作业回顾
- 爬取分类下的图书名和对应价格, 保存到books.txt
- books.toscrape.com
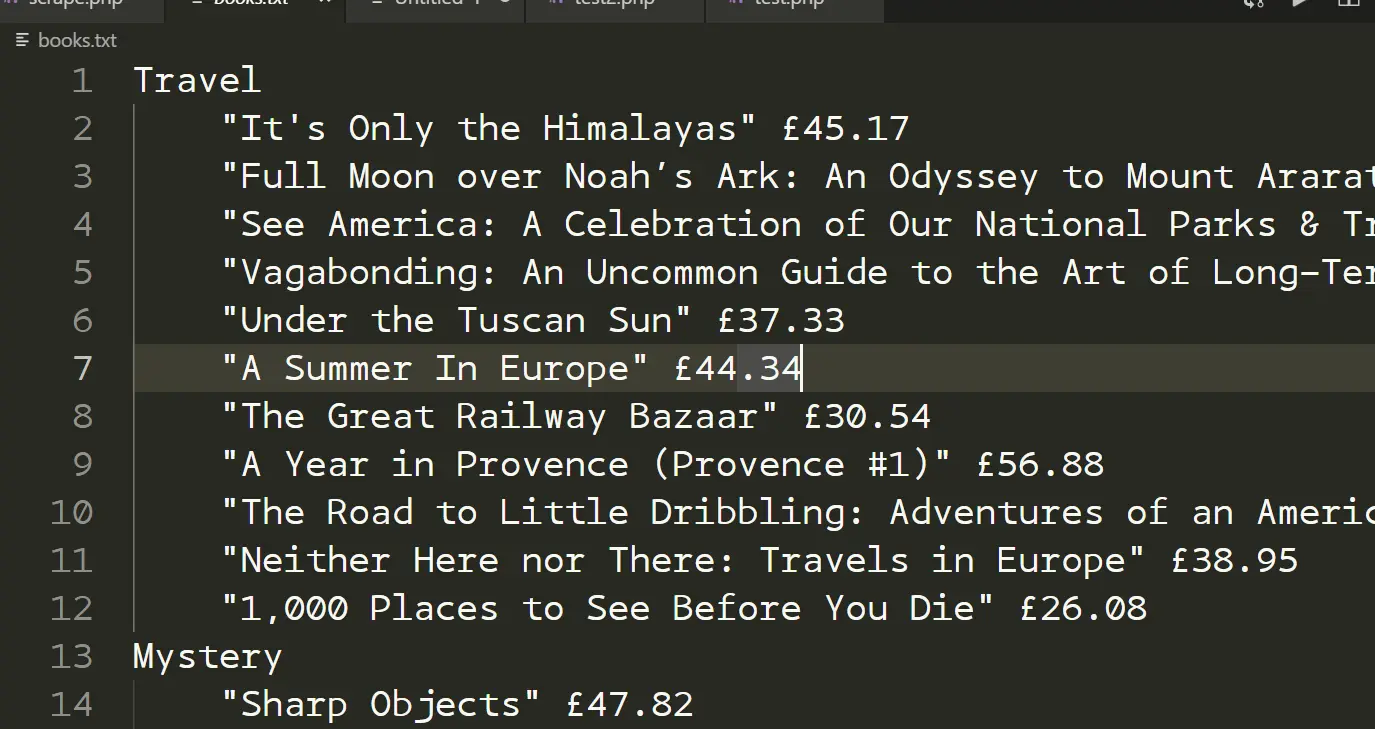
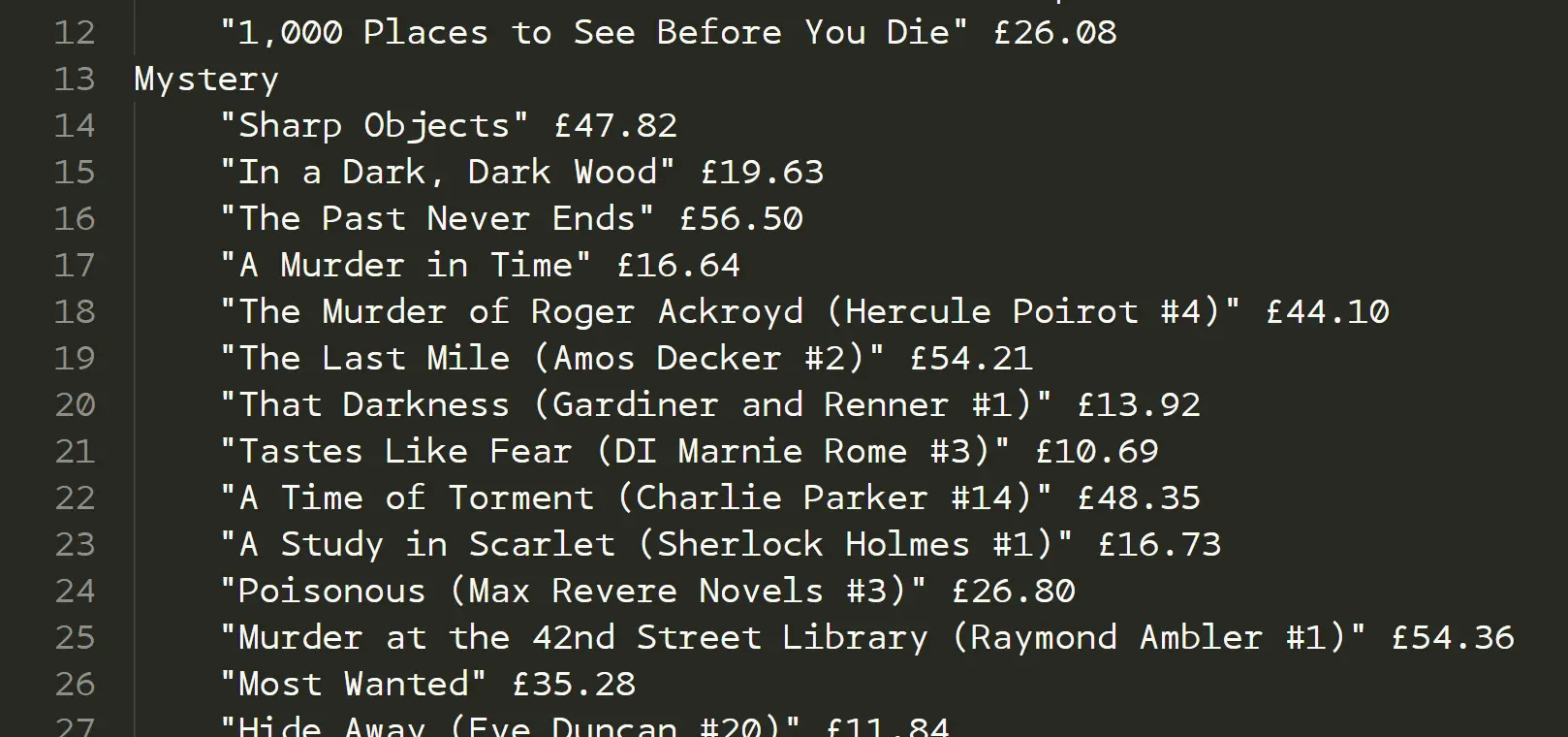
- 最终效果...

作业解析
- 两个难度
- 简单难度
- 爬取分类和分类下的第一页的数据, 不包括分页
- 所需要的知识已经讲过, 不需要额外的知识
- 中等难度
- 爬取分类和分类下的所有数据, 需要判断总页数
- 需要额外的知识, 字符串切割/截取
作业分析
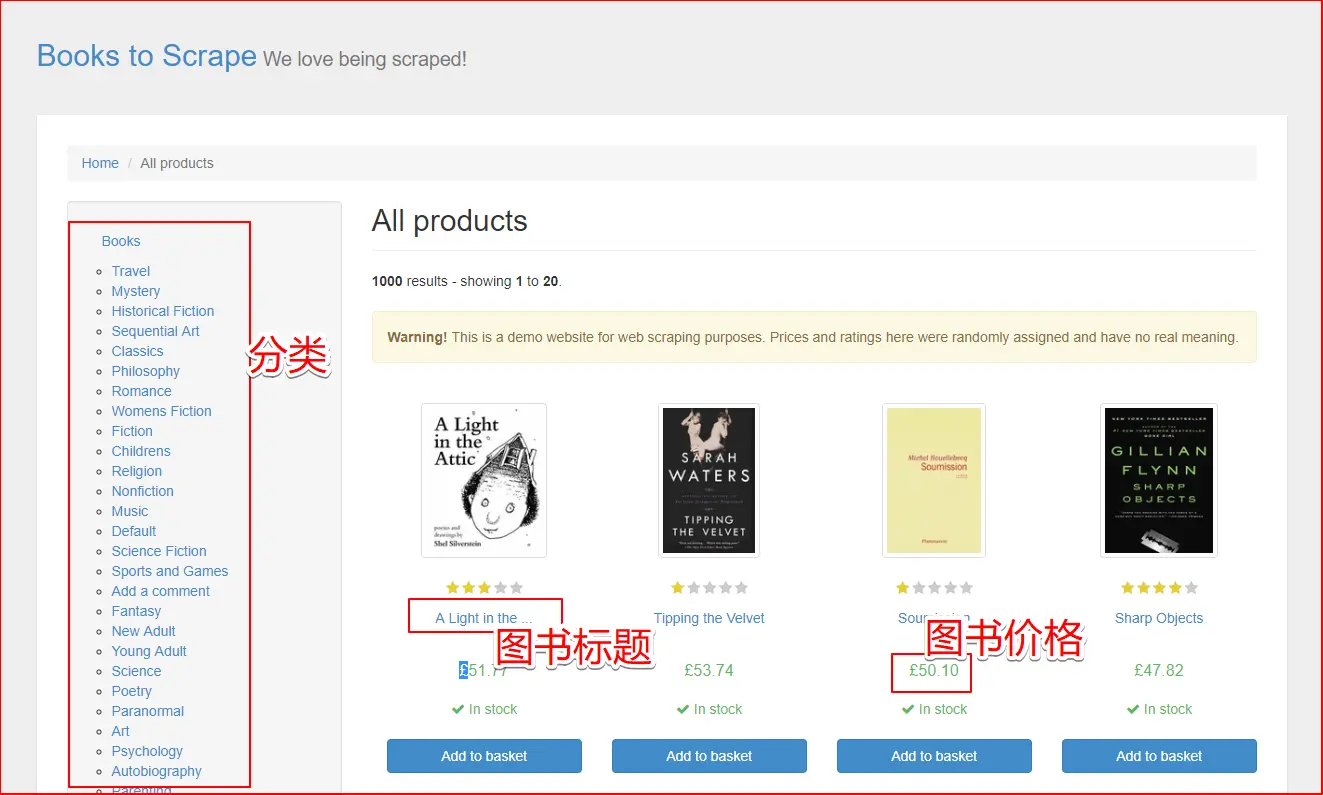
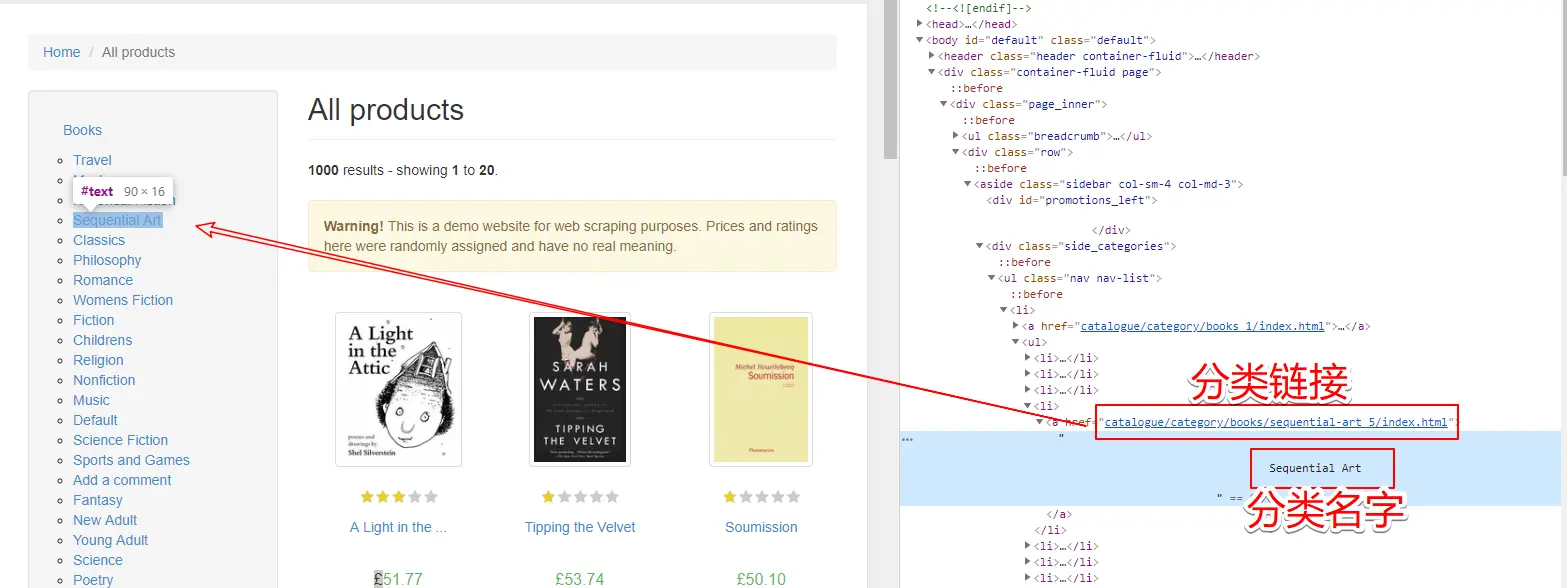
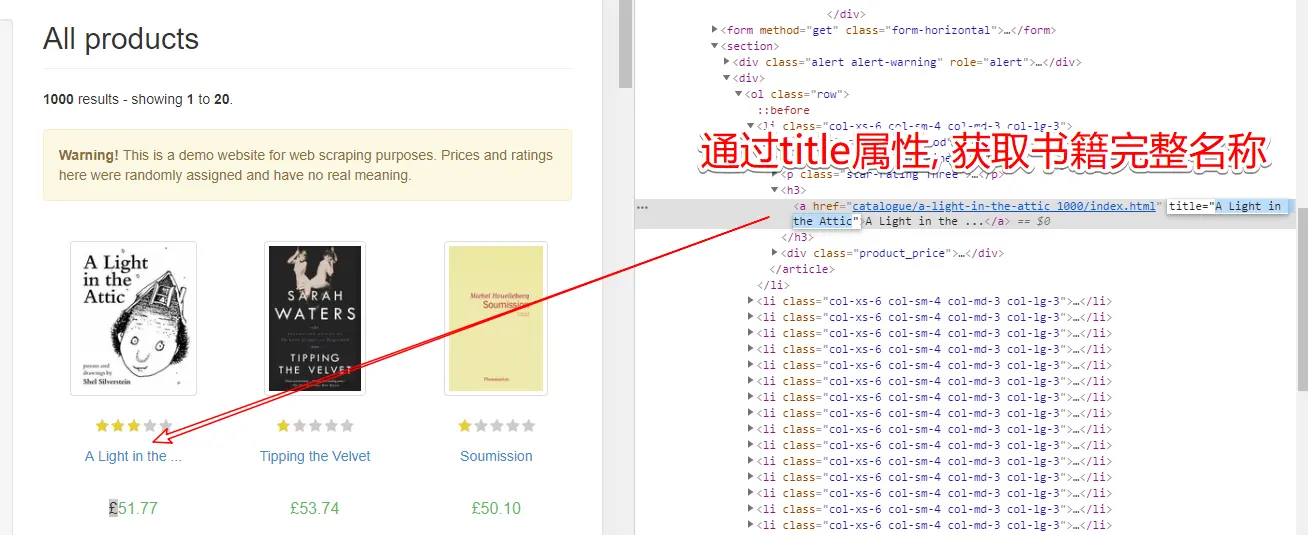
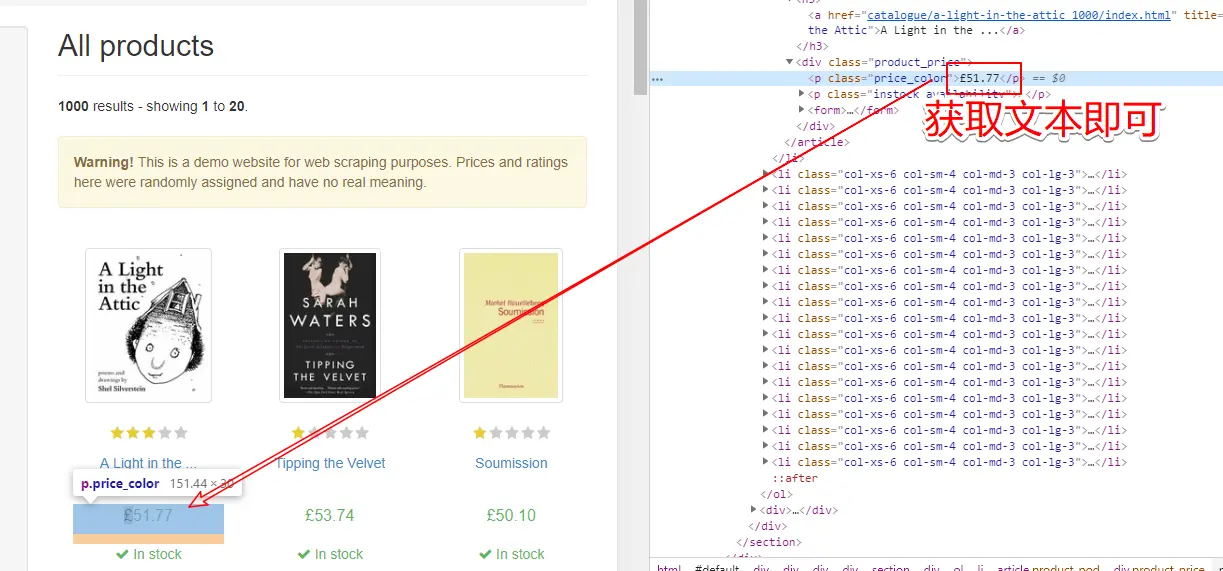
- 先获取分类的名称和url
- 再通过url获取分类下的图书信息
- 注意分类的url需要拼接
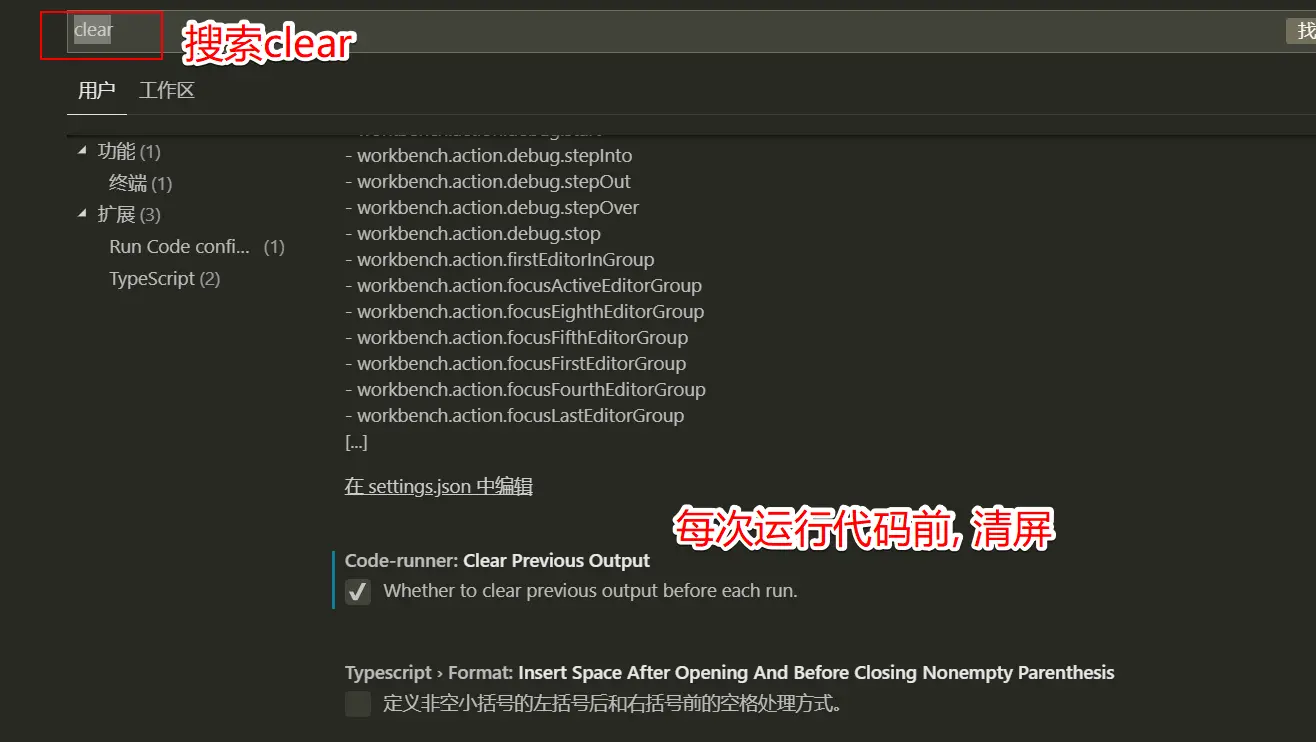
小彩蛋: 运行前清屏
代码解析-简单难度-带注释
<?php
require 'vendor/autoload.php';
use QL\QueryList;
$ql = new QueryList();
function get_category($url)
{
global $ql;
$data = $ql->get($url)->rules([
"category_name" => ['#default > div > div > div > aside > div.side_categories > ul > li > ul > li > a', 'text'],
"category_url" => ['#default > div > div > div > aside > div.side_categories > ul > li > ul > li > a', 'href'],
])->queryData();
foreach ($data as $key => $value) {
$value['category_url'] = $url . $value['category_url'];
$data[$key] = $value;
}
return $data;
}
function get_book($url)
{
global $ql;
$data = $ql->get($url)->rules([
"book_name" => ['#default > div > div > div > div > section > div:nth-child(2) > ol > li > article > h3 > a', 'title'],
"book_price" => ['#default > div > div > div > div > section > div:nth-child(2) > ol > li> article > div.product_price > p.price_color', 'text'],
])->queryData();
return $data;
}
function make_array($data)
{
foreach ($data as $key => $value) {
echo $value['category_url']."\n";
$value['books'] = get_book($value['category_url']);
$data[$key] = $value;
}
return $data;
}
function make_txt($data)
{
$txt_obj = fopen('books.txt', 'w+');
foreach ($data as $key => $value) {
$category_name = $value['category_name'];
fwrite($txt_obj, "{$category_name}\n");
foreach ($value['books'] as $k => $book) {
$book_name = $book['book_name'];
$book_price = $book['book_price'];
fwrite($txt_obj, "\t\"{$book_name}\" {$book_price}\n");
}
}
fclose($txt_obj);
}
$data = make_array(get_category('http://books.toscrape.com/'));
make_txt($data);
代码解析-中等难度-带注释
<?php
require 'vendor/autoload.php';
use QL\QueryList;
$ql = new QueryList();
function get_category($url)
{
global $ql;
$data = $ql->get($url)->rules([
"category_name" => ['#default > div > div > div > aside > div.side_categories > ul > li > ul > li > a', 'text'],
"category_url" => ['#default > div > div > div > aside > div.side_categories > ul > li > ul > li > a', 'href'],
])->queryData();
foreach ($data as $key => $value) {
$value['category_url'] = $url . $value['category_url'];
$data[$key] = $value;
}
return $data;
}
function get_book($url)
{
global $ql;
echo $url."\n";
$data = $ql->get($url)->rules([
"book_name" => ['#default > div > div > div > div > section > div:nth-child(2) > ol > li > article > h3 > a', 'title'],
"book_price" => ['#default > div > div > div > div > section > div:nth-child(2) > ol > li> article > div.product_price > p.price_color', 'text'],
])->queryData();
$next = has_next($url);
if($next){
$tmp_arr = explode('/',$url);
$tmp_arr[count($tmp_arr)-1] = $next;
$next_url = implode('/',$tmp_arr);
$data = array_merge($data,get_book($next_url));
}
return $data;
}
function has_next($url){
global $ql;
$res = $ql->get($url)->find('#default > div > div > div > div > section > div:nth-child(2) > div > ul > li.next > a')->href;
return $res;
}
function make_array($data)
{
foreach ($data as $key => $value) {
echo $value['category_url']."\n";
$value['books'] = get_book($value['category_url']);
$data[$key] = $value;
}
return $data;
}
function make_txt($data)
{
$txt_obj = fopen('books.txt', 'w+');
foreach ($data as $key => $value) {
$category_name = $value['category_name'];
fwrite($txt_obj, "{$category_name}\n");
foreach ($value['books'] as $k => $book) {
$book_name = $book['book_name'];
$book_price = $book['book_price'];
fwrite($txt_obj, "\t\"{$book_name}\" {$book_price}\n");
}
}
fclose($txt_obj);
}
$data = make_array(get_category('http://books.toscrape.com/'));
make_txt($data);
下一节


