


各大音乐软件都有自己的排行榜,大多数通过播放量、分享、下载等进行计算排名,那么热门歌曲是不是有一定的规律?是旋律优美,还是歌词感人?我们看下Dorien是如何利用数据科学从不一样的角度——音频属性预测热门歌曲的。
正文
算法可以预测热门歌曲吗?让我们来探索如何使用音频特征构建热门歌曲分类器,正如我的文章Dance Hit Song Prediction所述(文末有链接)。
在我的博士研究期间,我看到了Pachet&Roi(2008)的一篇题为“热门歌曲科学还不是一门科学”的论文。我觉得很有趣,这使我开始探索是否可以预测热门歌曲。关于这个主题的研究非常有限,更完整的文献综述,请参阅Dance Hit Song Prediction(2014年)。我们觉得该模型的有效性可以通过专注于一个特定的流派来优化:舞曲。这对我来说是很直观的,因为不同的音乐类型的热门歌曲有着不同的特点。
数据集
为了进行热门歌曲预测,我们首先需要一个热门歌曲/非热门歌曲的数据集。热门歌曲的列表是很好找的,但不热门歌曲的列表却很难找。因此,我们决定改为对热门列表中的高排名和低排名歌曲进行分类。我们进行了一些实验来看哪种分割效果最好,如表1所示,这产生了三个数据集(D1,D2和D3):
 表1 - 来自Herremans等人的热门数据集(2014年)
表1 - 来自Herremans等人的热门数据集(2014年)
每个数据集类的分布都有略微的不平衡:
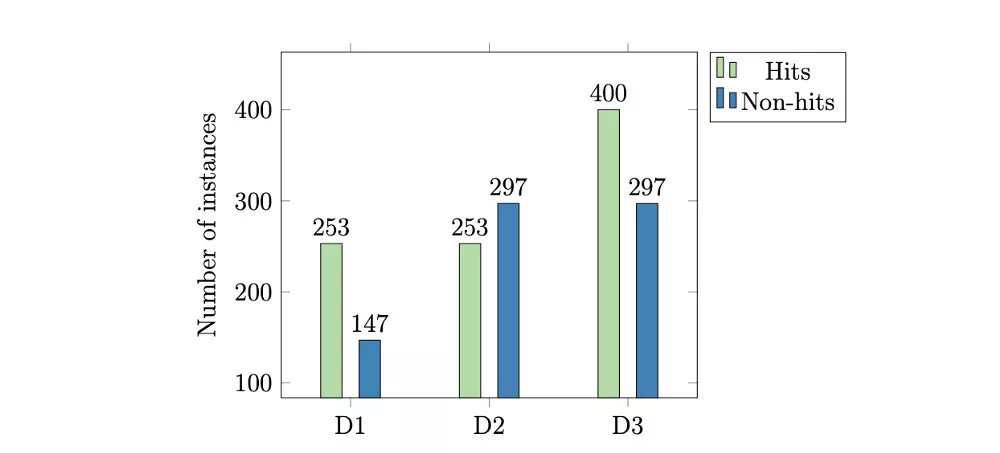 图1 - Herremans等人的类分布(2014年)
图1 - Herremans等人的类分布(2014年)
热门歌曲列表的两个来源是:Billboard(BB)和Original Charts Company(OCC)。下表显示了收集的热门歌曲数量。请注意,歌曲会在排行榜停留数周,因此独特歌曲的数量要小得多:
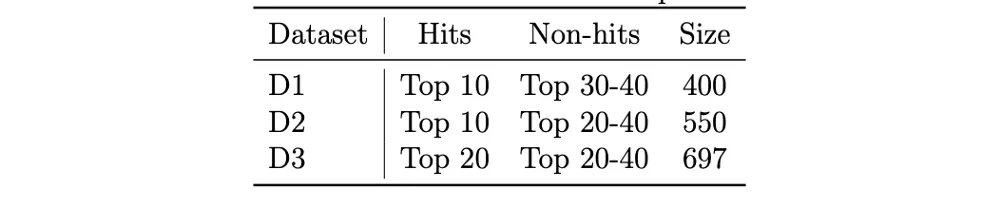 表2 - 来自Herremans等人的热门数据集(2014年)
表2 - 来自Herremans等人的热门数据集(2014年)
现在我们有了一个歌曲列表,还需要它们的音频特征。我们使用The EchoNest Analyzer(Jehan和DesRoches,2012)来提取一些音频特征。这个漂亮的API允许我们根据艺术家姓名和歌曲标题获得许多音频特征(Echo Nest由Spotify收购,现已集成到Spotify API中)。看看我们提取了什么:
标准音频功能
包括持续时间,速度,时间戳,模式(主要(1)或次要(0)),Key,响度,可舞蹈性(由回声巢计算,基于节拍强度,节奏稳定性,整体节奏等等,能量(由回声巢计算,基于响度和段持续时间)。
新的时间特征
由于歌曲随时间而变化,我们根据Schindler&Rauber(2012)添加了许多时间上聚合的特征。它们包括~1s段的平均值,方差,最小值,最大值,范围和80百分位数。这是为了以下特征:
- Timbre:音频音调色的PCA基向量(13维)。一种13维的矢量,它捕获歌曲每一段的音调颜色。
- 节拍差异:节拍之间的时间。
好哒!现在我们有一个很好的音频特征集合,以及他们的顶部图表位置。像任何一个好的数据科学项目应该开始一样,让我们做一些数据可视化。我们注意到的第一件事是点击量随时间变化。十年前的热门歌曲不一定是今天的热门歌曲。随着时间的推移,当我们将我们的特征形象化时,这就变得明显了:
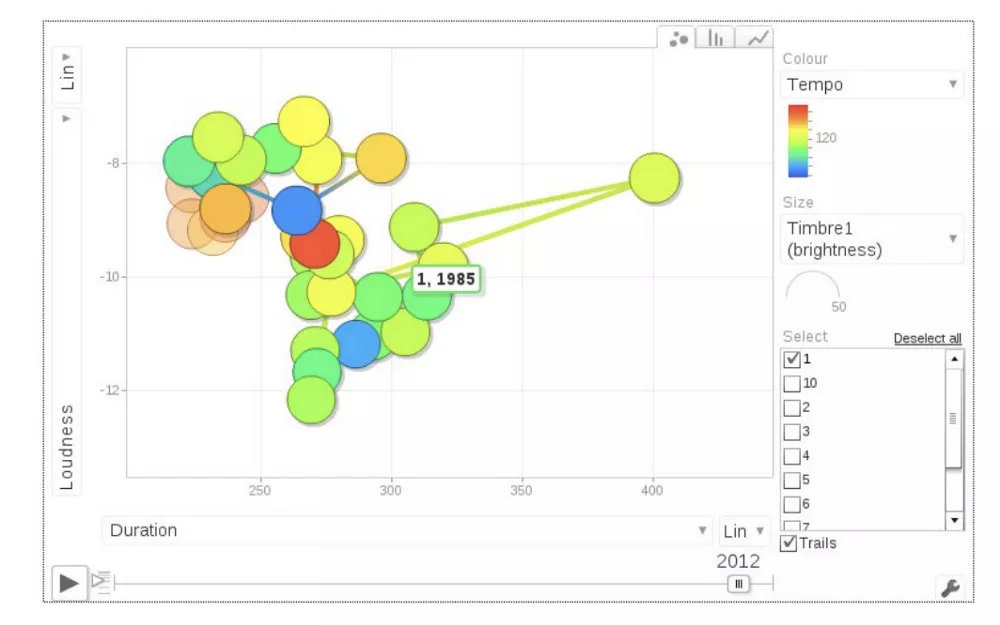 图2 - Herremans等人的交互式气泡图。(2014)
图2 - Herremans等人的交互式气泡图。(2014)
有趣的是,我们看到舞曲的热门歌曲变得更短,更响亮,并且根据EchoNest的“舞蹈”特征,不是那么让人可以跳起舞来!
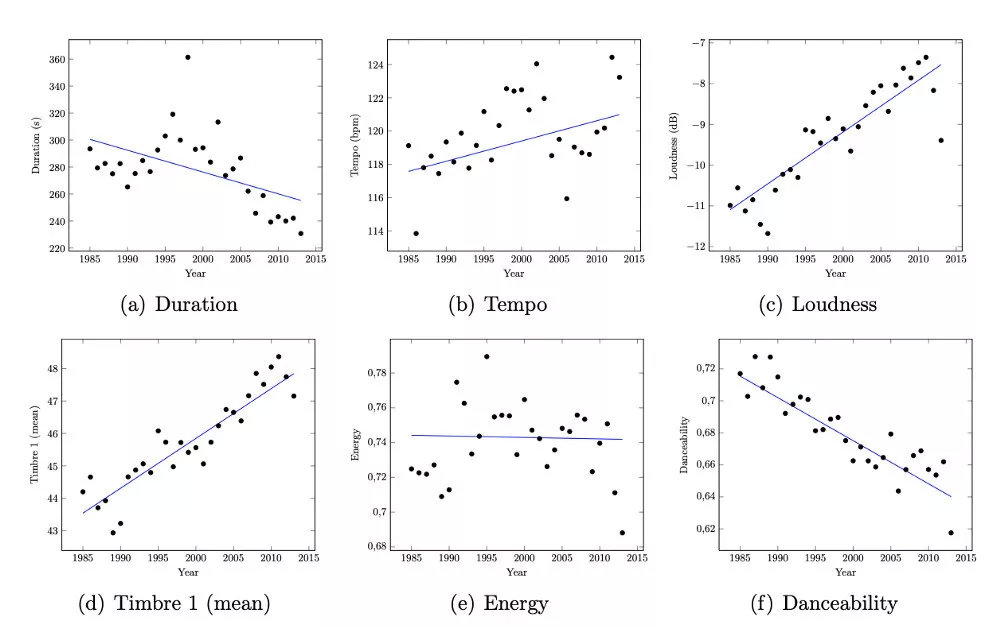 图3 - Herremans等人随时间推移的热门特征的演变(2014年)
图3 - Herremans等人随时间推移的热门特征的演变(2014年)
有关特征完整可视化,请查看我关于可视化热门歌曲的简短文章:
http://dorienherremans.com/sites/default/files/dh_visualiation_preprint_0.pdf
http://musiceye.dorienherremans.com/clustering.html
模型
我们探索了两种类型的模型:可理解模型和黑盒模型。正如预料,后者更有效率,但前者让我们可以深入了解为什么一首歌可以成为热门歌曲。
决策树(C4.5)
为了使决策树适合页面,我将修剪设置为高。这使得树很小且易于理解,但是在D1上的AUC低至0.54。我们看到只有时间特征留下来了!这意味着他们一定很重要。特别是Timbre 3(PCA音色矢量的第三维)反映的重点(锐度),似乎对预测热门歌曲有影响。
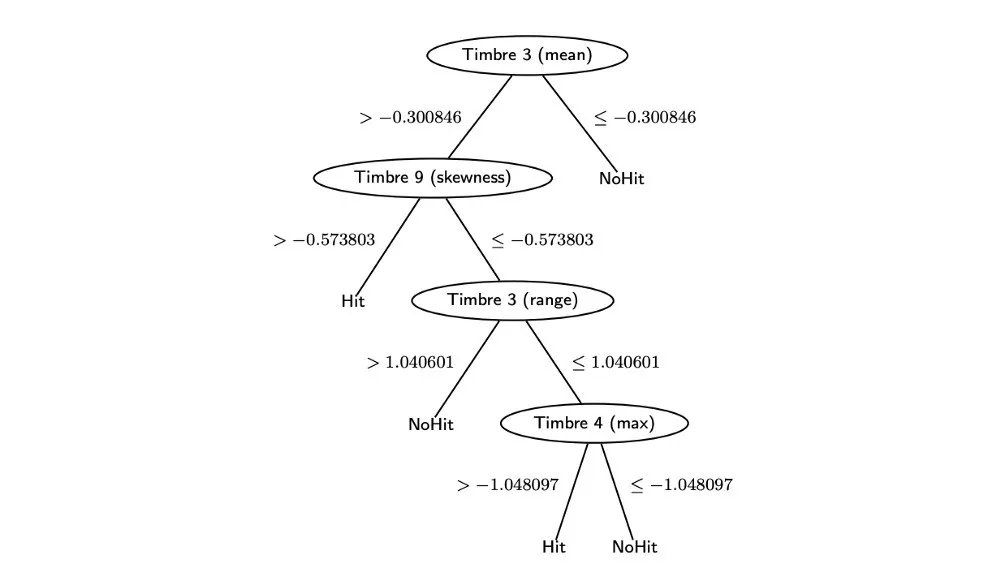 图4 - Herremans等人的决策树(2014年)
图4 - Herremans等人的决策树(2014年)
基于规则的模型
使用RIPPER,可以得到一个与决策树非常相似的规则集。Timbre 3再次出现。这次,我们的AUC在D1上为0.54。
 表3 - Herremans等人的规则集(2014年)
表3 - Herremans等人的规则集(2014年)
朴素贝叶斯,Logistic回归,支持向量机(SVM)
有关这些技术的简单描述,请参阅 Dance Hit Song Prediction
最终结果
在进入结果之前,我应该强调在这里使用一般分类“准确性”是没有意义的,因为这些类是不平衡的(见图1)。如果要使用准确性,则应该是特定于类的。这是一个常见的错误,但要记住这一点非常重要。因此我们使用ROC和AUC和混淆矩阵来正确评估模型。
10折交叉验证
我们获得了数据集1(D1)和数据集2(D2)的最佳结果,没有特征选择(我们在遗传搜索中使用了CfsSubsetEval)。所有特征在训练前都已标准化。由于D3在热门和不热门之间具有最小的“分裂”,因此这种结果是有意义的。总体而言,逻辑回归表现最佳。
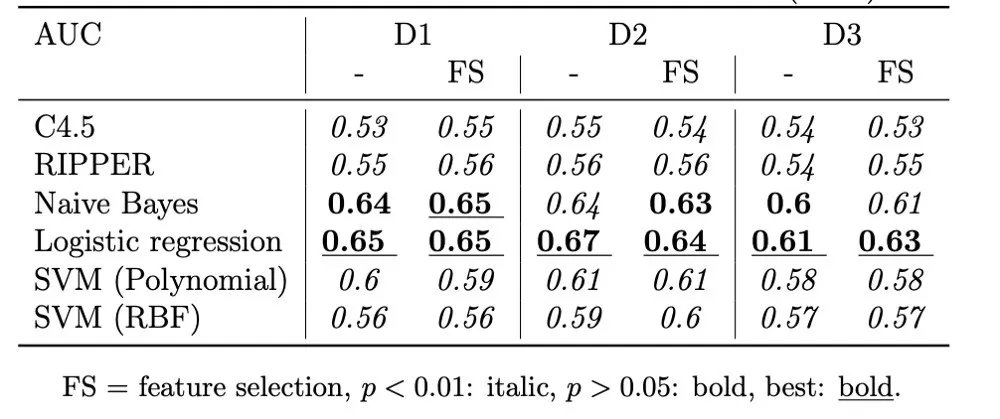 表4 - Herremans等人的 AUC结果(2014年),有/没有特征选择(FS)
表4 - Herremans等人的 AUC结果(2014年),有/没有特征选择(FS)
看下面的ROC曲线,我们看到模型优于随机预言机(对角线)。
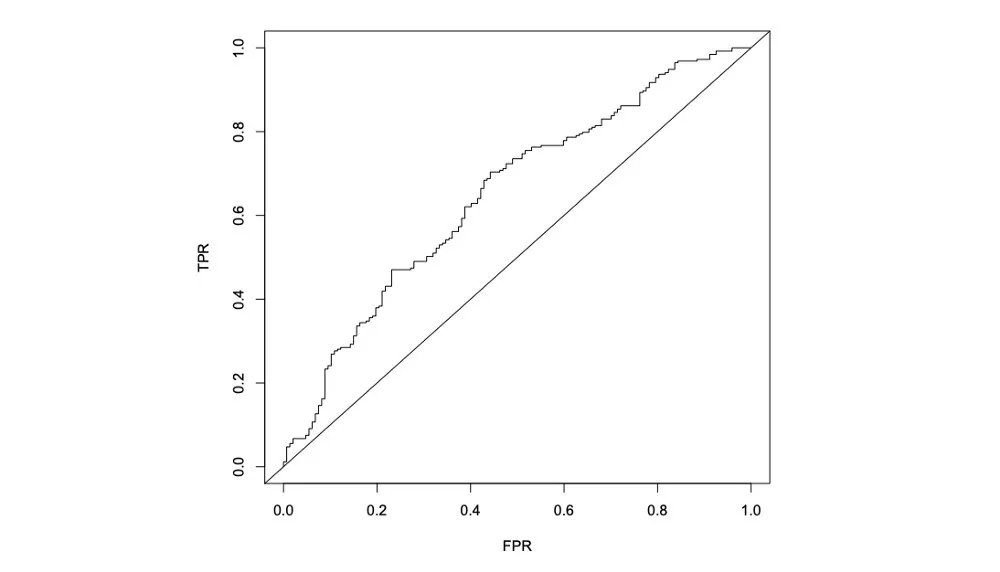 图5 -来自Herremans等人的 Logistic回归的ROC (2014年)
图5 -来自Herremans等人的 Logistic回归的ROC (2014年)
通过查看混淆矩阵可以看出分类准确性的细节,这表明正确识别不热门的歌曲并不容易!但是,热门的正确识别率可达68%。
 表5-来自Herremans等人的 Logistic回归的混淆矩阵(2014年)
表5-来自Herremans等人的 Logistic回归的混淆矩阵(2014年)
超时测试集
我们还使用了按时间顺序排列的“新”歌曲作为测试集,而不是10折交叉验证。这可以让性能进一步提升:
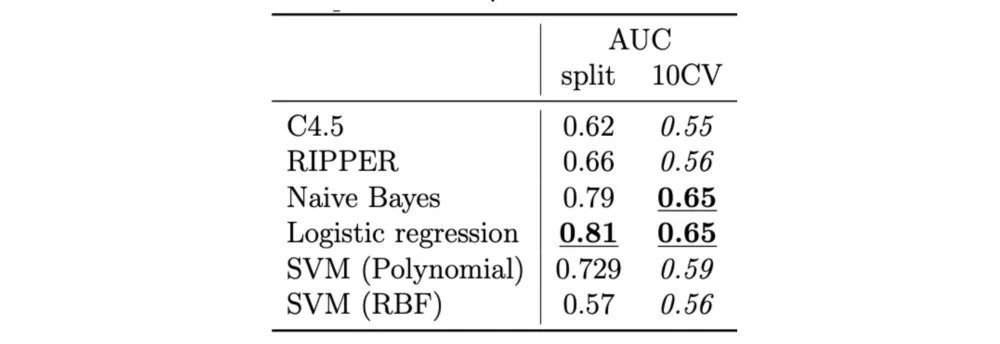 表6-来自Herremans等人的分裂与10倍CV的AUC (2014年)
表6-来自Herremans等人的分裂与10倍CV的AUC (2014年)
有趣的是,该模型可以更好地预测新歌。导致这种偏斜的原因是什么?也许它学会了预测趋势是如何随时间变化的?未来的研究应该着眼于,随着时间的推移音乐偏好的演变。
结论
仅关注音频特征,Dance Hit Song Prediction预测了,如果一首歌的AUC达到80%,将会进入热门歌曲前10名。我们能做得更好吗?可能的!我们在本研究中所看到的特征是有限的,因此要通过使用低级和高级音乐特征来扩展它,可以实现更高的精度。此外,在后续研究中,我研究了社交网络对热门预测产生的重大影响(Herremans&Bergmans,2017)。
相关链接
- Data science for hit song prediction
https://towardsdatascience.com/data-science-for-hit-song-prediction-32370f0759c1
- Dance Hit Song Prediction
https://www.tandfonline.com/doi/abs/10.1080/09298215.2014.881888?casa_token=w0GGhjQd194AAAAA%3AV_YGtWJeIR869x4fYUfyyfFrPiCWhb56ddybPADsO9s9D-k8WaTZI4ADKxgILlufl3UbICsVZEWB5Q&journalCode=nnmr20
参考文献
- Herremans, D., Martens, D., &Sörensen, K. (2014). Dance hit song prediction. Journal of NewMusic Research, 43(3),291–302. [https://arxiv.org/pdf/1905.08076.pdf]
- Herremans, D., & Bergmans, T.(2017). Hit song prediction based on early adopter data and audio features. The18th International Society for Music Information Retrieval Conference (ISMIR)—Late Breaking Demo. Shuzou,China [preprint link]
- Herremans D., Lauwers W.. 2017.Visualizing the evolution of alternative hit charts. The 18th InternationalSociety for Music Information Retrieval Conference (ISMIR)—Late Breaking Demo. Shuzou,China [preprint link]
- Jehan T. and DesRoches D. 2012. EchoNestAnalyzer Documentation, URLdeveloper.echonest.com/docs/v4/_static/AnalyzeDocumentation. pdf
- Pachet, F., & Roy, P. (2008,September). Hit Song Science Is Not Yet a Science. In ISMIR(pp. 355–360).
- Schindler, A., & Rauber, A. (2012,October). Capturing the temporal domain in echonest features for improvedclassification effectiveness. In InternationalWorkshop on Adaptive Multimedia Retrieval (pp. 214–227).Springer, Cham.
作者:Dorien Herremans博士 - dorienherremans.com,新加坡科技与设计大学助理教授,负责人工智能音乐和音频实验室。
本文选自:towardsdatascience
本文转载自:TalkingData数据学堂
封面图来源:pexels by Rene Asmussen
点此阅读英文原文
