

前言
一直以来,或多或少,都能听到正则表达式的强大之处,但是都没有怎么去系统的学习,遇到问题的时候,直接百度一下答案,但是很显然,这样子是不行滴,所以最近开始了正则表达式的学习,也收获了很多,在此做了一些总结,也希望对大家有所帮助。
正则表达式,最核心的也是最基本的元素就是 字符,所有的正则表达式都是由一个个字符组合而成的,所以,我们首先要弄清楚字符是什么?有哪些字符?以及由于字符众多,怎么把这些字符有体系的记住?把上面这些理清楚以后,我们再结合前端实战中具体的正则表达式案例再进一步巩固上面的知识点。
字符分类
字符分为转义字符与非转义字符,这里,我个人是把是否转义作为一个分类的标准,也就是把 " 左斜杠\ " 作为一类,叫做转义字符,其他字符统一作为非转义字符,是因为转义字符确实是一个比较特殊的存在,它可以让任何字符转义,包括它自己。
我们接下来具体看一下字符的分类:
转义字符
即 左斜杠 \ 这个字符,转义的意思就是转变成其他的意思,所以 左斜杠的作用就是可以将它后面的字符转义成其他的意思,
注意:它可以将任何字符转义,包括它自己。
例如:
例1:字母n,单独使用的时候就是单纯的一个字母,但是加上转义字符之后, \n 就表示换行符
例2:字母r,单独使用的时候就是单纯的一个字母,但是加上转义字符之后, \r 就表示回车符
例3:字母\,它本身的作用就是转义字符,但是如果只是想匹配一个左斜杠呢,此时我们就需要将它本身进行转义,即\\, 此时 \\ 表示的是一个单纯的 左斜杠字符。
非转义字符
非转义字符,即除了转义字符\ 之外的所有字符。它本身可以普通字符和元字符。
1. 普通字符
我们平时所用的大小写字母,数字,标点符号等,没有特殊含义。
例如:字母a,就是一个单纯的字母,没有其他任何意思,数字也一样,只是一个数字
2. 元字符
又叫特殊字符:即有些字符是有自己的特殊含义,不是一个单纯的字符。例如^,$等位置限定符,还有{},* + 等量词限定符,
注意:其实不用单独去记所有的字符,而是要知道所有字符的一个大体分类,然后之后再根据实际场景去使用相应的字符。
常见6大结构
即一个正则表达式,都是由字面量,字符组,量词,位置,分组,分支等结构组成。
字面量字符
即只是一个单纯的具体字符,首先来一个最最简单的正则表达式:
let reg = /abc/;
let str = 'abc';
reg.test(str); // true
即我们匹配的只是一个固定字符,然后整个字符精确匹配即可,通常这种情况下,不需要我们使用正则,直接使用indexOf,或者includes方法即可解决,
字符组
那如果我们要匹配的不是一个固定的字符,如果要同时匹配多个字符呢?答案是 字符组
例如:我们判断:字符串是否包含a或者b或者c
let reg = /[abc]/ // [abc] 表示匹配a或者b或者c
let str1 = 'a';
let str2 = 'b';
let str3 = 'c';
let str4 = 'abc';
reg.test(str1);//true
reg.test(str2);//true
reg.test(str3);//true
reg.test(str4);//true
当然,如果我们要匹配的字符特别多,我们也可以使用范围表示法去匹配
例如:我们要判断:字符串是否包含a到z中的任意一个字符,这时候,如果我们还使用[abc...z] 这样列出所有字符就有点太麻烦了,解决方式 “横杠-”
- [a-z] //表示a-z中的任意一个小写字符
- [A-Z] //表示A-Z中的任意一个大写写字符
- [0-9] // 表示0到9的人一个数字
例如:我们要判断:一个字符串是否包含 数字,大小写字母以及下环线
let reg = /a-zA-Z0-9_/;
let str = '123';
reg.test(str);// true
上面的例子是否还有优化的地方呢?有的,那就是/a-zA-Z0-9_/属于正则表达式当中比较常用的表达式,所以,正则表达式针对那些比较常用的表达式,又进一步做了简写,这样更方便使用。
例如:/a-zA-Z0-9_/ 就可以用/\w/ 替换,下面还有一些其他常见简写:

通过字符这一节,我们需要知道,字符组的使用场景:即如果想要匹配多个字符的时候,就可以使用[],方括号里面的字符是一个或的关系。
还有一个场景:排除字符组,
即我们想要匹配的可以是任意字符,但是就是不能包含a,b,c。
/[^abc]/ 即该正则的含义就是我们想要匹配的字符串不能包含a或b或c。
量词
上面的字符组是对字符的内容进行限定,而量词是对字符的数量进行限定,限定这个字符串的长度,或者某个字符的重复次数等等,都会使用的量词, 首先,我们来看一下怎么表示量词?
| 符号 | 功能 | 记忆方法 |
|---|---|---|
| * | 0次或者多次 | 一般 * 就表示的是所有嘛,即0次或者多次 |
| + | 1次或者多次 | 知道 1+ 这个手机牌名称就记住了 |
| ? | 0次或者1次 | 问号一般表示有没有或者是或否,所以用0和1表示 |
| {n} | 指定n次 | |
| {n,} | 至少n次 | |
| {n, m} | 至少n次,最多m次 | |
| {, m} | 最多m次 |
接下来,我们结合几个例子看一下:
例子1: 判断输入的手机号是否符合要求?(这里我们先简单的限定手机号的长度即可)
let reg = /\d{11}/;
let phone = '13241444699';
reg.test(phone); // true
例子2: 判断用户名:只能是数字字母和下划线,且6到12位
let reg = /\w{6,12}/;
let username = 'admin';
reg.test(username); //false ,因为admin只有5位
例子3: 匹配连续出现2位到55位的数字。
var regex = /\d{2,5}/;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", index: 0, input: "123 1234 12345 123456", groups: undefined]
如果变成全局匹配呢?
var regex = /\d{2,5}/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
//["123", "1234", "12345", "12345"]
说明:这里的g是global的意思,是正则表达式其中的一个修饰符(后面会具体介绍修饰符)表示是否全局匹配,如果不是,则匹配到第一个以后,就不会再继续匹配。
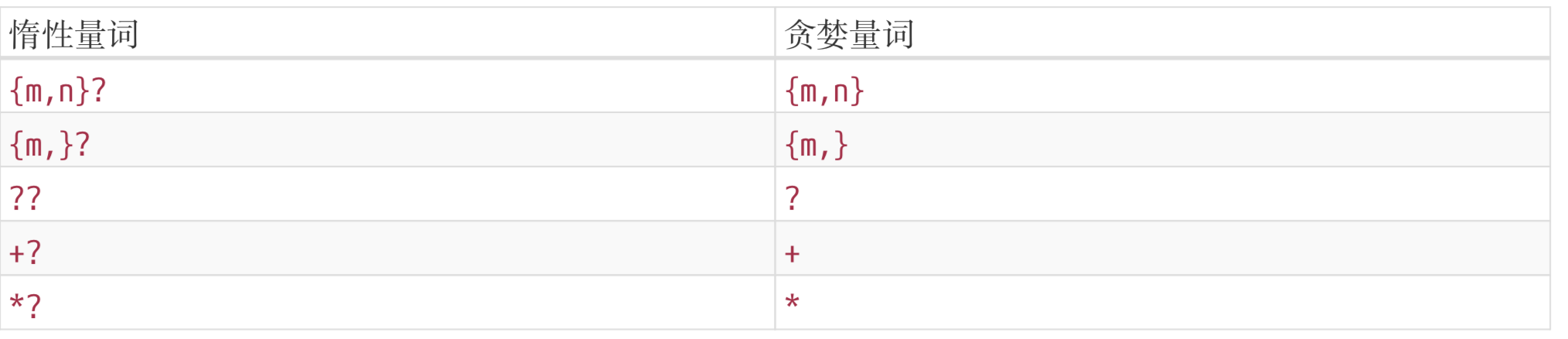
通过上面的例子发现,正则 /\d{2,5}/,表示数字连续出现 2 到 5 次。会匹配 2 位、3 位、4 位、5 位连续数字。但是其是贪婪的,它会尽可能多的匹配。你能给我 6 个,我就要 5 个。你能给我 3 个,我就要 3 个。 反正只要在能力范围内,越多越好。这种情况可以叫做 “贪婪匹配”,而与之对应的还有一个“惰性匹配”
那么?如何实现惰性匹配呢?只要在量词后面加一个?即可
var regex = /\d{2,5}?/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
//(["12", "12", "34", "12", "34", "12", "34", "56"]
所以,通过上面的例子,我们也可以把量词分为贪婪量词和惰性量词,区别就是惰性量词就是在贪婪量词的后面加了个问号?
多选分支
即采用管道符 | 去实现,其实相当于一个或的概念,
let reg = /html|css|javascript/;
let str = 'html';
reg.test(str); // true 表示只要字符串中包含html或者css或者javascript其中一个都会返回true
位置匹配
首先,我来看一下什么是位置?
图中箭头所知的就是一个个的位置,你也可以理解位一个个的空字符串。
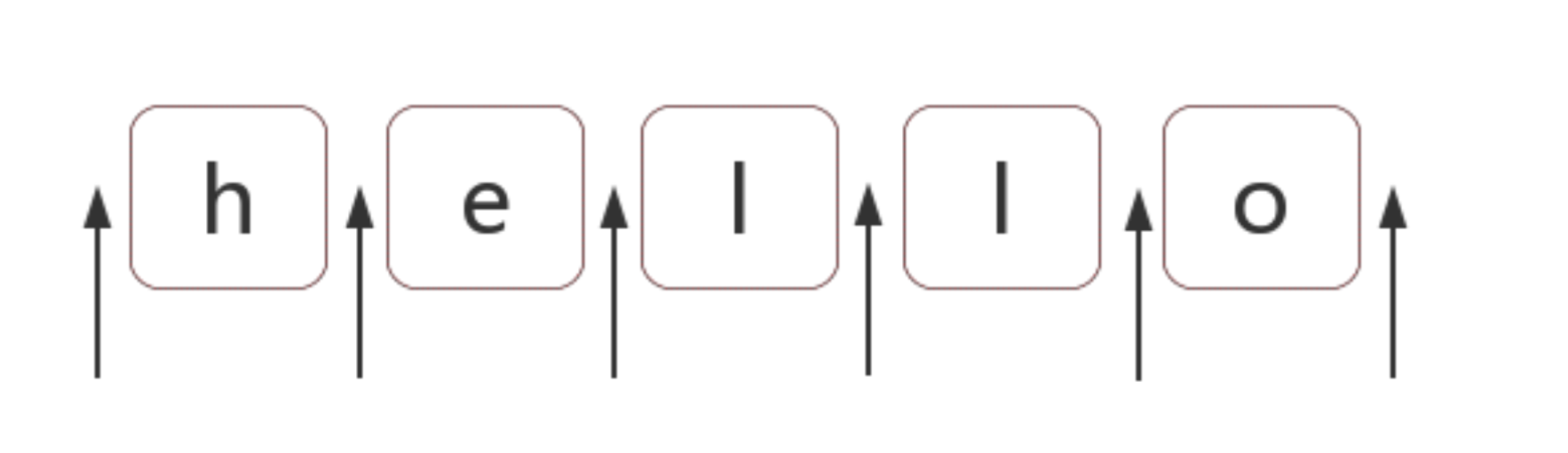
所以一个完整的表达式,不仅仅是有我们通常意义上所理解的a,b,c等字符,还包含位置字符,两个合作使用才可以构成一个完整的表达式。
下面是常见6中位置字符:
| 符号 | 功能 |
|---|---|
| ^ | 以什么开头 |
| $ | 以什么结尾 |
| \b | 匹配一个单词边界,即字与空格的位置 |
| \B | 非单词边界匹配 |
| (?=p) | 字符p前面的位置,或者当前位置后面必须是字符p |
| (?!p) | 与(?=p)相反 |
- 首先,来看一下^和$字符:用来控制开头和结尾字符是什么,通常需要完整匹配某个字符串的时候,会用到这两个字符。
例如1:
let reg = /^hello/;
let str = 'helloword';
reg.test(str) // true 表示字符串是以hello开头的
当然也可以做替换,把开头和结尾替换成自己想要的字符串
例如2:
let reg = /^|$/g;
let str = 'helloword';
str.replace(reg, '#') // #helloword#
针对于多行字符串的处理:
let reg = /^|$/g;
let str = 'helloword\nhelloword\nhelloword\nhelloword\nhelloword';
str.replace(reg, '#');
//结果为:
#helloword
helloword
helloword
helloword
helloword#
如果我们加上m多行修饰符呢?
let reg = /^|$/gm;
let str = 'helloword\nhelloword\nhelloword\nhelloword\nhelloword';
str.replace(reg, '#');
//结果为:
#helloword#
#helloword#
#helloword#
#helloword#
#helloword#
- 再来看一下\b和\B的使用:
\b是指\w与\W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置 \B是\b的反面,即除了\b匹配到的位置,剩余的位置
例如:
let str = '[JS] Lesson_01.mp4';
str.replace(/\b/g, '#'); //[#JS#] #Lesson_01#.#mp4#
str.replace(/\B/g, '#'); //#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4
- 最后,我们来看一下(?=p)和(?!p)
(?=p) 表示字母p前面的位置,或者当前位置后面的字符是p (?!p) 与(?=p) 相反,即除了(?=p)匹配的位置,剩余的位置
let str = 'helloworld';
console.log(str.replace(/(?=l)/g, '#'));//he#l#lowor#ld
console.log(str.replace(/(?!l)/g, '#'));//#h#ell#o#w#o#rl#d#
分组
首先说明一下,通过加括号的方式就可以实现分组,一个括号内的表达式就是一个子表达式,产生组以后,我们就可以引用这些组,而不需要再重复书写。
1.分组引用(捕获性分组)
即我们书写正则表达式,生成的组,我们可以在字符串中引用。
例如:yyyy-mm-dd要变成 yyyy/mm/dd的格式
let date = '2018-03-12';
方式1: 可能我们最直接想到的方法是使用replace把-替换成/
date.replace(/-/g, '/');
方式2: 采用分组引用的方式
date.replace(/(\d{4})-(\d{2})-(\d{2})/g, '$1/$2/$3')
2.反向引用
生成的分组除了在字符串中引用,我们还可以在正则表达式中引用,且只能引用前面的分组。
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
let reg = /\d{4}-|\/|\.\d{2}-|\/|\.\d{2}/
console.log(reg.test(string1));//true
console.log(reg.test(string2));//true
console.log(reg.test(string3));//true
console.log(reg.test(string4));//true
以上方法只是在每个位置都把- 或者/或者. 这三种情况用分支选择列出来,这样可以满足我们目前的需求,但是如果要求前后连接符必须一致呢?
let reg = /\d{4}(-|\/|\.)\d{2}\1\d{2}/
console.log(reg.test(string1));//true
console.log(reg.test(string2));//true
console.log(reg.test(string3));//true
console.log(reg.test(string4));//false
此时,我们可以看到string4就没有匹配成功
注意1:如果引用了一个不存在的分组,那正则会按引用字面的意思去处理
例如:
let reg = /(\d{3})\1/
let str = 123123;
console.log(reg.test(str)); // true
如果把分组去掉
let reg = /\d{3}\1/; 即此时\1表示的是一个字符\1,而不会在是分组引用的意思
let str = '123\1'
console.log(reg.test(str));
注意2:如果分组后面加量词,则引用会表示最后一次匹配到的结果
let str = '12345';
let reg1 = /\d+/;
let reg2 = /(\d)+/;
str.match(reg1);//["12345", index: 0, input: "12345"]
str.match(reg2);//["12345", "5", index: 0, input: "12345"]
3.非捕获性括号
通过前面,我们知道分组是通过小括号生成的,所以说,小括号同时有两个作用:
- 生成分组
- 设置优先级,即小括号最原始的功能,就如同js代码里表达式加括号一样
如果我们添加小括号,只是希望它发挥第二种作用,不希望它生成分组,换句话说就是让当前这个分组变成非捕获性的,方法是:(?:p)
var string = "ababa abbb ababab";
var regex1 = /(ab)+/g;
//该正则只是希望匹配一个或多个字符'ab',并没有希望把它变成一个分组,所以我们就可以这个分组变成非捕获性的。
var regex2 = /(?:ab)+/g
console.log(string.match(regex1)); //["abab", "ab", "ababab"]
console.log(string.match(regex2)); //["abab", "ab", "ababab"]
注意:我们从例子中看到,把它变成非捕获性分组以后,匹配的结果依然是一样的,那非捕获性分组有什么用呢?
提高匹配性能,因为捕获性分组和反向引用在匹配的时候,都会把匹配到结果存到内存中,这样我们在引用的时候,才可以引用匹配到的值,但是非捕获性分组,这一步就省略了,所以匹配速度会更快。
回溯
如何读正则表达式?
通过上面对正则表达式各种结构的介绍,我们知道了正则表达式的结构或者由哪些字符组成,接下来,我们只需确定这些结构的优先级,然后一步步按照优先级从高到低拆分即可。
首先,我们看一下正则表达式有哪些结构组成?


总体来说:转义字符\的优先级是最高的,然后就是大家通常意识中的括号(包括小括号和中括号),然后是中括号(即量词限定符),然后就是位置限定符,最后是用于分支的管道符|,就按照以上解释的顺序去记即可。
注意点:
- 是否需要整体匹配,这个时候就需要考虑^和$开始和结束位置字符
- 量词连续问题,即如果同时有多个量词,则一定要加括号
例如:/\d{4}+/ 如果直接这样是会报错的,必须改成/(\d{4})+/
- 元字符的转义问题,即元字符都是一些特殊字符,如果我们想用其本身的含义,就需要对元字符再次转义。
1. 对字符组[]转义: /\[34\]/ 等价于 [\[34]]
2. 对量词限定符号转义:/\{1,\3}/ 等价于 [\{1,3}]
3. 对转义字符本身转义: /\\/
例如:
let str = '[123]';
/\[123]/.test(str); //true
/\[123\]/.test(str); // true
以上我们说的都是在正则表达式中对字符进行转义,我们也可以在字符串中对字符进行转义:
let str1 = '^$';
let str2 = '\^\$';
console.log(str1 === str2); //true
js中正则表达式的四大场景
首先说一下在js使用正则表达式,最常用的6个方法
- test:用于验证和提取
- exec:用于验证和提取
- match:用于验证和提取
- search:用于验证和提取
- replace:用于替换
- split:用于拆分
1. 验证
即我们经常遇到的表单验证,用户验证输入的字符是否符合我们要求的格式。 常用的有四个方法:test与exec属于RegExp对象的方法,match和search属于String对象的方法
- reg.test(str); // 返回true或者false
- reg.exec(str); //返回第一个匹配的值
- str.match(reg); //返回第一个匹配的值
- str.search(reg); //返回第一个匹配的值的索引
例如:用户名验证,只能包含数字,字母和下划线
var username = 'abc123';
var reg = /\w/;
reg.test(username); // 结果为true
reg.exec(username); // 结果为a
username.match(reg); //结果为a
username.search(reg); //结果为0
2. 拆分
经常配合正则进行拆分的方式split方法,平时我们可以只是传入一个固定的字符,其实也可以传入正则,这样可以实现更复杂的场景下的拆分。
例如1:
var str = 'aaa,bbb,ccc';
str.split(',');// [aaa, bbb, ccc]
例如2:
var str1 = 2017/06/26;
var str2 = 2017.06.26;
var str3 = 2017-06-26;
此时,把年月日拆分成一个数组,最直接的方法就是分别指定拆分符号
str1.split('/');
str1.split('.');
str1.split('-');
但是如果我们使用正则呢?
var reg = /\D/;
str1.split(reg);
str1.split(reg);
str1.split(reg);
这样我们使用一个正则,就可以拆分多个字符串,而不用分别指定一个固定的字符。
3. 提取
即从字符串中替换出自己想要的信息,例如,一个日期2018-03-12,想要提取出它的年月日分别是什么。最常用的就是match方法
例如:
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( string.match(regex) );
结果如下:

var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
regex.test(string);
console.log( RegExp.$1, RegExp.$2, RegExp.$3 ); //"2017" "06" "26"
当然,也可以使用search, exec等方法实现,大家可以自行试一下
4. 替换
替换指定字符的场景在前端中应用是比较广泛的,例如,我们的日期显示的时候需要格式化,从后端获取到的一段文本,需要对指定单词进行高亮显示,这些场景都可以使用正则表达式来替换完成。
例如1:日期格式化
var date = '2018-04-21';
date.replace(/-/g, '/'); // 结果为 2018/04/21
例如2: 一个段落对指定文本替换成标签,并且高亮显示
var text = '你见过凌晨四点的洛杉矶吗?--- 科比';
接下来,要将 “科比” 替换成指定标签
text.replace('科比', '<span style="color:red">科比</span>')
结果如下:

例如3: 将以下字符串的大写字母高亮显示
var text = 'aaaAAAaaAABBbbCC';
str.replace(/([A-Z])/g, "<span style='color:red'>$1</span>")

注意:如果动态替换某个变量或者不是替换一个固定的值,这种情况通常都会用到 ‘分组引用’; 也就是下括号 + $
5. 常用六个方法的注意事项
- search和match方法的参数支持正则和字符串,如果是字符串,会自动转换成正则。
let str = 'index.js';
str.search('.'); // 0 ,因为会自动转换成正则,在正则中.表示除\n意外的所有字符,所以结果为0
//所以这时候需要转义以下字符串,或者直接使用正则
str.search("\\."); // 5
str.search(/\./); //5
- match 返回结果的格式,与正则对象是否有修饰符 g 有关。
//即如果使用g是全局匹配,可能会匹配到多个,如果不是g,那只会匹配到第一个
let str = 'ababab';
console.log(str.match(/a/)); // ["a", index: 0, input: "ababab"]
console.log(str.match(/a/g)); // ["a", "a", "a"]
注意点:从上面的例子,我们可以看到,如果不使用g全局匹配,可以获取到匹配值的索引,但是如果使用g,则没有索引了,解决方法是下面第三点,exec
- 当正则没有 g 时,使用 match 返回的信息比较多。但是有 g 后,就没有关键的信息 index 了, 而 exec方法就能解决这个问题,它能接着上一次匹配后继续匹配。
var regex = /a/g;
console.log( regex.test("a"), regex.lastIndex );
console.log( regex.test("aba"), regex.lastIndex );
console.log( regex.test("ababc"), regex.lastIndex );
// => true 1
// => true 3
// => false 0
- test 整体匹配时需要使用 ^ 和 $
console.log( /123/.test("a123b") ); // => true
console.log( /^123$/.test("a123b") ); // => false
console.log( /^123$/.test("123") ); // => true
- split方法支持第二个参数,表示拆分以后数组的最大长度,同时正则使用分组的时候,拆分以后的数组也是包含拆分符的。
var string = "html,css,javascript";
console.log( string.split(/,/, 2) );// =>["html", "css"]
var string = "html,css,javascript";
console.log( string.split(/(,)/) );// =>["html", ",", "css", ",", "javascript"]
7. 总结
通过本节内容的介绍,希望看过小伙伴儿可以对正则表达式有了一定的入门体验:在前端开发过程中,正则表达式可以用于:验证,拆分,提取,替换等四个常用的场景,所以在实际开发过程中,遇到这些场景,我们一定思考一下,是否可以用正则表达式去解决,这样才会真正理解正则表达式的强大之处。
在学习过程中,参考了很多大神的文章,大家也可以直接学习这些文章
juejin.cn/post/684490… juejin.cn/post/684490… juejin.cn/post/684490…
