

Zookeeper是可以存储数据的,所以我们可以把它理解一个数据库,实际上它的底层原理本身也和数据库是类似的。
一、数据库的原理
我们知道,数据库是用来存储数据的,只是数据可以存储在内存中或磁盘中。而Zookeeper实际是结合了这两种的,Zookeeper中的数据即会存储在磁盘中以达到持久化的目的,也会同步到内存中以到达快速访问的目的。
事实上,用过Zookeeper的同学应该知道,Zookeeper中有两种类型的节点:持久化节点和临时节点。
持久化节点:会持久化在磁盘中,除非主动删除,将一直存在。
临时节点:不会持久化在磁盘中,只会存储在内存中,创建这个临时节点的Session一旦过期,此临时节点也将自动被删除。
二、数据库处理数据的原理
作为一个数据库,肯定是要接收客户端创建、修改、删除、查询节点等请求的。
在Zookeeper中对于请求分为两类:
事务性请求
非事务性请求
1、事务性请求
Zookeeper通常都是以集群模式运行的,也就是Zookeeper集群中各个节点的数据需要保持一致的。但是和Mysql集群不一样的是:
Mysql集群中,从服务器是异步从主服务器同步数据的,这中间的间隔时间可以比较长。
Zookeeper集群中,当某一个集群节点接收到一个写请求操作时,该节点需要将这个写请求操作发送给其他节点,以使其他节点同步执行这个写请求操作,从而达到各个节点上的数据保持一致,也就是数据一致性。我们通常说Zookeeper保证CAP理论中的CP就只这个意思。
Zookeeper集群底层是怎么保证数据一致性的,其实是用的两阶段提交+过半机制来保证的。
事务性请求包括:更新操作、新增操作、删除操作,结合上面的分析,因为这些操作是会影响数据的,所以要保证这些操作在整个集群内的事务性,所以这些操作就是事务性请求。
2、非事务性请求
那么非事务性请求就好理解的,像查询操作、exist操作这些不影响数据的操场,就不需要集群来保持事务性,所以这些操场就是非事务性请求。
Zookeeper在处理事务性请求时,比处理非事务性请求要复杂很多
三、数据在磁盘中的表示
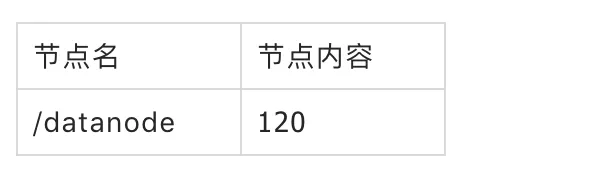
假设我们现在在Zookeeper中有一个数据节点,节点名为/datanode,内容为125,该节点是持久化节点,所以该节点信息会保存在文件中。
可能大家都会认为是类似下面这样方式保存在磁盘文件中的,方法一:

但是除开这种表示方法,还有另外一种表示方法,快照+事务日志,比如方法二:
当前快照:
当前事务日志:
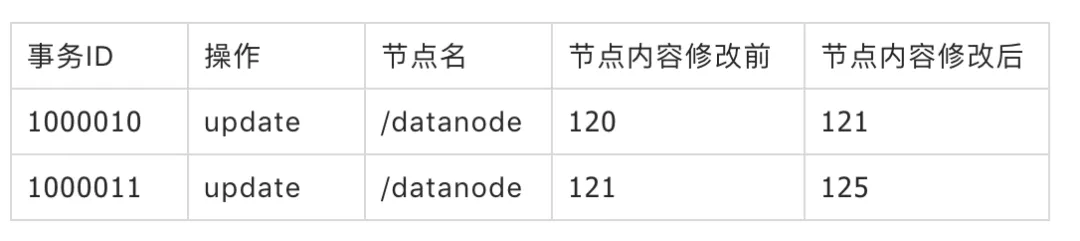
乍一看方法二比方法一要更复杂,并且占用的磁盘更多。但是我们上文提到过,Zookeeper集群中的节点在处理事务性请求时,需要将事务操作同步给其他节点,所以这里的事务操作是一定要进行持久化的,以便在同步给其他节点时出现异常进行补偿。所以就出现了事务日志。实际上事务日志还运行数据进行回滚,这个在两阶段提交中也是非常重要的。
那么快照又有什么用呢?事务日志一定要有,但是随着时间的推移,日志肯定会越来越多,所以肯定不能持久化历史上所有的日志,所以Zookeeper会定时的进行快照,并删除之前的日志。
那么如果按方法二这么存储数据,在对数据进行查询时就不太方便了。上文说到,Zookeeper为了提高数据的查询速度,会在内存中也存储一份数据,那么内存中的这份数据又该怎么存呢?
四、数据在内存中的表示
Zookeeper中的数据在内存中的表示其实和上文的方法一很类似,只是Zookeeper中的数据是具有文件目录特点的,说白了就是Zookeeper中的数据节点的名字一定要以“/”开头,这样就导致Zookeeper中的数据类似一颗树:

一颗具有父子层级的多叉树,在Zookeeper源码中叫DataTree。
五、请求处理逻辑
请看下图:

请注意,对于上图,Zookeeper真正的底层实现,zk1是Leader,zk2和zk3是Learner,是根据领导者选举选出来的。
非事务性请求直接读取DataTree上的内容,DataTree是在内存中的,所以会非常快。
六、总结
这篇文章介绍了Zookeeper在处理请求时的几个核心概念:
1、事务性请求
2、事务日志
3、快照
4、DataTree
5、两阶段提交
