

凶案现场:
公元20几几年的某一天,笔者正在公司悠闲地啃着早餐,手机突然传来一个应用告警!!!打开一看: 应用老年代内存使用率超过95% 几个大字赫然映入眼帘,吓得笔者赶紧丢下了手中的肉包子,赶紧排查!
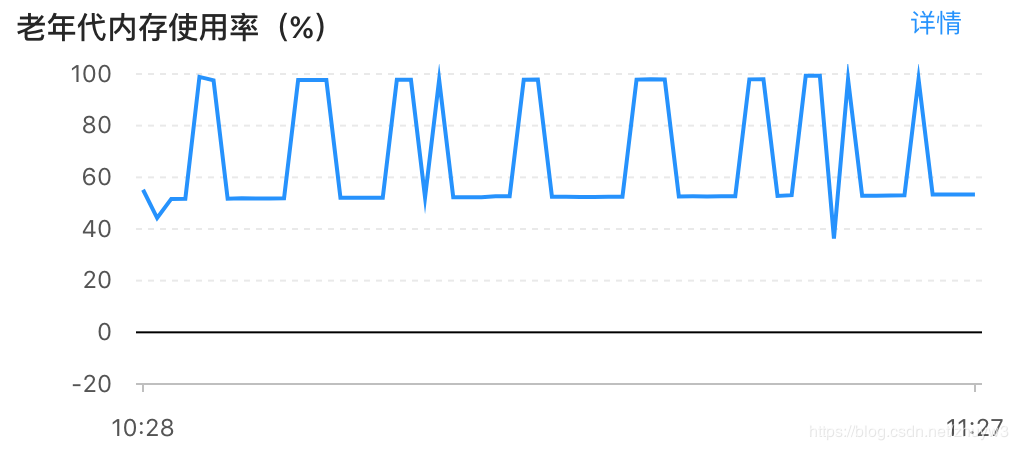
下图是后面解决了问题后从应用监控中补拍的作案证据,明显看到在一段时间内应用的老年代在频繁进行着full gc,且内存高点一直在100%处徘徊。
缉凶过程:
咳咳,作为一个成熟的java攻城狮,在面对着oom这种小毛贼时,笔者自然是保持着一脸淡定(其实内心慌得一批,毕竟当时刚入职没两天,怎么就接了这么个锅)。
当时第一反应是先咨询了运维同事,发现监控平台上并没有集成内存分析的工具,需要自行dump分析。既然如此,那只能硬着头皮上了,笔者二话不说接入跳板机,登录生产环境,一招 jps 找到当前java应用的进程pid,又一招 jmap -dump:format=b,file=filename pid , 心里想着等老子拿到dump文件,一定好好修理你个凶手。时间漫长地过去了 ~~~ 10分钟,终于拿到了dump文件(此处省略各种与生产环境文件导出的斗智斗勇)。
笔者迫不及待拿出左右两柄手术刀(java自带的 visualvm 与一个比较有名的外部分析软件 mat),准备对dump文件进行尸检。毕竟第一次使刀,握着刀柄一时半会儿不知如何下手,真是丢我攻城狮的脸!折腾了半天,终于打开了 mat,载入了dump文件。(mac使用mat有时可能遇到启动失败的坑,此处不作赘述,请自行 度娘/google)
划开尸体的第一刀,映入眼帘的是血淋淋的内脏布局,如下图:
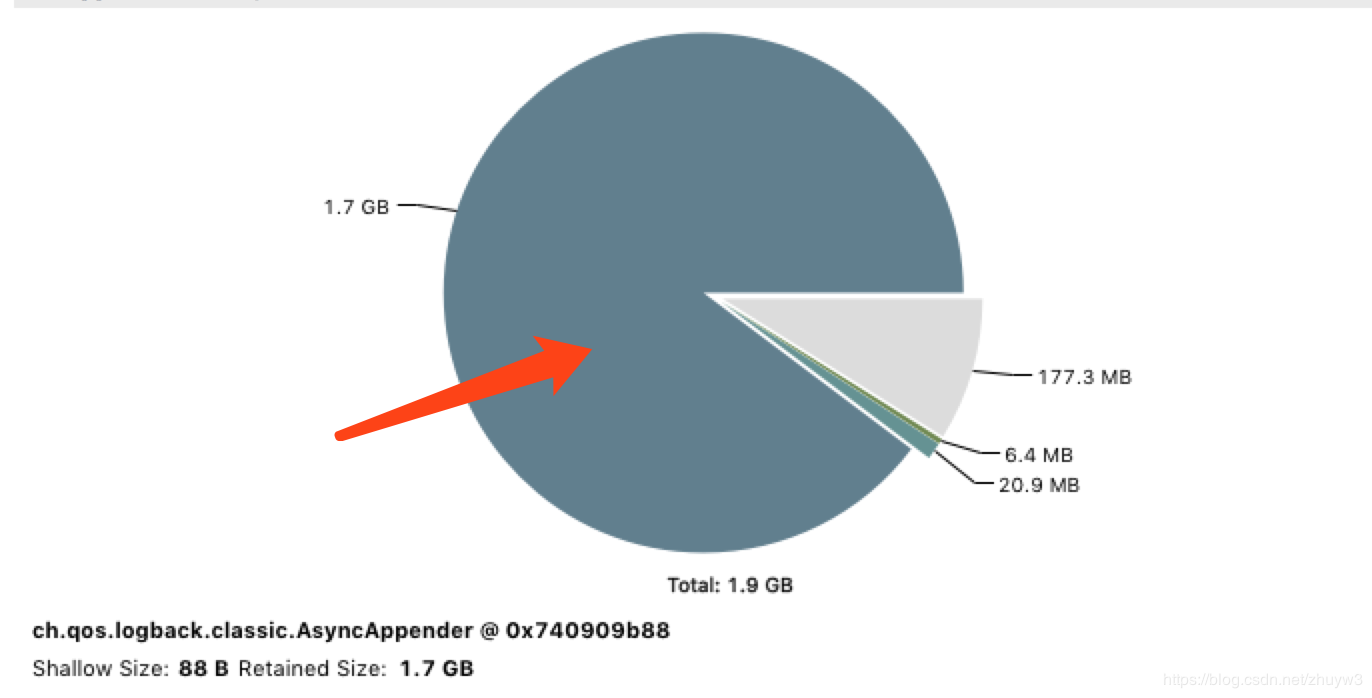
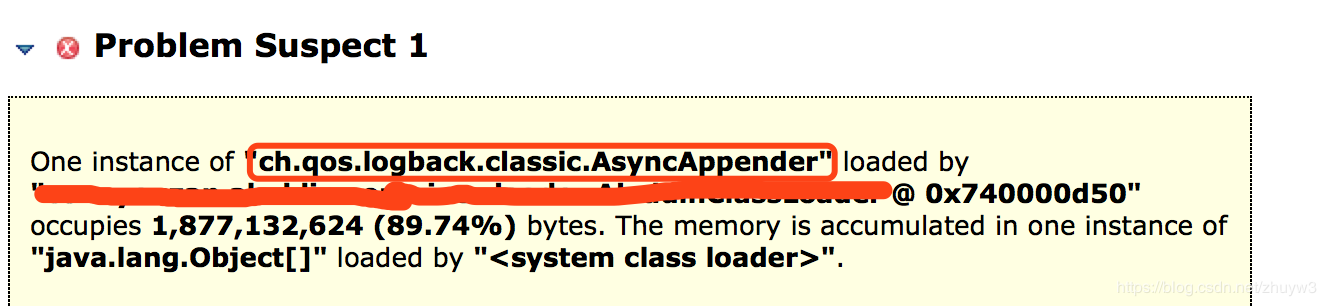
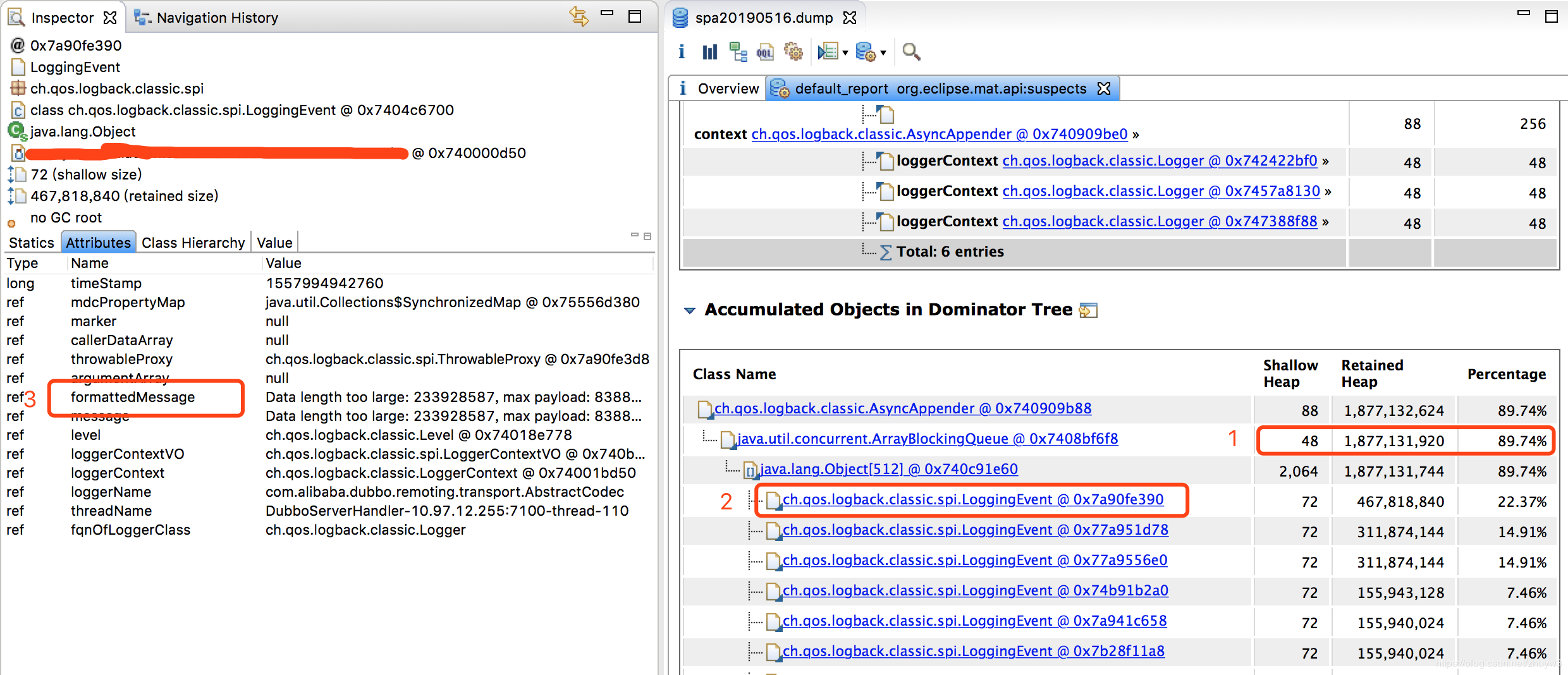
拉到accumulate objects in dominator tree项,它为我们列出了这个asyncAppender对象的内存结构。果然如我们所料,logback框架会使用一个队列来缓存一个个loggingEvent对象,每一次调用日志输出都会被包装成一个loggingEvent缓存起来。从上图第一、二点我们看到这个日志缓存队列占据了十分巨大的内存,并且他的loggingEvent对象光一个就占了23%左右的内存,我的天。上图第三点的inspector观察窗口能展示出这个对象的具体内容,于是我们截取了前两个占比最大的loggingEvent对象的msg来看看这个日志的内容到底是啥?
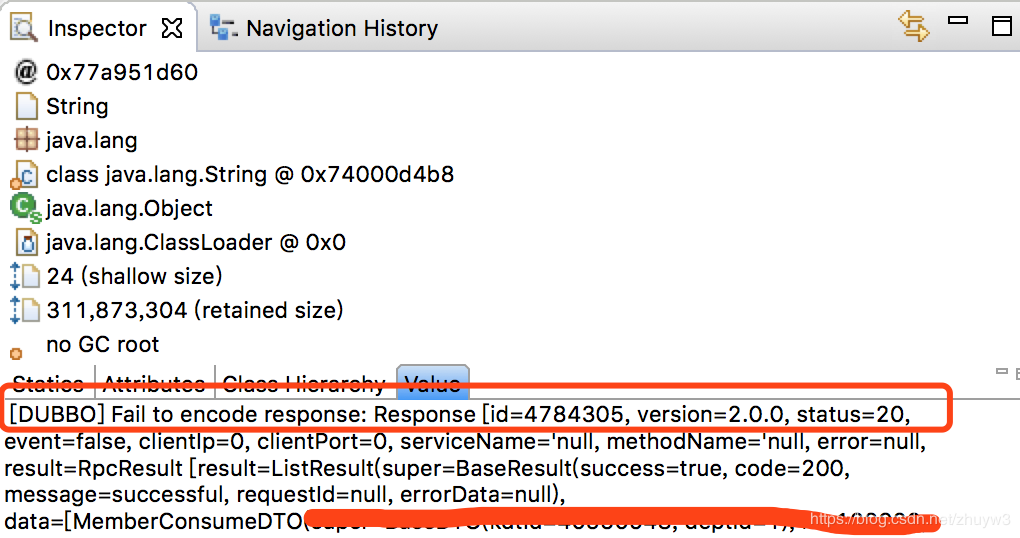
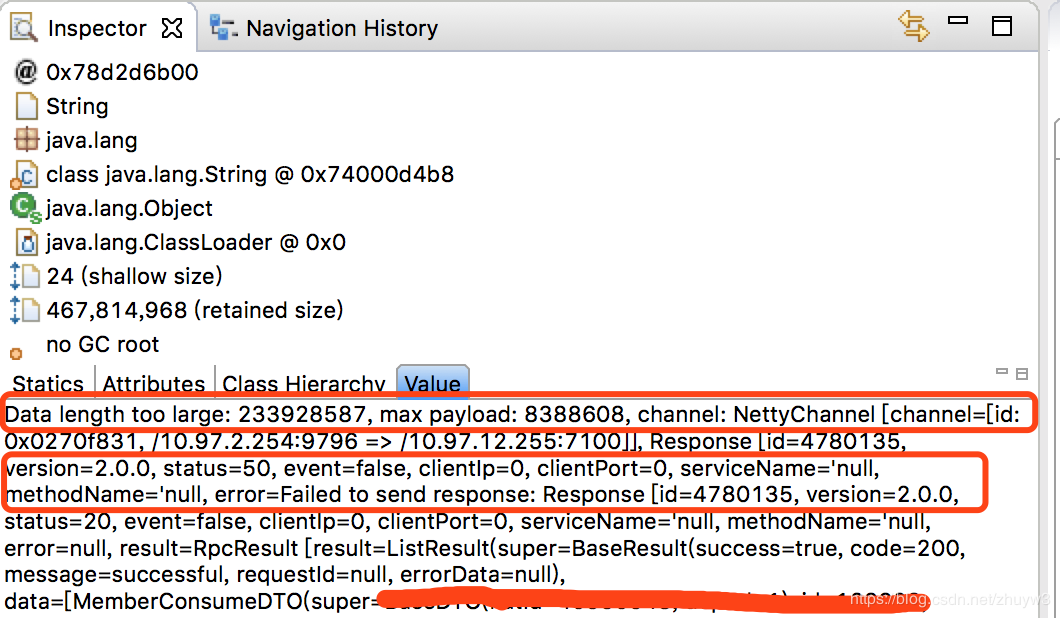
结案:
区区oom果然没能逃过笔者的法眼,案件最后定性原因如下:由于sql的设计错误导致批量查询数据量巨大,超过了dubbo的传输限制,因而抛出异常并写日志。而日志对象中包含了巨量的查询返回对象具体信息,并丢进异步日志队列,日志还没来得及刷新到磁盘就已经撑爆了内存,oom发生告警!! 后续优化的时候除了修改sql,优化了批量查询的条件,同时还在logback配置上加入了日志最大长度的限制,杜绝因日志打印导致的oom再次发生。
