

Socket是大部分应用层协议的基础,常见的Socket主要有两种类型:TCP和UDP,HTTP协议默认使用的是TCP类型的Socket,80端口。 为什么呢?因为TCP连接可靠,用其它协议也是允许的[1],然而,也正是因为一开始使用的是TCP连接,才使得后面的优化方案有可能被实现。
1. 最开始HTTP连接
一个服务器需要服务很多请求,这些请求如果连接以后不断开,就会有大量处于等待状态的连接需要维护,而进程、内存资源、带宽资源、文件描述符数量有上限,针对客户端与服务器端交换数据间歇性较大的特点,所以,最开始——HTTP1.0版本——将协议设计为请求时建连接、请求完释放连接,以尽快将资源释放出来服务其他客户端。[2]
造成的结果就是:早期的HTTP服务器实现方式是每一个HTTP的请求/响应过程都创建一次新的TCP连接,响应完就断开,下一个请求过来再创建一次连接。 这在当时是合理的解决方案:简单粗暴、不用管理连接、性能也比较好。
但接下来,HTTP的发展迅猛,网页中加入了越来越多的图片、表单,单个用户短时间内需要多次请求服务器上的资源,无连接已经不能满足日益增长的需求,哪怕牺牲点服务器资源来维护这个TCP连接,也比每次请求一个资源都建立一个新请求的开销要小,这个开销包括网络带宽、时间、创建、关闭连接……
2. 一条TCP连接要完成多次HTTP请求/响应过程
所以,大家试着在HTTP1.0的基础上,扩展了一个新的Header:Keep-Alive: timeout=5, max=100,发现效果不错。在HTTP1.1中,干脆直接把默认状态设置成开启,除非显式声明Connection: Close的时候才不保持开启状态。
这也就是大家经常说的长连接(Persistent Connections)了,对于客户端与服务器需要频繁传输数据的场景,长连接比较合适。
长连接开启以后有很多用法,比如HTTP Pipelining。
3. HTTP Pipelining技术
浏览器在解析完html以后,发现有三个图片需要下载,这个时候怎么用这一条随时可以双向通信的长连接来完成三个资源的获取呢? 方法一:发起第一个图片的请求,然后等待服务器返回结果,再发起第二个图片的请求……直到都获得。 方法二:发起第一个图片的请求,然后接着解析,发现需要第二个图片,就接着发第二个图片的请求(不管第一个请求有没有返回),然后等待服务器返回结果,而服务器保证:三个响应按照我三个请求的顺序返回就可以了。
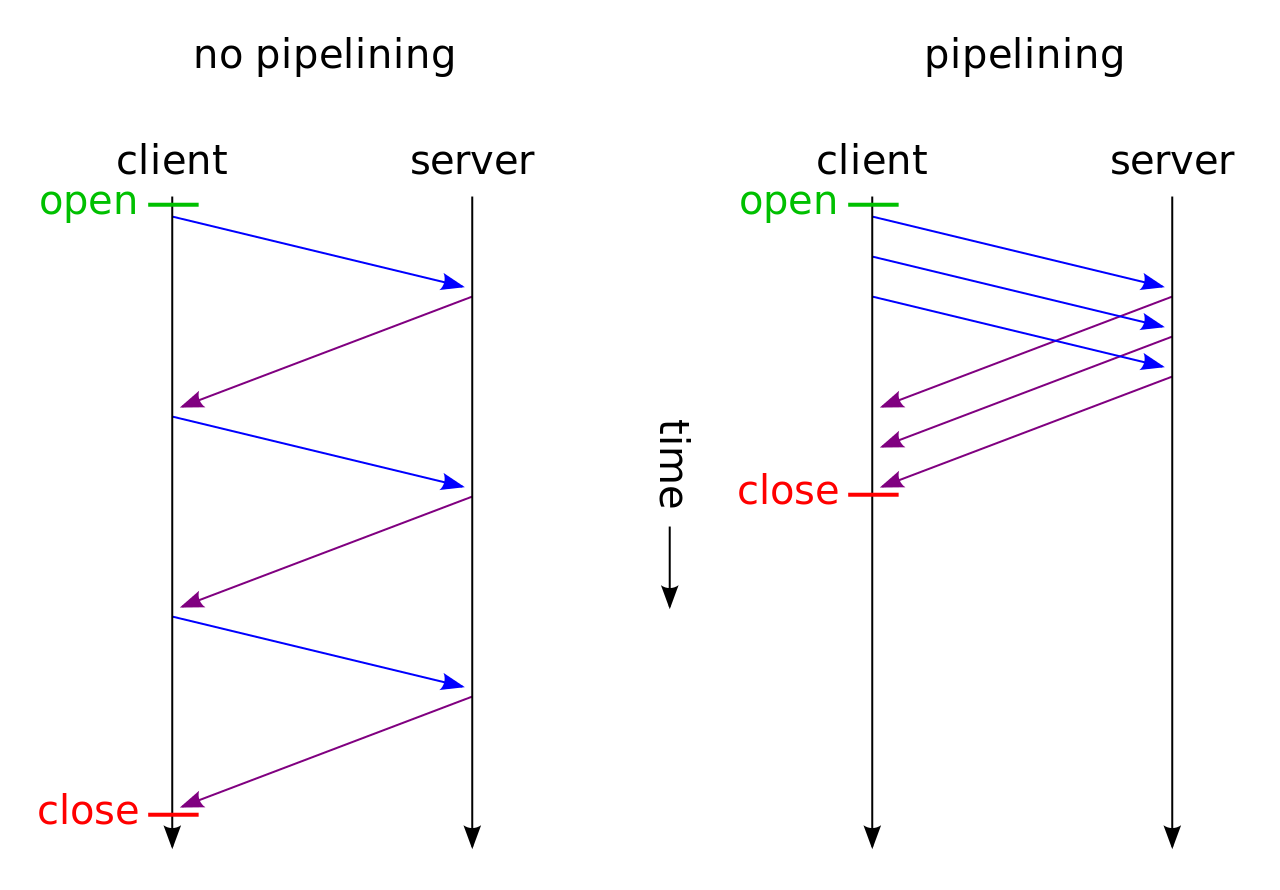
- 使用的是FIFO,容易导致Head-of-line blocking,就是:即便第二三四个请求都已经准备好了,如果第一个请求没有完成,也要等到第一个请求准备好再发送,因此实际优化效果并不明显
- 重要原因是:服务器如果开启,存在DDos风险——憋一堆拼凑起来的大请求一起发出,服务器就扛不住了
- 只能是幂等的HTTP方法——可能是因为需要重试,如果POST重试多次,造成重复提交问题
- 还有代理服务器不稳定等等 但依然有人在为此作出努力,并给出了一些解决方案,但依然不流行
4. Pipelining之外的思路
一条TCP连接虽然可以复用多次了,但对于需要并行加载的环境,Pipelining由于各种限制和缺陷也不堪重用,那索性,大家都不按规矩办事,你规范既然说:
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. 只是个SHOULD NOT,你没说MUST NOT呀,所以,我多创建几条试试,大家经过多个版本的调整,大家觉得对于同一个域,这个值设置在4-6个并发连接还比较靠谱。

5. 如何实时获得服务器上的最新消息?
5.1 轮询(polling)
轮询的问题:在没有数据更新的时候,请求无意义,关键点在于轮询时间的把握——需要综合考虑用户数量、实时行要求和服务器性能 毫无疑问,这是一个假的实时方案
5.2 comet
客户端发起一个连接,啥时候有更新啥时候返回结果,客户端等返回结果以后,立马建立一个新的连接等待返回新数据。好聪明的方案!
5.3 HTTP的chunked技术 [4]
服务器准备好一部分内容,就输出一部分内容,浏览器接收到一部分内容,就响应一部分内容 实现方法:
- 语言实现: Java、PHP: flush() Node原生: 只要没执行end,write即可输出,无需flush方法——如果真的没有输出的话,强制调用一下response.flushHeaders()应该也是可以的 Express:一般来说,框架提供了更好的封装而不具备相对低层次操作的借口,比如express的render,一次性输出了所有内容,所以貌似没有方法可以在express中分部分输出——我还没具体看源码
- XHR的支持——Firefox和Safari的支持更好,直接就支持,Chrome需要设置一个header:
X-Content-Type-Options: nosniff,我是在这个问题中得到解决方案的,另外,在curl中,如果内容结尾不加换行符号,输出结果不会被curl立马输出。 - 注意:如果存在Nginx等负载均衡设备,需要在这些服务的配置中关掉缓存逻辑或者在Header中声明不备缓存
X-Accel-Buffering: no。如果还有问题,那有可能是中间某个环节没有开启TCP的TCP_NODELAY参数。 Wireshare监听到的分段请求:
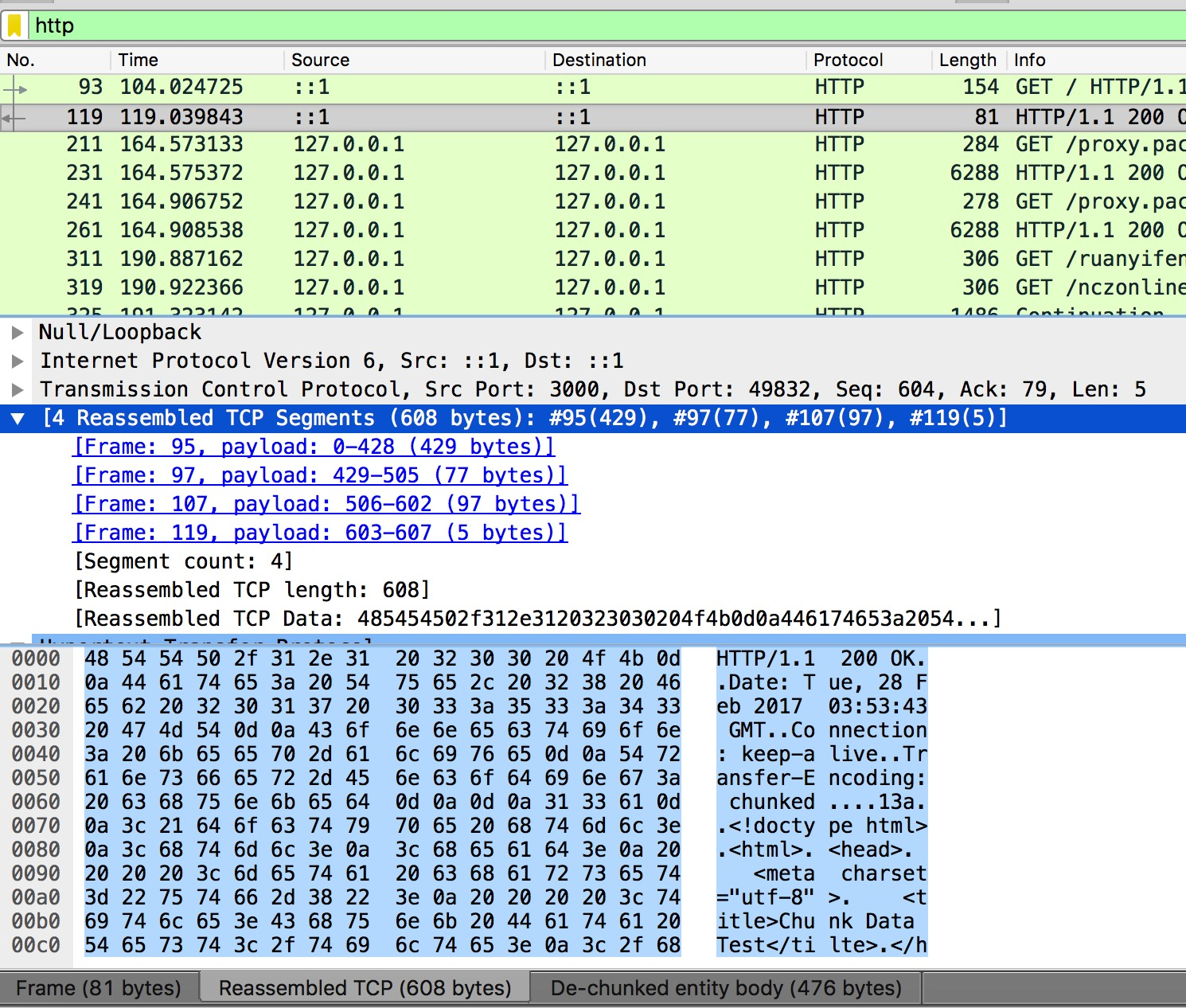
In the following example, three chunks of length 4, 5 and 14 are shown. The chunk size is transferred as a hexadecimal number followed by rn as a line separator, followed by a chunk of data of the given size.
4\r\n
Wiki\r\n
5\r\n
pedia\r\n
E\r\n
in\r\n
\r\n
chunks.\r\n
0\r\n
\r\n
解析结果:
Wikipedia in
chunks.
扩展:TCP默认开启的Nagle算法
在单一TCP链路上,短时间内需要传输多个短片段的时候,是按照下面这张图的模式来传输:
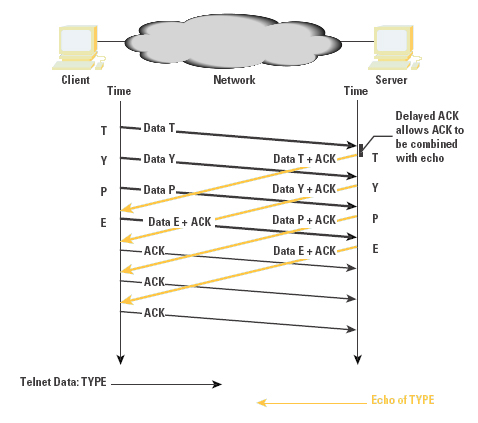
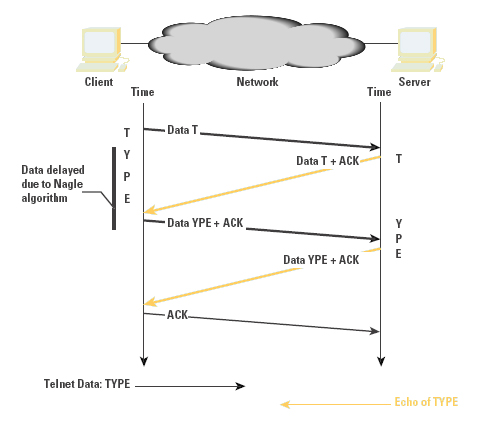
更有意思的是Nagle算法和延迟ACK两个优化条件相遇的时候,会造成明显的延迟
思考:Bigpipe是咋实现的?
原理还是chunked,在此之上封装了一些pagelet等概念,详细介绍看这里 根本上说,这是一种对HTML文件进行分段发送的实际应用。 那对JSON是不是可以用类似技术来发送呢?当然有:eBay也出了一个jsonpipe方案,主要解决了一个json在发送的时候,如果是一个标准的json,不能被直接parse的问题。 { "id": 12345, "title": "Bruce Wayne", "price": "$199.99" } \n\n { "id": 67890, "title": "Bane", "price": "$299.99" }
区分:chunked与206请求不一样
如果在DevTools中查看请求,会发现mp3文件的状态码多数时候是206,这个与分段传输有什么区别? 206的情况是:客户端和服务器要一部分数据,比如:就要一个mp3的前3MB 然后等用户播放这个音乐了,在哪一段时间,我再加载那一部分的数据,用户点到了75%的进度,我再从请求75%的位置处请求一小段。这样,就做到了分端下载。适用场景是文件下载、音乐或视频文件的在线播放等。 迅雷等多线程下载工具应用的主要就是这个特性——同时从一个文件的不同位置处请求,全部完成了,再拼成一个完整的文件。 chunked,你可以简单理解为,chunked是直播流输出,而206是点播啥看啥。
5.4 SSE
Server-Sent Events,从技术上,没有啥新东西,从标准化和API的设计层面来看,算是个进步吧。
- 传输内容是文本类型(text/event-stream, charset=utf8)
- 浏览器单向接受服务器发送
- 可以在服务器端和前端自定义事件(默认是message) 需要注意的是,这个不属于传输层面的创新,仅仅是应用层面的新协定,所以,不在RFC规范文档里面,而是由W3C来制订规范。 这里有详细描述
5.5 WebSocket简介
基于HTTP,通过升级,完成双向连接——使用的还是之前建立的TCP通道,握手完成,直接基于TCP通信。 tools.ietf.org/html/rfc645… 能够双向传输二进制流。 能够做的事情要多很多了,在此之上可以自己开发协议,也可以移植其它协议到这个链路上面来。 最常用的库就是socket.io
5.6 HTTP2.0
主要特性
- 新的二进制传输
- 消息在共享的链接上多路复用,随机发送和随机接收,如何判断?用id来区分。
- Header压缩:已经发送过的header在之后的消息中不再发送
- 可以取消某个request
- ServerPush
- 浏览器支持是HTTPS only
新变化
HTTP2.0的多路复用和ServerPush使得原来针对HTTP协议本身的一些性能优化原则,都已经不那么重要了:
- 请求不需要合并了
- 多域名部署也不用了
- 图片inline写法不需要了 另外,HTTP2.0也不是所有场景都适合的,比如说:大文件下载的情况下。
思考:有了HTTP2.0了是否不需要chunked 、SSE、WebSocket了?
先看定位: chunked是HTTP1.1协议本身的一部分,是一种应用层数据传输方式。 SSE是基于chunked技术之上的一种新约定。 WebSocket可以理解为一种新形态的Socket,能做的事情和传统Socket的基础功能差不多。 而HTTP2.0,是对HTTP1.1的复用方式的改善,是服务器和浏览器的事情,并没有对前端提供任何新的JS接口来操作这条链路和感知ServerPush等。 另外一个问题是,升级了HTTP2.0以后,原有WebSocket的操作(握手、通信的那一套,都是基于HTTP1.1来做的)就不能再使用了。基于HTTP2.0标准的WebSocket还处于比较初期的阶段。WebSocket over HTTP/2WebSocket2 over HTTP/2
