下,它有一点不同寻常:
{action:{metadata}}\n
{request body}\n
{action:{metadata}}\n
{request body}\n
...
1.这种格式就是使用换行符"\n"将JSON串连接起来,可以说"\n"是作为每一行的的分离标识
2.每一行不能包含换行符,他们会干扰分析
action有一下几种:
| 行为 | 解释 |
|---|---|
| create | 当文档不存在时创建 |
| index | 创建新文档或者替换已有文档 |
| update | 局部更新文档 |
| delete | 删除一个文档 |
例子:
#批量更新
POST /_bulk
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
