

1、redis数据结构以及常见场景:
分析:是不是觉得这个问题很基础,其实我也这么觉得。然而根据面试经验发现,至少百分八十的人答不上这个问题。建议,在项目中用到后,再类比记忆,体会更深,不要硬记。基本上,一个合格的程序员,五种类型都会用到。
回答:一共五种
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能、存储json类型对象、优酷视频点赞等
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
保存对象
分组
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适---取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
可以使用redis的list模拟队列,堆,栈
朋友圈点赞(一条朋友圈内容语句,若干点赞语句)
规定:朋友圈内容的格式:
- 内容: user:x:post:x content来存储;
- 点赞: post:x:good list来存储;(把相应头像取出来显示)
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
3.为什么redis是单线程的都那么快?
分析:这个问题其实是对redis内部机制的一个考察。其实根据博主的面试经验,很多人其实都不知道redis是单线程工作模型。所以,这个问题还是应该要复习一下的。
回答:主要是以下三点
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
题外话:我们现在要仔细的说一说I/O多路复用机制,因为这个说法实在是太通俗了,通俗到一般人都不懂是什么意思。博主打一个比方:小曲在S城开了一家快递店,负责同城快送服务。小曲因为资金限制,雇佣了一批快递员,然后小曲发现资金不够了,只够买一辆车送快递。
经营方式一
客户每送来一份快递,小曲就让一个快递员盯着,然后快递员开车去送快递。慢慢的小曲就发现了这种经营方式存在下述问题
几十个快递员基本上时间都花在了抢车上了,大部分快递员都处在闲置状态,谁抢到了车,谁就能去送快递
随着快递的增多,快递员也越来越多,小曲发现快递店里越来越挤,没办法雇佣新的快递员了
快递员之间的协调很花时间
综合上述缺点,小曲痛定思痛,提出了下面的经营方式
经营方式二
小曲只雇佣一个快递员。然后呢,客户送来的快递,小曲按送达地点标注好,然后依次放在一个地方。最后,那个快递员依次的去取快递,一次拿一个,然后开着车去送快递,送好了就回来拿下一个快递。
对比
上述两种经营方式对比,是不是明显觉得第二种,效率更高,更好呢。在上述比喻中:
每个快递员——————>每个线程
每个快递——————–>每个socket(I/O流)
快递的送达地点————–>socket的不同状态
客户送快递请求————–>来自客户端的请求
小曲的经营方式————–>服务端运行的代码
一辆车———————->CPU的核数
于是我们有如下结论
1、经营方式一就是传统的并发模型,每个I/O流(快递)都有一个新的线程(快递员)管理。
2、经营方式二就是I/O多路复用。只有单个线程(一个快递员),通过跟踪每个I/O流的状态(每个快递的送达地点),来管理多个I/O流。
下面类比到真实的redis线程模型,如图所示
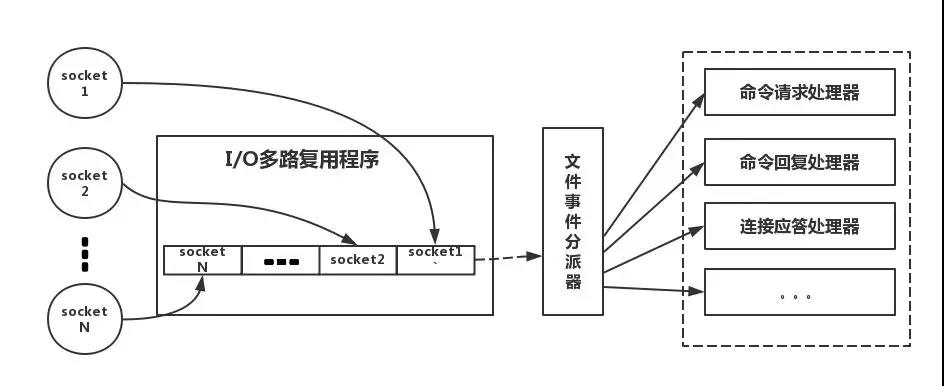
参照上图,简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
需要说明的是,这个I/O多路复用机制,redis还提供了select、epoll、evport、kqueue等多路复用函数库,大家可以自行去了解。
2、使用redis有什么缺点
分析:大家用redis这么久,这个问题是必须要了解的,基本上使用redis都会碰到一些问题,常见的也就几个。
回答:主要是四个问题
(一)缓存和数据库双写一致性问题
(二)缓存雪崩问题
(三)缓存击穿问题
(四)缓存的并发竞争问题
这四个问题,我个人是觉得在项目中,比较常遇见的,具体解决方案,后文给出。
5.redis也可以进行发布订阅消息吗?
可以,(然后可以引出哨兵模式(后面会讲)怎么互相监督的,就是因为每隔2秒哨兵节点会发布对某节点的判断和自身的信息到某频道,每个哨兵订阅该频道获取其他哨兵节点和主从节点的信息,以达到哨兵间互相监控和对主从节点的监控)和很多专业的消息队列系统(例如Kafka、RocketMQ)相比,Redis的发布订阅略显粗糙,例如无法实现消息堆积和回溯。但胜在足够简单。
6.redis能否将数据持久化,如何实现?
redis持久有两种方式:RDB快照(Redis DataBase),仅附加文件AOF(Append-only file),还有Redis 4.x AOF重写的混合模式
RDB
RDB是将当前数据生成快照保存到硬盘上。
RDB的工作流程:
1. 执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
2. 父进程执行fork操作创建子进程,fork操作过程中父进程被阻塞。
3. 父进程fork完成后,bgsave命令返回“* Background saving started by pid xxx”信息,并不再阻塞父进程,可以继续响应其他命令。
4. 父进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。根据lastsave命令可以获取最近一次生成RDB的时间,对应info Persistence中的rdb_last_save_time。
5. 进程发送信号给父进程表示完胜,父进程更新统计信息。
对于大多数操作系统来说,fork都是个重量级操作,虽然创建的子进程不需要拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表。
子进程通过fork操作产生,占用内存大小等同于父进程,理论上需要两倍的内存来完成持久化操作,但Linux有写时复制机制(copy-on-write)。父子进程会共享相同的物理内存页,当父进程处理写请求时会把要修改的页创建副本,而子进程在fork操作过程中会共享父进程的内存快照。
触发机制:
1. 手动触发
包括save和bgsave命令。
因为save会阻塞当前Redis节点,所以,Redis内部所有涉及RDB持久化的的操作都通过bgsave方式,save方式已废弃。
2. 自动触发
1> 使用save的相关配置。
2> 从节点执行全量复制操作。
3> 执行debug reload命令。
4> 执行shutdown命令时,如果没有开启AOF持久化功能则会自动执行bgsave。
RDB的优缺点:
优点:
1. RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照,适合备份,全量复制等场景。
2. 加载RDB恢复数据远远快于AOF的方式。
缺点:
没办法做到实时持久化/秒级持久化,因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
其中,前三个参数的含义是,
# #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
# #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照
# #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。满足一个就会触发。
如果要禁用RDB的自动触发,可注销这三个参数,或者设置save ""。禁止持久化,除了要设置 save "",还要把持久化的本地文件干掉!
stop-writes-on-bgsave-error:在开启RDB且最近一次bgsave执行失败的情况下,如果该参数为yes,则Redis会阻止客户端的写入,直到bgsave执行成功。
rdbcompression:使用LZF算法压缩字符对象。
rdbchecksum:从RDB V5开始,在保存RDB文件时,会在文件末尾添加CRC64校验和,这样,能较容易的判断文件是否被损坏。但同时,对于带有校验和的RDB文件的保存和加载,会有10%的性能损耗。
dbfilename: RDB文件名。
dir:RDB文件保存的目录。
RDB的相关变量
127.0.0.1:6379> info Persistence
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1538447605
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:155648
其含义如下:
loading: Flag indicating if the load of a dump file is on-going。是否在加载RDB文件
rdb_changes_since_last_save: Number of changes since the last dump。
rdb_bgsave_in_progress: Flag indicating a RDB save is on-going。是否在执行bgsave操作。
rdb_last_save_time: Epoch-based timestamp of last successful RDB save。最近一次bgsave操作时的时间戳。
rdb_last_bgsave_status: Status of the last RDB save operation。最近一次bgsave是否执行成功。
rdb_last_bgsave_time_sec: Duration of the last RDB save operation in seconds。最近一次bgsave操作花费的时间。
rdb_current_bgsave_time_sec: Duration of the on-going RDB save operation if any。当前bgsave操作已经执行的时间。
rdb_last_cow_size: The size in bytes of copy-on-write allocations during the last RBD save operation。COW的大小。指的是父进程与子进程相比执行了多少修改,包括读取缓冲区,写入缓冲区,数据修改等。
AOF
与RDB不一样的是,AOF记录的是命令,而不是数据。需要注意的是,其保存的是Redis Protocol,而不是直接的Redis命令。但是以文本格式保存。
如何开启AOF
只需将appendonly设置为yes就行。
AOF的工作流程:
1. 所有的写入命令追加到aof_buf缓冲区中。
2. AOF会根据对应的策略向磁盘做同步操作。刷盘策略由appendfsync参数决定。
3. 定期对AOF文件进行重写。重写策略由auto-aof-rewrite-percentage,auto-aof-rewrite-min-size两个参数决定。
appendfsync参数有如下取值:
no: don't fsync, just let the OS flush the data when it wants. Faster. 只调用系统write操作,不对AOF文件做fsync操作,同步硬盘操作由操作系统负责,通常同步周期最长为30s。
always: fsync after every write to the append only log. Slow, Safest. 命令写入到aof_buf后,会调用系统fsync操作同步到文件中。
everysec: fsync only one time every second. Compromise. 只调用系统write操作,fsync同步文件操作由专门进程每秒调用一次。
默认值为everysec,也是建议值。
重写条件:
1. 手动触发
直接调用bgrewriteaof命令。
2. 自动触发。
与auto-aof-rewrite-percentage,auto-aof-rewrite-min-size两个参数有关。
触发条件,aof_current_size > auto-aof-rewrite-min-size 并且 (aof_current_size - aof_base_size) / aof_base_size >= auto-aof-rewrite-percentage。
其中,aof_current_size是当前AOF文件大小,aof_base_size 是上一次重写后AOF文件的大小,这两部分的信息可从info Persistence处获取。
AOF重写的流程。(是为了避免aof文件过大,很过过期的key,以及多次修改的key,其实只需要记住内存当中某一刻的快照,再加上后面并发的增量修改即可)
1. 执行AOF重写请求。
如果当前进程正在执行bgsave操作,重写命令会等待bgsave执行完后再执行。
2. 父进程执行fork创建子进程。
3. fork操作完成后,主进程会继续响应其它命令。所有修改命令依然会写入到aof_buf中,并根据appendfsync策略持久化到AOF文件中。
4. 因fork操作运用的是写时复制技术,所以子进程只能共享fork操作时的内存数据,对于fork操作后,生成的数据,主进程会单独开辟一块aof_rewrite_buf保存。
5. 子进程根据内存快照,按照命令合并规则写入到新的AOF文件中(就是遍历内存中key的值,转换成对应的等价的命令)。每次批量写入磁盘的数据量由aof-rewrite-incremental-fsync参数控制,默认为32M,避免单次刷盘数据过多造成硬盘阻塞。
6. 新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息。
7. 父进程将aof_rewrite_buf(AOF重写缓冲区)的数据写入到新的AOF文件中。
8. 使用新AOF文件替换老文件,完成AOF重写。
实际上,当Redis节点执行完一个命令后,它会同时将这个写命令发送到AOF缓冲区和AOF重写缓冲区。
Redis通过AOF文件还原数据库的流程。
1. 创建一个不带网络连接的伪客户端。因为Redis的命令只能在客户端上下文中执行。
2. 从AOF文件中分析并读取一条命令。
3. 使用伪客户端执行该命令。
4. 反复执行步骤2,3,直到AOF文件中的所有命令都被处理完。
注意:AOF的持久化也可能会造成阻塞。
AOF常用的持久化策略是everysec,在这种策略下,fsync同步文件操作由专门线程每秒调用一次。当系统磁盘较忙时,会造成Redis主线程阻塞。
1. 主线程负责写入AOF缓冲区。
2. AOF线程负责每秒执行一次同步磁盘操作,并记录最近一次同步时间。
3. 主线程负责对比上次AOF同步时间。
1> 如果距上次同步成功时间在2s内,主线程直接返回。
2> 如果距上次同步成功时间超过2s,主线程会阻塞,直到同步操作完成。每出现一次阻塞,info Persistence中aof_delayed_fsync的值都会加1。
所以,使用everysec策略最多会丢失2s数据,而不是1s。
AOF的相关变量
127.0.0.1:6379> info Persistence
# Persistence
...
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
aof_current_size:19276803
aof_base_size:19276803
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:0
其含义如下,
aof_enabled: Flag indicating AOF logging is activated. 是否开启AOF
aof_rewrite_in_progress: Flag indicating a AOF rewrite operation is on-going. 是否在进行AOF的重写操作。
aof_rewrite_scheduled: Flag indicating an AOF rewrite operation will be scheduled once the on-going RDB save is complete. 是否有AOF操作等待执行。
aof_last_rewrite_time_sec: Duration of the last AOF rewrite operation in seconds. 最近一次AOF重写操作消耗的时间。
aof_current_rewrite_time_sec: Duration of the on-going AOF rewrite operation if any. 当前正在执行的AOF操作已经消耗的时间。
aof_last_bgrewrite_status: Status of the last AOF rewrite operation. 最近一次AOF重写操作是否执行成功。
aof_last_write_status: Status of the last write operation to the AOF. 最近一次追加操作是否执行成功。
aof_last_cow_size: The size in bytes of copy-on-write allocations during the last AOF rewrite operation. 在执行AOF重写期间,分配给COW的大小。
如果开启了AOF,还会增加以下变量
aof_current_size: AOF current file size. AOF的当前大小。
aof_base_size: AOF file size on latest startup or rewrite. 最近一次重写后AOF的大小。
aof_pending_rewrite: Flag indicating an AOF rewrite operation will be scheduled once the on-going RDB save is complete.是否有AOF操作在等待执行。
aof_buffer_length: Size of the AOF buffer. AOF buffer的大小
aof_rewrite_buffer_length: Size of the AOF rewrite buffer. AOF重写buffer的大小。
aof_pending_bio_fsync: Number of fsync pending jobs in background I/O queue. 在等待执行的fsync操作的数量。
aof_delayed_fsync: Delayed fsync counter. Fsync操作延迟执行的次数。
如果一个load操作在进行,还会增加以下变量
loading_start_time: Epoch-based timestamp of the start of the load operation. Load操作开始的时间。
loading_total_bytes: Total file size. 文件的大小。
loading_loaded_bytes: Number of bytes already loaded.已经加载的文件的大小。
loading_loaded_perc: Same value expressed as a percentage. 已经加载的比例。
loading_eta_seconds: ETA in seconds for the load to be complete. 预计多久加载完毕。
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble no
其中,
no-appendfsync-on-rewrite:在执行bgsave或bgrewriteaof操作时,不调用fsync()操作,此时,Redis的持久化策略相当于"appendfsync none"。
aof-load-truncated:在Redis节点启动的时候,如果发现AOF文件已经损坏了,其处理逻辑与该参数的设置有关,若为yes,则会忽略掉错误,尽可能加载较多的数据,若为no,则会直接报错退出。默认为yes。需要注意的是,该参数只适用于Redis启动阶段,如果在Redis运行过程中,发现AOF文件corrupted,Redis会直接报错退出。
aof-use-rdb-preamble:是否启用Redis 4.x提供的AOF+RDB的混合持久化方案,若为yes,在重写AOF文件时,Redis会将数据以RDB的格式作为AOF文件的开始部分。在重写之后,Redis会继续以AOF格式持久化写入操作。默认值为no。
7.主从复制模式下,主挂了怎么办?redis提供了哨兵模式(高可用)
何谓哨兵模式?就是通过哨兵节点进行自主监控主从节点以及其他哨兵节点,发现主节点故障时自主进行故障转移。
8.哨兵模式实现原理?(2.8版本或更高才有)
1.三个定时监控任务:
1.1 每隔10s,每个S节点(哨兵节点)会向主节点和从节点发送info命令获取最新的拓扑结构
1.2 每隔2s,每个S节点会向某频道上发送该S节点对于主节点的判断以及当前Sl节点的信息,
同时每个Sentinel节点也会订阅该频道,来了解其他S节点以及它们对主节点的判断(做客观下线依据)
1.3 每隔1s,每个S节点会向主节点、从节点、其余S节点发送一条ping命令做一次心跳检测(心跳检测机制),来确认这些节点当前是否可达
2.主客观下线:
2.1主观下线:根据第三个定时任务对没有有效回复的节点做主观下线处理
2.2客观下线:若主观下线的是主节点,会咨询其他S节点对该主节点的判断,超过半数,对该主节点做客观下线
3.选举出某一哨兵节点作为领导者,来进行故障转移。选举方式:raft算法。每个S节点有一票同意权,哪个S节点做出主观下线的时候,就会询问其他S节点是否同意其为领导者。获得半数选票的则成为领导者。基本谁先做出客观下线,谁成为领导者
4.故障转移(选举新主节点流程):
9.redis集群(采用虚拟槽方式,高可用)原理(和哨兵模式原理类似,3.0版本或以上才有)?
1.Redis集群内节点通过ping/pong消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等。因此故障发现也是通过消息传播机制实现的,主要环节包括:主观下线(pfail)和客观下线(fail)
2.主客观下线:
2.1主观下线:集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。如果通信一直失败,则发送节点会把接收节点标记为主观下线(pfail)状态。
2.2客观下线:超过半数,对该主节点做客观下线
3.主节点选举出某一主节点作为领导者,来进行故障转移。
4.故障转移(选举从节点作为新主节点)
10.redis和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
10.redis的过期策略以及内存淘汰机制
分析:这个问题其实相当重要,到底redis有没用到家,这个问题就可以看出来。比如你redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的,这个问题思考过么?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,有思考过原因么?
回答:
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置
# maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。lru指的是lru算法,volatile含义是易变的,这里指设置了过期时间的key。
11.缓存粒度控制?
12.
12.1:缓存空值存在的问题:
12.2:布隆过滤器:
布隆过滤器存在的问题:相对来说布隆过滤器搞起来代码还是比较复杂的,现阶段我们暂时还不需要,后面实在需要再考虑去做,什么阶段做什么样的事情,不是说这个系统一下子就能做的各种完美。
13.无底洞优化?
造成原因:redis分布式越来越多,导致性能反而下降,因为键值分布到更多的 节点上,所以无论是Memcache还是Redis的分布式,批量操作通常需要从不 同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作 会涉及多次网络时间。 即分布式过犹不及。
14.缓存穿透和雪崩、击穿
分析:这两个问题,说句实在话,一般中小型传统软件企业,很难碰到这个问题。如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
回答:如下所示
缓存穿透
即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
(一)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(二)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
(三)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩
即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
(一)给缓存的失效时间,加上一个随机值,避免集体失效。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
I 从缓存A读数据库,有则直接返回
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
III 更新线程同时更新缓存A和缓存B。
缓存击穿
即在缓存失效的瞬间大量请求,造成DB的压力瞬间增大解决方案:更新缓存时使用分布式锁锁住服务,防止请求穿透直达DB
15.热点key优化
当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
分析:这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什么呢?大家思考过么。需要说明一下,博主提前百度了一下,发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
回答:如下所示
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
